这个云数据库RDS是送的,为了了解一下这个RDS的用户,也为了在主机上做一个自动存数据的爬虫,今天开始试用这个RDS。
还是一步一步摸着石头过河。
登录数据库RDS
- 首先从控制台登录
- 进入实例 - mysql 8.0的,20g

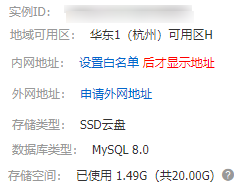
- 内外网白名单设置
先把内网加白名单,按照旁边的帮助我先加了0.0.0.0/0试试,这个默认是内网的主机
外网先点了申请外网地址,然后等一会儿就下来了。
内外网都有网址了。凭着这两个网址,理论上,内外网都可以访问。

- 创建账号,并登录查看


-
下了一个mysql客户端试试,连上了,开始建表,我还是不太习惯在命令行中操作。
下的这个客户端还可以。
-
现在本地python里面连接试试,这需要先装pymysql
pip install pymysql

- 爬虫代码开始编写,这次主要尝试把易车网的车型信息爬下来
url的规律是http://car.bitauto.com/tree_chexing/+type+"_"+id
不过type和id是品牌信息里的,之前爬过一次。
- 导入模块信息
import pymysql
import requests as rq
import re
import bs4
import json
-
数据库连接,还是很简单的
内网填内网地址,外网就填外网,在管控台那里有。

-
从数据库中读取刚填好的信息,篇幅有限,到此为止
爬虫主要用的是requests, BeautifulSoup还在不断练习中。
#从数据库中获取brand信息存到数据字典里
dict_car_brand={}
if bl_get_dict_car_brand is False:
try:
# 执行SQL语句
cursor = db.cursor()
sql="SELECT id,type,name,url FROM car_brand"
cursor.execute(sql)
# 获取所有记录列表
results = cursor.fetchall()
for row in results:
int_id = row[0]
str_type = row[1]
str_name = row[2]
str_url = row[3]
# 加入字典
dict_car_brand[str(int_id)]={"type":str_type,"name":str_name,"url":str_url}
bl_get_dict_car_brand=True
except:
print ("Error: unable to fetch data")
finally:
cursor.close()
#print(dict_car_brand)
