原文链接https://blog.csdn.net/csdnliuxin123524/article/details/81303711
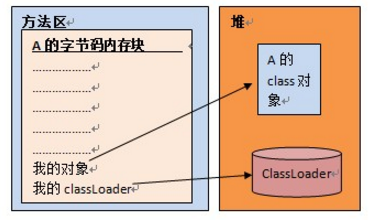
类加载器子系统(class loader subsystem):(1)根据给定的全限定名类名(如java.lang.Object)来装载class文件的内容到Runtimedataarea中的methodarea(方法区域)。Java程序员可以extends java.lang.ClassLoader类来写自己的Classloader。(2) 对(1)中的加载过程是:当一个classloader启动时,classloader的生存地点在jvm中的堆,然后它去主机硬盘上去装载A.class到jvm的methodarea(方法区),方法区中的这个字节文件会被虚拟机拿来new A字节码,然后在堆内存生成了一个A字节码的对象,然后A自己码这个内存文件有两个引用,一个指向A的class对象,一个指向加载自己的classloader。见下图:
执行引擎(Executionengine子系统):(1)负责执行来自类加载器子系统(class loader subsystem)中被加载类中在方法区包含的指令集,通俗讲就是类加载器子系统把代码逻辑(什么时候该if,什么时候该相加,相减)都以指令的形式加载到了方法区,执行引擎就负责执行这些指令就行了。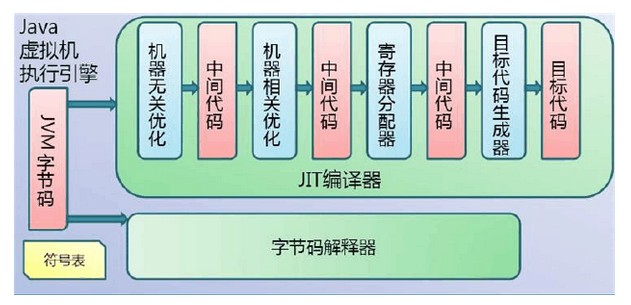
(1)程序在JVM主要执行的过程是执行引擎与运行时数据区不断交互的过程,可理解为上面“方法区中的动图”
(2)但是执行引擎拿到的方法区中的指令还是人能够看懂的,这里执行引擎的工作就是要把指令转成JVM执行的语言(也可以理解成操作系统的语言),最后操作系统语言再转成计算机机器码。
(3)解释器:一条一条地读取,解释并且执行字节码指令。因为它一条一条地解释和执行指令,所以它可以很快地解释字节码,但是执行起来会比较慢。这是解释执行的语言的一个缺点。字节码这种“语言”基本来说是解释执行的。
即时(Just-In-Time)编译器:即时编译器被引入用来弥补解释器的缺点。执行引擎首先按照解释执行的方式来执行,然后在合适的时候,即时编译器把整段字节码编译成本地代码。然后,执行引擎就没有必要再去解释执行方法了,它可以直接通过本地代码去执行它。执行本地代码比一条一条进行解释执行的速度快很多。编译后的代码可以执行的很快,因为本地代码是保存在缓存里的。
简单理解jit就是当代码中某些方法复用次数比较高的,并超过一个特定的值就成为了“热点代码”。那么这个这些热点代码就会被编译成本地代码(其实可以理解成缓存)加快访问速度。
22,本地(native)方法讲解:
(1)本地方法就是带有native标识符修饰的方法;(2)native修饰符修饰的方法并不提供方法体,但因为其实现体是由非java代码在在外部实现的,因此不能与abstract连用;(3)存在的意义:不方便用java语言写的代码,使用更为专业的语言写更合适;甚至有些JVM的实现就是用c编写的,所以只能使用c来写,
(4)更多的本地方法最好是与jdk的执行引擎的解释器语言一致(执行引擎、解释器:参考21的执行引擎);
(5)Windows、Linux、UNIX、Dos操作系统的核心代码大部分是使用C和C++编写,底层接口用汇编编写.
(6)为什么native方法修饰的修饰的方法PC程序计数器为undefined。读懂上面的所有知识点可以就很容易自己理解了。在一开始类加载时,native修饰的方法就被保存在了本地方法栈中,当需要调用native方法时,调用的是一个指向本地方法栈中某方法的地址,然后执行方法直接与操作系统交互,返回运行结果。整个过程并没有经过执行引擎的解释器把字节码解释成操作系统语言,PC计数器也就没有起作用。
23,GC垃圾回收机制:
了解堆内存:
类加载器读取了类文件后,需要把类、方法、常变量放到堆内存中,以方便执行器执行,堆内存分为三部分:

① 新生区
新生区是类的诞生、成长、消亡的区域,一个类在这里产生,应用,最后被垃圾回收器收集,结束生命。新生区又分为两部分:伊甸区(Eden space)和幸存者区(Survivor pace),所有的类都是在伊甸区被new出来的。幸存区有两个:0区(Survivor 0 space)和1区(Survivor 1 space)。当伊甸园的空间用完时,程序又需要创建对象,JVM的垃圾回收器将对伊甸园进行垃圾回收(Minor GC),将伊甸园中的剩余对象移动到幸存0区。若幸存0区也满了,再对该区进行垃圾回收,然后移动到1区。那如果1去也满了呢?再移动到养老区。若养老区也满了,那么这个时候将产生Major GC(FullGCC),进行养老区的内存清理。若养老区执行Full GC 之后发现依然无法进行对象的保存,就会产生OOM异常“OutOfMemoryError”
如果出现java.lang.OutOfMemoryError: Java heap space异常,说明Java虚拟机的堆内存不够。原因有二:
a.Java虚拟机的堆内存设置不够,可以通过参数-Xms、-Xmx来调整。
b.代码中创建了大量大对象,并且长时间不能被垃圾收集器收集(存在被引用)。
③ 永久区
永久存储区是一个常驻内存区域,用于存放JDK自身所携带的 Class,Interface 的元数据,也就是说它存储的是运行环境必须的类信息,被装载进此区域的数据是不会被垃圾回收器回收掉的,关闭 JVM 才会释放此区域所占用的内存。
如果出现java.lang.OutOfMemoryError: PermGen space,说明是Java虚拟机对永久代Perm内存设置不够。原因有二:
a. 程序启动需要加载大量的第三方jar包。例如:在一个Tomcat下部署了太多的应用。
b. 大量动态反射生成的类不断被加载,最终导致Perm区被占满。
24,21运行时数据区各个模块协作工作的总结较好的图(来自:https://blog.csdn.net/wangtaomtk/article/details/52267634)
首先要执行的代码是:
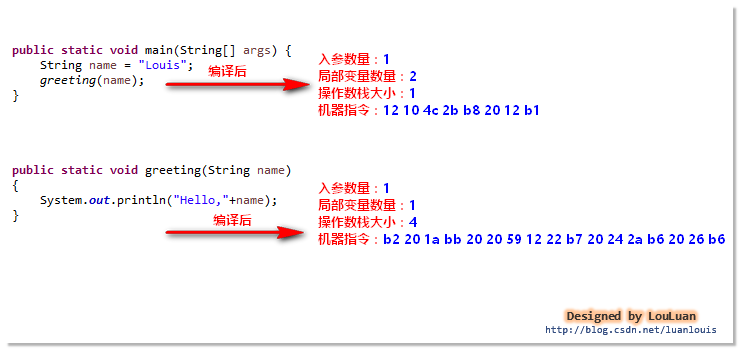
先执行main方法:
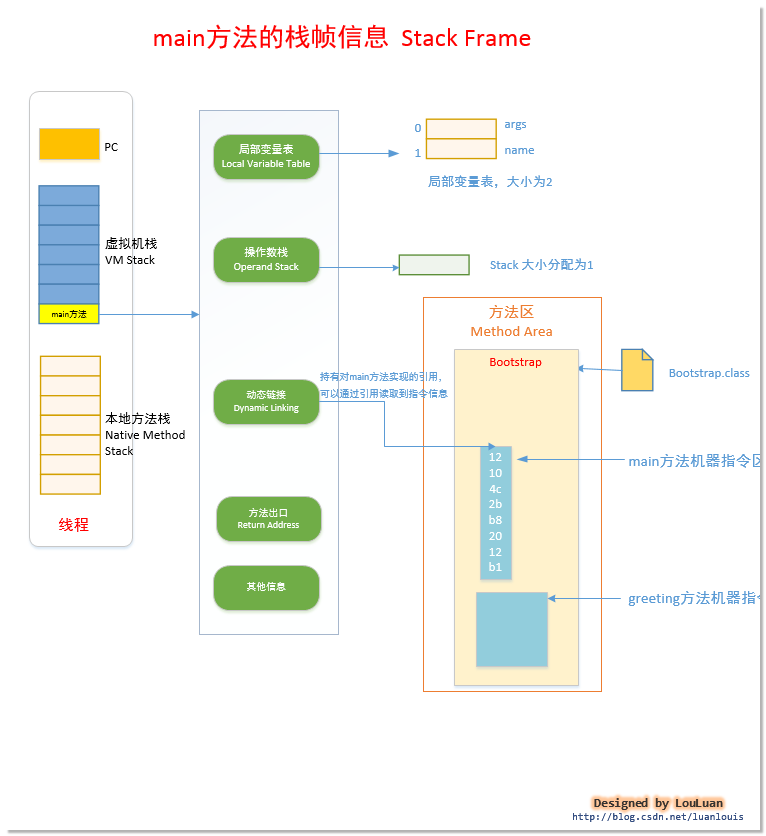
当要调用其他方法时:
27,是先加载字节码文件还是先执行main方法:先加载字节码文件到方法区,然后在找到main执行程序。
28,java被编译成了class文件,JVM怎么从硬盘上找到这个文件并装载到JVM里呢?
是通过java本地接口(JNI),找到class文件后并装载进JVM,然后找到main方法,最后执行。
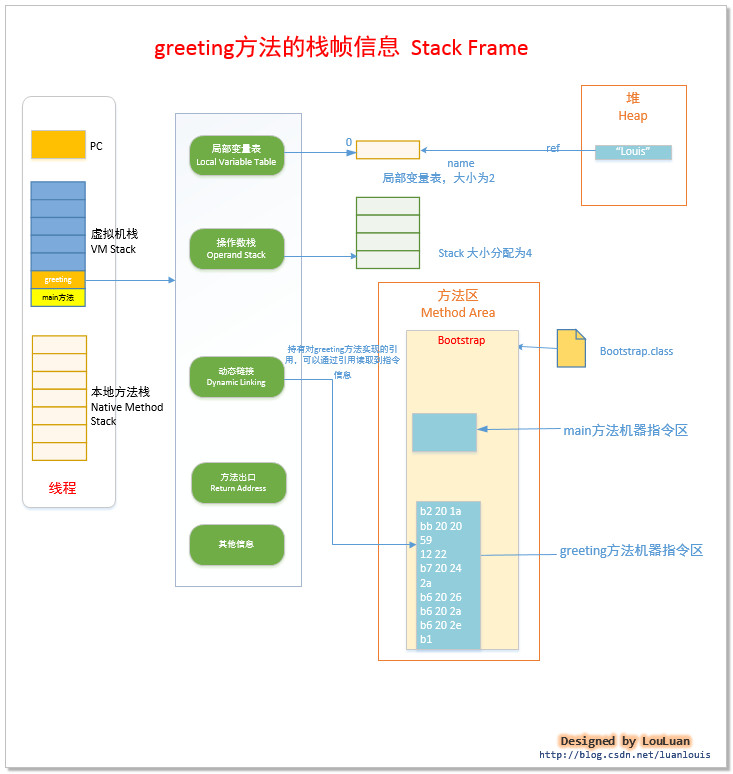
29,我们平时所说的八大基本类型的在栈中的存放位置是:运行时数据区--》虚拟机栈--》虚拟机栈的一个栈帧--》栈帧中的局部变量表;局部变量表存放的数据除了八大基本类型外,还可以存放一个局部变量表的容量的最小单位变量槽(slot)的大小,通常表示为reference;所以是可以放字符串类型的,但是要以 String a="aa";的形式出现,如果是new Object()那就只能实在哎堆中了,栈里面存的是栈执行堆的地址。
30,堆内存大小-Xms -Xmx设置相同,因为-Xmx越大tomcat就有更多的内存可以使用,这就意味着JVM调用垃圾回收机制的频率就会减少(垃圾回收机制被调用是jvm内存不够时自动调用的)可以避免每次垃圾回收完成后JVM重新分配内存。
31,GC具体什么时候执行,这个是由系统来进行决定的,是无法预测的。
32,方法区也被成为堆内存中的永久代,看下面例子:
Student s = new Student("小明",18);
s 是指针,存放在栈中。
new Student("小明",18) 是对象 ,存放在堆中。
Student 类的信息存放在方法区。
总结 :
对象的实例保存在堆上,对象的元数据(instantKlass)保存在方法区,对象的引用保存在栈上。
类加载是会先看方法区有没有已经加载过这个类,因此方法区中的类是唯一的。方法区中的类都是运行时的,都是正在使用的,是不能被GC的,所以可以理解成永久代。
33,方法区的内容是一次把一个工程的所有类信息都加载进去再去执行还是边加载边执行呢?
其实单从性能方面也能猜测到是只加载当前使用的类,也就是边加载边执行。例如我们使用tomcat启动一个spring工程,通常启动过程中会加载数据库信息,配置文件中的拦截器信息,service的注解信息,一些验证信息等,其中的类信息就会率先加载到方法区。但如果我们想让程序启动的快一点就会设置懒加载,把一些验证去掉,如一些类信息的加载等真正使用的时候再去加载,这样说明了方法区的内容可以先加载进去,也可以在使用到的时候加载。