前言
对于哈希表这个结构或许大家都很熟悉,但是很多人都是学完数据机构知道哈希表是怎么个情况,但是没有实际上手去试一下。我就是这样一个人!!今天我看到STL里侯捷老师讲到hash_table的有关知识的时候,我就突然想把这个来实现一下。如果是考研数据结构对于这部分不是很了解也可以看一下,我会把这部分的一个难点讲清楚。
概念
其实哈希表的概念有很多,基本上都是书上现成的内容,我也不再进行copy了。我这里想说的一点就是关于哈希表的查找长度问题。这一次是链表法,所以就针对链表法进行查找长度的计算。下面就来看一下这个应该怎么处理。
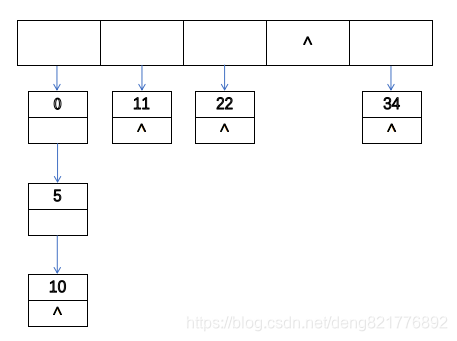
主要是有两种查找长度,一个是查找成功的平均查找长度,另一个是查找不成功的平均查找长度。首先来看查找成功的平均查找长的。
- 查找0,首先使用数组定位到第一个指针处,再向下比较一次得到。所以应该是查找2次;
- 查找5,首先使用数组定位到第一个指针处,再向下比较两次得到。所以应该是查找3次;
- 查找10,首先使用数组定位到第一个指针处,再向下比较三次得到。所以应该是查找4次;
- 查找11,首先使用数组定位到第二个指针处,再向下比较一次得到。所以应该是查找2次;
- 查找22,首先使用数组定位到第三个指针处,再向下比较一次得到。所以应该是查找2次;
- 查找34,首先使用数组定位到第五个指针处,再向下比较一次得到。所以应该是查找2次;
所以全部次数应该是2+3+4+2+2+2,再除以6。但是还要一些人认为第一个位置不应该算比较次数,所以应该是1+2+3+1+1+1,再除以6。其实这个地方大可不必纠结,因为计算机对于这个比较操作多一次少一次并不会影响计算机的性能。对于考研党来说的话,就是针对对应学校的出题方法进行作答。如果没有明确的答案那么就是二者均可。
第二种就是查找不成功的平均查找长度,
- 查找第一个块的不成功长度为4;
- 查找第二个块的不成功长度为2;
- 查找第三个块的不成功长度为2;
- 查找第四个块的不成功长度为1;
- 查找第五块的不成功长度为2;
所以全部次数应该是4+2+2+1+2,再除以5。同样的也有人认为第一个位置不应该算一次。相应的也就减1即可。
具体方法
下面我就针对两个方法进行解释,insert和find。
bool hash_table::insert(const int& val)
{
if (find(val))
{
return true;
}
pNode& point = arr[val % 53];
node* newPoint = new node(val);
pNode _point = nullptr;
if (point == nullptr)
{
point = newPoint;
return true;
}
else
{
_point = point;
}
while (_point->next)
{
_point = _point->next;
}
_point->next = newPoint;
return true;
}
在这里面我采用的是array来存储相应的结点指针。当我们要存入数据时,首先应该判断是否这个元素已经存在。如果存在则认为插入成功,反之则需要进行插入操作。
在这个插入操作的过程中,首先通过hash函数得到相应的数组下标得到链头指针。得到这个指针后,判断指针是否为空,如果为空则把这个指针指向新构建的结点位置。
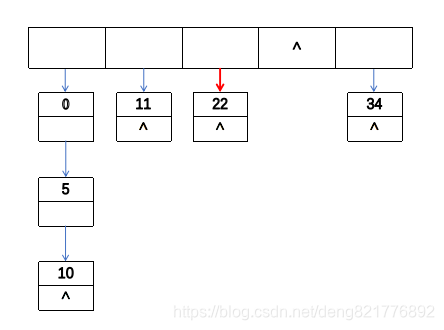
如上面红色这个指针,如果这个是位置的指针不为空,已经存在悬挂元素,则需要找到这一链表的尾结点,将这个尾结点的next指针指向新的结点。这里需要强调的一点是,这个修改这个数组内的指针需要使用引用。否则修改的是指针副本而不是数组内的指针本身
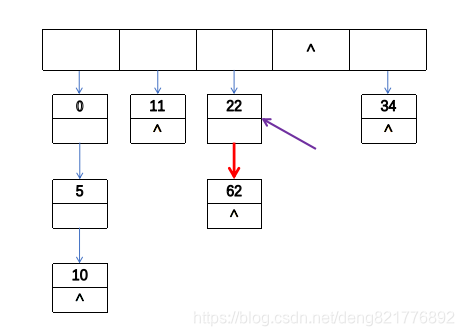
通过循环得到尾结点的指针(紫色箭头表示),然后将新的结点通过next指针悬挂到末尾(红色箭头表示)。这样就是实现插入操作,下面是find操作,find操作比insert操作更加简单。
bool hash_table::find(const int& val)
{
node* point = arr[val % 53];
if (point == nullptr)
{
return false;
}
while (point)
{
if (point->data == val)
return true;
else
{
point = point->next;
}
}
return false;
}
在这个里面首先通过hash得到相应位置的指针,然后通过循环查找是否有目标元素。首先需要判断数组内的对应位置是否为空,如果为空就直接返回false,反之则据需向下查找。当查找到目标元素是直接结束循环返回true,反之则一直向后循环到链表尾部,结束循环然后返回true。
源代码
下面是全部源代码
#pragma once
#include<array>
#include<iostream>
namespace mySpace
{
class hash_table
{
public:
hash_table()
{
for (int i = 0; i < 53; i++)
{
arr[i] = nullptr;
}
}
bool insert(const int& val);
bool find(const int& val);
struct Node {
Node(int val) : data(val), next(nullptr){}
int data;
struct Node *next;
};
typedef struct Node node;
typedef node* pNode;
private:
std::array<node*, 53> arr;
};
bool hash_table::insert(const int& val)
{
if (find(val))
{
return true;
}
pNode& point = arr[val % 53];
node* newPoint = new node(val);
pNode _point = nullptr;
if (point == nullptr)
{
point = newPoint;
return true;
}
else
{
_point = point;
}
while (_point->next)
{
_point = _point->next;
}
_point->next = newPoint;
return true;
}
bool hash_table::find(const int& val)
{
node* point = arr[val % 53];
if (point == nullptr)
{
return false;
}
while (point)
{
if (point->data == val)
return true;
else
{
point = point->next;
}
}
return false;
}
} // namespace mySpace
这需要注意的两点就是:
- 在C++中尽量使用array容器而不是使用int A[10];虽然二者效果类似,但是array容器对于访问越界有控制。而前面的传统的方式对于访问越界没得控制;
- == 在自己写代码的测试的过程中尽量写到一个namespace中,这样可以有效的避免命名变量冲突的问题。 ==
后记
对于这部分的代码我也是想起一出写一处没得什么计划,但愿这个特殊的寒假我能写出更多的博客吧。
