版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/LMengi000/article/details/83029147
学习视频
传送门
哈希表,是既能具备数组的快速查询的优点,又能融合链表方便快捷的增加删除元素的优势。
所谓的hash,简单的说就是散列,即将输入的数据通过hash函数得到一个key值,输入的数据存储到数组中下标的key值的数组单元中去。
哈希函数的构造
哈希函数构造
处理冲突的方式:(着重讲两个)
一、开发定址法:
方法:
令Hi=(H(key)+di)%m,i=1,2,3......,m-1。其中H(key)为哈希函数,m为哈希表长,di为增量序列。
- 若取di=1,2,3....,m-1 ,则称为线性探测再散列 ;
- 若取di=1²,-1²,2²,-2².....,±k² ,则称为二次探测再散列 ;
假设一组关键字{19,01,23,14,55,68,11,82,36},哈希函数为H(key)=key%11(表长11),用线性探测再散列法处理冲突。
根据哈希函数,来计算关键字的地址。
- 若采用线性探测再散列处理冲突 di=1,2,3.....,m-1
- 19%11=8
- 01%11=1
- 23%11=1 (1+1)%11=2
- 14%11=3
- 55%11=0
- 68%11=2 (2+1)%11=3 (2+2)%11=4
- 11%11=0 (0+1)%11=1 (0+2)%11=2 (0+3)%11=3 (0+4)%11=4 (0+5)%11=5
- 82%11=5 (5+1)%11=6
- 36%11=3 (3+1)%11=4 (3+2)%11=5 (3+3)%11=6 (3+4)%11=7
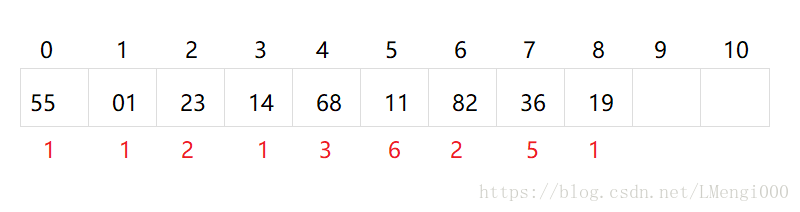
- 若采用二次探测再散列处理冲突 di =1²,-1²,2²,-2².....,±k²
- 19%11=8
- 01%11=1
- 23%11=1 (1+1)%11=2
- 14%11=3
- 55%11=0
- 68%11=2 (2+1)%11=3 (2-1)%11=1 (2+4)%11=6
- 11%11=0 (0+1)%11=1 (0-1)%11=10
- 82%11=5
- 36%11=3 (3+1)%11=4

通过以上两种方法的比较,可以发现用二次探测再散列处理冲突的效率就会高一些。
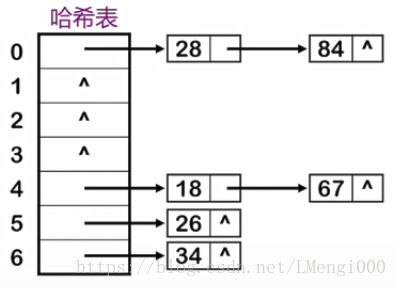
二、链地址法:
设有一组关键字{67,84,18,26,34,28},哈希函数为H(key)=key%7,用链地址法处理冲突 ,
扫描二维码关注公众号,回复:
3700148 查看本文章