文章目录
Overview
Hadoop archives 是特殊的archives格式。一个 Hadoop archive 对应一个文件系统目录。 Hadoop archive 的扩展名是 *.har。Hadoop archive 包含元数据(形式是 _index 和 _masterindx)和数据(part-*)文件。_index 文件包含了archive中文件的文件名和位置信息。
How to Create an Archive
用法: hadoop archive -archiveName name -p <parent> [-r <replication factor>] <src>* <dest>
-archiveName指定了你要创建的archive名字,比如foo.har(正如上面提高的archive文件需要以.har结尾)。
-p <parent> 指定了归档文件的相对路径,例如 -p /foo/bar a/b/c e/f/g 。此处/foo/bar就是a/b/c和e/f/g的父目录。
-r <replication factor>表示的是复制因子,不指定的话默认是10。
注意:创建archive的工作是由MapReduce作业完成的。
如果想归档整个目录如/foo/bar,命令可以写成 hadoop archive -archiveName zoo.har -p /foo/bar -r 3 /outputdir。
如果指定的源文件在加密区域中,那么这些文件将会被解密,并且写入到archive文件中。如果 .har 文件不在加密区(encryption zone)中,则它们存储时不会加密。 如果 .har 文件位于加密区域,则将会以加密形式存储。
How to Look Up Files in Archives
archive是作为一个file system层暴露给用户,只不过是基于hdfs之上。所有的fs shell命令都能在archive里生效,只不过uri是不同于hdfs。另外,archive是无法改变的,即archive里的文件 重命名、删除、创建都会报错。archive的URI是 har://scheme-hostname:port/archivepath/fileinarchive ,如果不设置shecme,则URI是 har:///archivepath/fileinarchive。
这里需要说明的是 scheme是file system的协议,可以参考 org.apache.hadoop.fs.FileSystem#getScheme。如hdfs文件系统的scheme就是hdfs,har文件系统的scheme就是har,本地文件系统的scheme就是file,ftp文件系统的scheme就是ftp。
How to Unarchive an Archive
其实解压只是一个copy的问题,将archive里的文件解压就是将archive里的文件拷贝出来就好。
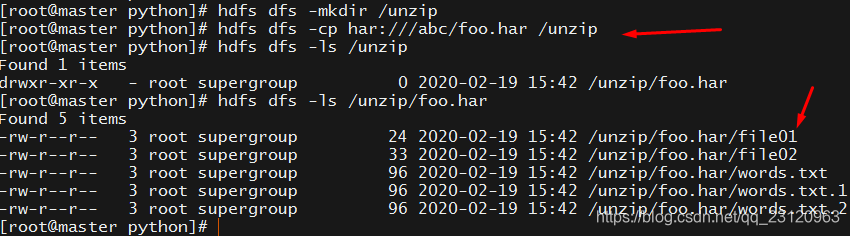
串行解压 hdfs dfs -cp har:///abc/foo.har /unzip 注意 /unzip 目录必须要存在
并行解压 hadoop distcp har:///abc/foo.har /unzip2 ,distcp 是利用MapReduce作业就行数据拷贝的工具

采用distcp拷贝时有个小细节就是 如果 /dest 目录不存在的话,就会创建/dest并直接将archive里的原文件拷贝到所创建的/dest目录里,如上所述。
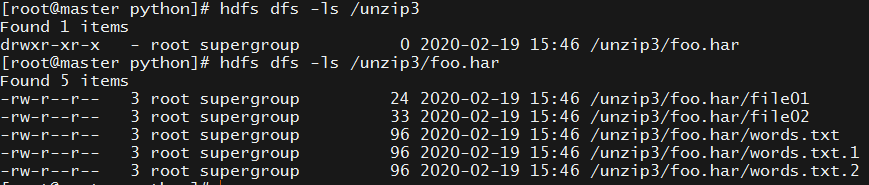
如果是/dest目录已经创建好了,那么会将archive里的原文件放在目录foo.har目录里,然后将foo.har目录放到/dest目录里。如下所示 我已经创建好 /unzip3,然后结果如下
操作Demo
/user/root/input 路径下有如下5个文件
[root@master python]# hdfs dfs -ls /user/root/input
Found 5 items
-rw-r--r-- 3 root supergroup 24 2020-02-16 21:28 /user/root/input/file01
-rw-r--r-- 3 root supergroup 33 2020-02-16 21:28 /user/root/input/file02
-rw-r--r-- 3 root supergroup 96 2020-02-19 11:22 /user/root/input/words.txt
-rw-r--r-- 3 root supergroup 96 2020-02-19 11:22 /user/root/input/words.txt.1
-rw-r--r-- 3 root supergroup 96 2020-02-19 11:22 /user/root/input/words.txt.2
执行 hadoop archive -archiveName foo.har -p /user/root/input /abc 将其archive为 /abc 目录下。如果 /abc 目录不存在的话会自动帮忙创建。执行archive命令后会启动一个MapReduce作业完成archive功能。如下所示
foo.har在hdfs里是作为一个目录存在的。
[root@master python]# hdfs dfs -ls /abc/
Found 1 items
drwxr-xr-x - root supergroup 0 2020-02-19 15:17 /abc/foo.har
进一步查看foo.har目录,如下所示,会看到有元数据文件(_index和_masterindex)及数据文件part-0,另外一个_SUCCESS文件是MapReduce成功后的标志。数据文件part-0就是archive里5个文件(file01,file02,words.txt,words.txt.1,words.txt.2)的合并文件,可以通过cat打印看下就知道了
[root@master python]# hdfs dfs -ls /abc/foo.har
Found 4 items
-rw-r--r-- 3 root supergroup 0 2020-02-19 15:17 /abc/foo.har/_SUCCESS
-rw-r--r-- 5 root supergroup 424 2020-02-19 15:17 /abc/foo.har/_index
-rw-r--r-- 5 root supergroup 23 2020-02-19 15:17 /abc/foo.har/_masterindex
-rw-r--r-- 3 root supergroup 345 2020-02-19 15:17 /abc/foo.har/part-0
那么如何查看archive里的原文件呢?执行hdfs dfs -ls har:///abc/foo.har就能查看
或者 hdfs dfs -ls har://hdfs-master:9000/abc/foo.har
[root@master python]# hdfs dfs -ls har:///abc/foo.har
Found 5 items
-rw-r--r-- 3 root supergroup 24 2020-02-16 21:28 har:///abc/foo.har/file01
-rw-r--r-- 3 root supergroup 33 2020-02-16 21:28 har:///abc/foo.har/file02
-rw-r--r-- 3 root supergroup 96 2020-02-19 11:22 har:///abc/foo.har/words.txt
-rw-r--r-- 3 root supergroup 96 2020-02-19 11:22 har:///abc/foo.har/words.txt.1
-rw-r--r-- 3 root supergroup 96 2020-02-19 11:22 har:///abc/foo.har/words.txt.2
我们知道har文件一旦创建,里面的内容就会新增、重命名、删除等操作,如下所示都会报错
[root@master python]# hdfs dfs -rm -r har:///abc/foo.har/file01
-rm: Wrong FS: har://hdfs-master:9000/abc/foo.har/file01, expected: hdfs://master:9000
Usage: hadoop fs [generic options] -rm [-f] [-r|-R] [-skipTrash] <src> ...
[root@master python]# hdfs dfs -put words.txt har:///abc/foo.har/file01/words.txt.3
put: Har: create not allowed.
[root@master python]# hdfs dfs -mv har:///abc/foo.har/file01 har:///abc/foo.har/file00
mv: Har: rename not allowed
但是如果直接删除foo.har目录里的元数据文件和数据文件那是可以的,上面说的archive创建后不能删除是指的是通过 har 文件系统不能删除,但是可以通过hdfs 文件系统能删除。如下所示我直接拷贝了数据文件放到foo.har目录也是可以的,但是通过har文件系统查看原文件是没有修改的。
root@master python]# hdfs dfs -cp /abc/foo.har/part-0 /abc/foo.har/part-1
[root@master python]# hdfs dfs -ls har://hdfs-master:9000/abc/foo.har
Found 5 items
-rw-r--r-- 3 root supergroup 24 2020-02-16 21:28 har://hdfs-master:9000/abc/foo.har/file01
-rw-r--r-- 3 root supergroup 33 2020-02-16 21:28 har://hdfs-master:9000/abc/foo.har/file02
-rw-r--r-- 3 root supergroup 96 2020-02-19 11:22 har://hdfs-master:9000/abc/foo.har/words.txt
-rw-r--r-- 3 root supergroup 96 2020-02-19 11:22 har://hdfs-master:9000/abc/foo.har/words.txt.1
-rw-r--r-- 3 root supergroup 96 2020-02-19 11:22 har://hdfs-master:9000/abc/foo.har/words.txt.2
[root@master python]# hdfs dfs -ls /abc/foo.har
Found 5 items
-rw-r--r-- 3 root supergroup 0 2020-02-19 15:17 /abc/foo.har/_SUCCESS
-rw-r--r-- 5 root supergroup 424 2020-02-19 15:17 /abc/foo.har/_index
-rw-r--r-- 5 root supergroup 23 2020-02-19 15:17 /abc/foo.har/_masterindex
-rw-r--r-- 3 root supergroup 345 2020-02-19 15:17 /abc/foo.har/part-0
-rw-r--r-- 3 root supergroup 345 2020-02-19 15:33 /abc/foo.har/part-1
[root@master python]#
至于解压archive文件上面的How to Unarchive an Archive已经说的很清楚,没必要重复了。
Hadoop Archives and MapReduce
可以直接将 archive 文件作为MapReduce作业的输入,例如
hadoop jar wordcountV2.jar -Dwordcount.skip.patterns=false har:///abc/foo.har /wdout
该archive文件下面有5个小文件,都是小于block size,所以被分成了5个map task去做。
Hadoop Archives 优缺点总结
优点:
- 由于hdfs不擅长存储小文件,因为每一个小文件就对应着一个block,每个block的元数据都会在NameNode中占用150byte内存。如果存储大量的小文件,它们会占用NameNode节点的大量内存 。hadoop archive将小文件打包成一个har文件,减少了namenode的内存占用,同时也可以透明地访问har文件里的原始小文件。
缺点:
- 打成har文件后,源文件不会自动删除,需要手动删除
- hadoop archive需要依赖MapReduce
- archive本身不支持压缩,且一旦archive就无法更改,如果要增加文件只能重新archive
- archive文件至少需要占用和原始文件一样的空间(还不算上元数据)
- har文件作为MapReduce的输入时,MapReduce作业能访问到har文件里所有的小文件,所以依然是每个小文件对应一个InputSplit,还是会启动很多map task,效率依然不高。
