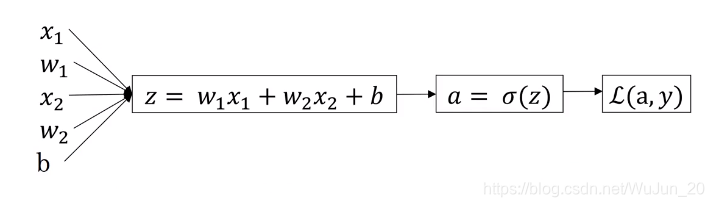2. Loss(erro) Function : L(y^,y)=−ylogy^+(1−y)log(1−y^)
交叉熵损失函数
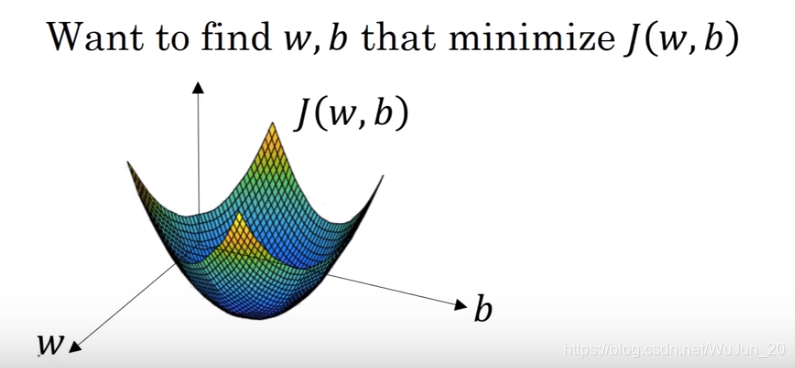
3. Gradient Descent:
J(w,b)=m1i=1∑mL(y^,y(i))
w=w−α∂w∂J(w,b)
b=b−α∂b∂J(w,b)
注:其中alpha为学习率,无论初始值为多少,在不断的迭代中J的值一直往最小值运动
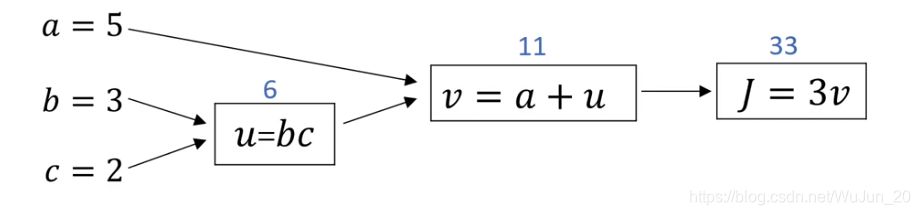
4.Computation Graph
向后传播就是往前求偏导,例如:
∂v∂J(w,b)=3
这就是最后一层的向后传播
5.Logistic Regerssion Derivatives(逻辑斯蒂回归中的梯度下降用法)
da=∂a∂L(a,y)=−ay+1−a1−y
dz=∂a∂L×∂z∂a=(−ay+1−a1−y)×(1−a)a=a−y
dw1=∂w1∂L=x1×dz=x1(a−y)
dw2=∂w2∂L=x1×dz=x2(a−y)
db=dz
w1=w1−α×dw1
w2=w2−α×dw2
b=b−α×db
从上到下的计算就是一轮两个特征的梯度下降的迭代
5. numpy的应用 输入V,求U(其中V为向量,及在普通的math库里面需要用到for循环)
v=[v1...vn]T
u=[eV1...eVn]T
#伪代码不要直接运行import numpy
#用到numpy里面的函数,很好的计算了向量的运算,及省去了for循环带来的时间损耗
u=np.exp(v)#for loop
u = np.zero((n,1))for i inrange(n):
u[i]= math.exp(v[i])#这样在梯度下降更行w_i的时候可以用numpy里的函来简化for循环
dw = np.zero(n_x,1)
dw += X*dZ
dw /= n
#这就是对前面需要for循环的优化#向量化后的logistic回归梯度输出,伪代码!
Z = np.dot(w^T,x)+b
#plus b :python's broadcasting
A = sigmod(Z)
dZ = A - Y
dw =1/m * X * dZ^T
db =1/m * np.sum(dZ)
w = w - alpha * dw
b = b - alpha * db