1、常见的选择器:
#test表示id为test的DOM节点
.aaron 表示class为aaron的DOM节点
nav>li 表示在nav内部子li的样式,而不是所有的后代元素,只是往下一层li的样式。
nav+p 表示nav类相邻的p元素的属性,其他的p元素不受影响。
nav[title] 表示nav的title属性的样式。
nav[rel='active'] 表示nav类的属性rel为active的元素样式。
其实最终都是通过浏览器提供的接口实现的:
获取id为test的DOM节点:
document.getElementById(“test”)
获取节点名为input的DOM节点:
document.getElementsByTagName(“input”)
获取属性name为checkbox的DOM节点:
document.getElementsByName(“checkbox”)
高级的浏览器还提供:
document.getElementsByClassName
document.querySelector
document.querySelectorAll
由于低级浏览器并未提供这些高级点的接口,所以才有了Sizzle这个CSS选择器引擎。Sizzle引擎提供的接口跟document.querySelectorAll是一样的,其输入是一串选择器字符串,输出则是一个符合这个选择器规则的DOM节点列表。
2、Sizzle引擎解析 CSS 选择器的方向是从右向左
在建立 Render Tree 时(这里可以观看我的博客从输入URL到页面加载完成的过程,看浏览器的工作原理),浏览器就要为每个 DOM Tree 中的元素根据 CSS 的解析结果(Style Rules)来确定生成怎样的 renderer。对于每个 DOM 元素,必须在建立的规则索引树找到符合的 selector 并将对应的规则进行合并。选择器的「解析」实际是在这里执行的,在遍历 DOM Tree 时,从 规则索引树 中去寻找对应的 selector。
- 如果正向解析,例如「div div p em」,我们首先就要检查当前元素到 html 的整条路径,找到最上层的 div,再往下找,如果遇到不匹配就必须回到最上层那个 div,往下再去匹配选择器中的第一个 div,回溯若干次才能确定匹配与否,效率很低。
- 逆向匹配则不同,如果当前的 DOM 元素是 div,而不是 selector 最后的 em,那只要一步就能排除。只有在匹配时,才会不断向上找父节点进行验证。
简单的来说浏览器从右到左进行查找的好处是为了尽早过滤掉一些无关的样式规则和元素。采用right -> left的顺序是有前提条件的:没有位置关系的约束。例外:

结论: 从性能触发,采取从右到左; 为了准确性,对位置伪类,只能采取从左到右。
3、Sizzle引擎解析机制
就拿javascript而言,解析过程可以分为预编译与执行两个阶段。在预编译的时候通过词法分析器与语法分期器的规则处理,
在词法分析过程中,js解析器要下把脚本代码的字符流转换成记号流。把代码解析成Token的阶段在编译阶段里边称为词法分析。
比如:
a=(b-c);
解析后转换成:
NAME "a" EQUALS OPEN_PARENTHESIS NAME "b" MINUS NAME "c" CLOSE_PARENTHESIS SEMICOLON
CSS选择器其实也就是一段字符串,我们需要分析出这个字符串背后对应的规则,在这里Sizzle用了简单的词法分析。代码经过词法分析后就得到了一个Token序列,紧接着拿Token序列去其他事情。所以在Sizzle中专门有一个tokenize处理器干这个事情。
Sizzle的Token格式如下 :
Token:{ value:'匹配到的字符串', type:'对应的Token类型', matches:'正则匹配到的一个结构' }
这样拿到匹配后的结构Token就去干别的相关处理了!
Sizzle是jQuery作者John Resig新写的DOM选择器引擎,速度号称业界第一.Sizzle完全独立于jQuery,若不想用jQuery,你可只用Sizzle实现,压缩3K多http://url.cn/J73IkN
4、Sizzle引擎的解析函数tokenize的源码分析
因为在tokenize函数的源码中,调用了Expr.preFilter方法,Expr.preFilter是tokenize方法中对ATTR、CHILD、PSEUDO三种选择器进行预处理的方法。所以我们先看Expr.preFilter的源码:
preFilter方法定义在Expr = Sizzle.selectors = {}中;
//预处理,有的选择器,比如属性选择器与伪类从选择器组分割出来,还要再细分
//属性选择器要切成属性名,属性值,操作符;伪类要切为类型与传参;
//子元素过滤伪类还要根据an+b的形式再划分
preFilter: {
//属性选择器
/*
* 完成如下任务:
* 1、属性名称解码
* 2、属性值解码
* 3、若判断符为~=,则在属性值两边加上空格
* 4、返回最终的mtach对象
*
* match[1]表示属性名称,
* match[1].replace(runescape, funescape):将属性名称中的十六进制数解码成
* 单字节unicode字符或双字节unicode字符(中文或其它需要两个字节表达的文字)
*/
"ATTR": function(match) {
match[1] = match[1].replace(runescape, funescape);
// Move the given value to match[3] whether quoted or unquoted
/*
* 将属性值解码
* match[4]:表示放在单引号或双引号内的属性值
* match[5]: 表示不用引号括起来的属性值
*/
match[3] = (match[4] || match[5] || "").replace(runescape, funescape);
/*
* ~=的意思是单词匹配,在W3C中对单词的定义是以空白为不同单词的分隔符
* 故此处在match[3]两边加上空格后,可以利用indexOf,正确识别出该单词是否存在
*/
if (match[2] === "~=") {
match[3] = " " + match[3] + " ";
}
/*
* 返回有用的前四个元素结果
*/
return match.slice(0, 4);
},
//对伪类选择器进行预处理
"CHILD": function(match) {
//将它的伪类名称与传参拆分为更细的单元,以数组形式返回
//比如 ":nth-child(even)"变为
//["nth","child","even", 2, 0, undefined, undefined, undefined]
/* matches from matchExpr["CHILD"]
1 type (only|nth|...)
2 what (child|of-type)
3 argument (even|odd|\d*|\d*n([+-]\d+)?|...)
4 xn-component of xn+y argument ([+-]?\d*n|)
5 sign of xn-component
6 x of xn-component
7 sign of y-component
8 y of y-component
*/
/*
* 完成如下几项任务:
* 1、把命令中child和of-type之前的字符变成小写字符
* 2、对于nth开头的选择器检查括号内的数据有效性
* 3、match[4]和match[5]分别存放xn+b中的x和b,x和b允许是负数
* 4、返回最终的match对象
*
* match[1]:(only|first|last|nth|nth-last)中的一个
*/
match[1] = match[1].toLowerCase();//match[0]为冒号:
/*
* 对于nth-child、nth-of-type、nth-last-child、nth-last-of-type四种类型括号内需设置有效数据
* 而其它则括号内不允许有任何数据
*/
if (match[1].slice(0, 3) === "nth") {
// nth-* requires argument
/*
* 若选择器括号内没有有效参数,则抛出异常
* 举例:若选择器是nth或nth(abc)则属于非法选择器
*/
if (!match[3]) {
Sizzle.error(match[0]);
}
// numeric x and y parameters for Expr.filter.CHILD
// remember that false/true cast respectively to 0/1
/*
* 下面先以nth-child()为例介绍一下语法,以便更好的理解下面代码的作用
* nth-child允许的几种使用方式如下:
* :nth-child(even)
* :nth-child(odd)
* :nth-child(3n)
* :nth-child(+2n+1)
* :nth-child(2n-1)
* 下面代码中赋值号左侧的match[4]、match[5]用于分别记录括号内n前及n后的数值,包括正负号
* 对于:nth-child(even)和:nth-child(odd)来说,match[4]为空,
* 所以返回 2 * (match[3] === "even" || match[3] === "odd")的计算结果
* 因为在js中true=1,false=0,所以(match[3] === "even" || match[3] === "odd")等于1
* 因此,2 * (match[3] === "even" || match[3] === "odd")的计算结果为2
*
* 等号右侧的“+”的作用是强制类型转换,将之后的字符串转换成数值类型
*/
match[4] = +(match[4] ? match[5] + (match[6] || 1) :
2 * (match[3] === "even" || match[3] === "odd"));
match[5] = +((match[7] + match[8]) || match[3] === "odd");
// other types prohibit arguments
} else if (match[3]) {
/*
* 若非nth起头的其它CHILD类型选择器带有括号说明,则抛出异常
* 这里jQuery并没有严格按照W3C的规则来判定,因为其允许:first-child()的这种形式存在
* 也就是对于jQuery来说:first-child()等同于:first-child,是合法选择器
*/
Sizzle.error(match[0]);
}
return match;
},
"PSEUDO": function(match) {
//将它的伪类名称与传参进行再处理
//比如:contains伪类会去掉两边的引号,反义伪类括号部分会再次提取
/*
* 完成如下任务:
* 1、获取伪类中用引号括起来的值
* 2、对于非引号括起来的值,若存在伪类嵌套,则进一步解析确定当前伪类实际结束位置,
* 获取当前伪类的完整字符串和值
* 3、返回match中的前三项的副本。
*
* unquoted表示括号内非引号括起来的值,
* 以:eq(2)为例,unquoted=2
*/
var excess,
unquoted = !match[5] && match[2];
/*
* 因为pseudo与child的匹配正则表达式有交集,所以,需要把属于child的部分忽略掉
*/
if (matchExpr["CHILD"].test(match[0])) {
return null;
}
// Accept quoted arguments as-is
/*
* 若括号内的值使用引号(match[3])括起来的,
* 则将除引号外的值(match[4])赋给match[2]。
* match[3]表示引号。
*/
if (match[3] && match[4] !== undefined) {
match[2] = match[4];
// Strip excess characters from unquoted arguments
} else if (unquoted
/*
* rpseudo.test(unquoted):用来测试unquoted是否包含伪类,
* 若包含伪类,则说明有可能存在伪类嵌套的可能性,需要进一步对unquoted进行解析
* 例如: :not(:eq(3))
*/
&& rpseudo.test(unquoted)
&&
// Get excess from tokenize (recursively)
/*
* 获取unquoted中连续有效地选择器最后一个字符所在位置
*/
(excess = tokenize(unquoted, true))
&&
// advance to the next closing parenthesis
/*
* unquoted.indexOf(")", unquoted.length - excess)
* 从之前获得的连续有效地选择器最后一个字符所在位置之后找到")"所在位置,
* 通常就在当前位置之后。
* 再减去unquoted.length,用来获得match[0]中的有效完整的伪类字符串最后位置,
* 注意,此时excess是一个负值
*
*/
(excess = unquoted.indexOf(")", unquoted.length - excess) - unquoted.length)) {
// excess is a negative index
// 获取有效的完整伪类match[0]和伪类括号内的数据match[2]
match[0] = match[0].slice(0, excess);
match[2] = unquoted.slice(0, excess);
}
// Return only captures needed by the pseudo filter method (type and argument)
// 返回match前三个元素的副本
return match.slice(0, 3);
}
},
tokenize函数的源码:
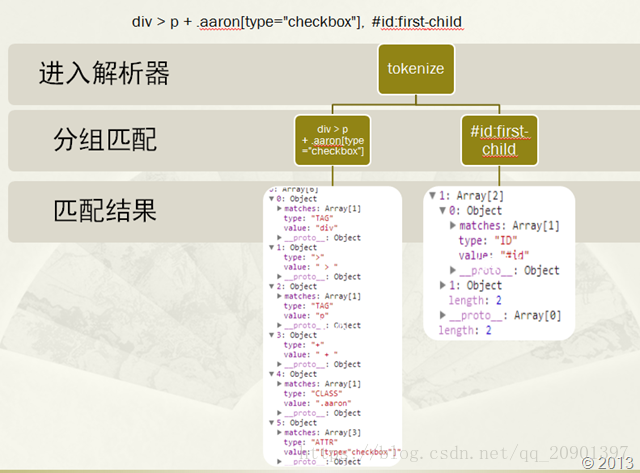
//假设传入进来的选择器是:div > p + .aaron[type="checkbox"], #id:first-child
//这里可以分为两个规则:div > p + .aaron[type="checkbox"] 以及 #id:first-child
//返回的需要是一个Token序列
//Sizzle的Token格式如下 :{value:'匹配到的字符串', type:'对应的Token类型', matches:'正则匹配到的一个结构'}
/*
tokenize方法完成如下两个主要任务:
* 1、解析选择器
* 2、将解析结果存入缓存中,以备后用
*/
/*
* @param selector 待解析的选择器字符串
* @param parseOnly 为true时,说明本次调用是匹配子选择器
* 举个例子:若初始选择器为"div:not(.class:not(:eq(4))):eq(3)"
* 代码首先匹配出TAG选择器div,
* 之后匹配出的pseudo选择器字符串是:not(.class:not(:eq(4))):eq(3),
* 代码会把“.class:not(:eq(4))):eq(3”作为not的括号内的值进一步进行解析,
* 此时代码在调用tokenize解析时,parseOnly参数会传入true.
*/
function tokenize(selector, parseOnly) {
var matched, match, tokens, type,
soFar, groups, preFilters,
cached = tokenCache[selector + " "];
//这里的soFar是表示目前还未分析的字符串剩余部分
//groups表示目前已经匹配到的规则组,在这个例子里边,groups的长度最后是2,存放的是每个规则对应的Token序列
//如果cache(缓存)里边有,直接拿出来即可
if (cached) {
// 若是对初始选择器解析(parseOnly!=true),则返回缓存结果,
// 若不是(只解析初试选择器的子选择器),则返回0
return parseOnly ? 0 : cached.slice(0);
}
//初始化
soFar = selector;//刚开始,未分析的是整个字符串
groups = []; //这是最后要返回的结果,一个二维数组
//比如"title,div > :nth-child(even)"解析下面的符号流
// [ [{value:"title",type:"TAG",matches:["title"]}],
// [{value:"div",type:["TAG",matches:["div"]},
// {value:">", type: ">"},
// {value:":nth-child(even)",type:"CHILD",matches:["nth",
// "child","even",2,0,undefined,undefined,undefined]}
// ]
// ]
//有多少个并联选择器,里面就有多少个数组,数组里面是拥有value与type的对象
//这里的预处理器为了对匹配到的Token适当做一些调整
//正则匹配到的内容的一个预处理,此处赋值,仅仅用于减少后续代码字数,缩短执行路径
preFilters = Expr.preFilter;
//递归检测字符串x
//比如"div > p + .clr input[type="checkbox"]"
while (soFar) {
// Comma and first run
// 以第一个逗号切割选择符,然后去掉前面的部分
/*
* rcomma = new RegExp("^" + whitespace + "*," + whitespace + "*")
* rcomma用来判定是否存在多个选择器块,即用逗号隔开的多个并列的选择器
*下面条件判定依次为:
* !matched:若是第一次执行循环体,则为true;否则为false。
* 这里matched即作为是否第一次执行循环体的标识,
* 也作为本次循环中soFar是否以非法字符串(即非合法单一选择器)开头的标志。
* (match = rcomma.exec(soFar):获取符合rcomma的匹配项
*/
if (!matched || (match = rcomma.exec(soFar))) {
if (match) {
//如果匹配到逗号
// Don't consume trailing commas as valid
/*
* 剔除掉第一个逗号及之前的所有字符
* 举个例子:
* 若初始选择器为:"div.news,span.closed",
* 在解析过程中,首先由后续代码解析完毕div.news,剩下",span.closed"
* 在循环体内执行到这里时,将逗号及之前之后连续的空白(match[0])删除掉,
* 使soFar变成"span.closed",继续执行解析过程
*
* 在这里,若初始选择器的最后一个非空白字符是逗号,
* 那么执行下面代码时soFar不变,即soFar.slice(match[0].length)返回空字符串,
* 故最终返回的是||后面的soFar
*/
soFar = soFar.slice(match[0].length) || soFar;
}
//在第一次执行循环体或者遇到逗号分割符时,往规则组里边压入一个Token序列,目前Token序列还是空的
groups.push(tokens = []);
}
matched = false;
// Combinators
//将刚才前面的部分以关系选择器再进行划分
//先处理这几个特殊的Token : >, +, 空格, ~
//因为他们比较简单,并且是单字符的
/*
* rcombinators = new RegExp(
* "^" + whitespace + "*([>+~]|" + whitespace + ")" + whitespace + "*"),
* rcombinators用来匹配四种关系符,即>+~和空白
*
* 若soFar中是以关系符开始的,则执行if内的语句体
*/
if ((match = rcombinators.exec(soFar))) {
//获取到匹配的字符
/*
* 将match[0]移除match数组,同时将它赋予matched
* 若原本关系符两边带有空格,则此时match[0]与matched是不相等的
* 举个例子:
* 若soFar = " + .div";
* 执行match = rcombinators.exec(soFar)后,
* match[0] = " + ",而match[1]="+";
* 执行完matched = match.shift()后,
* matched=" + ",而match[0]="+";
*/
matched = match.shift();
//放入Token序列中
tokens.push({
value: matched,
// Cast descendant combinators to space
/*
* rtrim = new RegExp("^" + whitespace + "+|((?:^|[^\\\\])(?:\\\\.)*)"
* + whitespace + "+$", "g"),
* whitespace = "[\\x20\\t\\r\\n\\f]";
*
* 下面match[0].replace(rtrim, " ")的作用是将match[0]左右两边的空白替换为空格
* 但是由于其上的match.shift的作用,match[0]已经是两边不带空白的字符串了,
* 故此出的替换是没有用途的代码
*/
type: match[0].replace(rtrim, " ")
});
//剩余还未分析的字符串需要减去这段已经分析过的
soFar = soFar.slice(matched.length);
}
// Filters
/*
* 下面通过for语句对soFar逐一匹配ID、TAG、CLASS、CHILD、ATTR、PSEUDO类型的选择器
* 若匹配到了,则先调用该类型选择器对应的预过滤函数,
* 然后,将结果压入tokens数组,继续本次循环。
*/
//Expr.filter里边对应地 就有ID,TAG,CLASS,ATTR,CHILD,PSEUDO这些key(在matchExpr 过滤正则)
//如果通过正则匹配到了Token格式:match = matchExpr[ type ].exec( soFar )
//然后看看需不需要预处理:!preFilters[ type ]
//如果需要 ,那么通过预处理器将匹配到的处理一下 : match = preFilters[ type ]( match )
for (type in Expr.filter) {
if ((match = matchExpr[type].exec(soFar)) && (!preFilters[type] ||
(match = preFilters[type](match)))) {
matched = match.shift();
//放入Token序列中
tokens.push({
value : matched,
type : type,//通过正则匹配出来的类型
matches: match
});
//剩余还未分析的字符串需要减去这段已经分析过的
soFar = soFar.slice(matched.length);
}
}
//如果到了这里都还没matched到,那么说明这个选择器在这里有错误
//直接中断词法分析过程
//这就是Sizzle对词法分析的异常处理
if (!matched) {
break;
}
}
// Return the length of the invalid excess
// if we're just parsing
// Otherwise, throw an error or return tokens
//放到tokenCache函数里进行缓存
/*
* 若不是对初始选择器字符串进行解析(!parseOnly==true),
* 则返回soFar.length,此时的soFar.length代表连续有效的选择器最终位置,
* 后续文章将以实例进行说明
* 若是对初始选择器字符串进行解析,则看soFar是否还有字符,
* 若是,则执行Sizzle.error(selector)抛出异常;
* 若不是,则执行tokenCache(selector, groups).slice(0)将把groups记录在cache里边并返回。
*/
return parseOnly ?
soFar.length :
soFar ?
Sizzle.error(selector) :
// Cache the tokens
tokenCache(selector, groups).slice(0);
}
分析过程如图所示: