学习了几天如何使用scrapy去爬取静态网站,今天尝试去爬取动态加载的网站。选取的网站是华尔街见闻,文中不会像往常一样大篇幅讲解每一步该如何做,而是探讨如何爬取。
在源代码中无法获得全部数据(有的根本没数据),但是通过下拉滑条可以看到网址不变但有数据加载出来,毫无疑问这就是动态加载的网页。以下讲解如何去寻找api接口取获取数据。
打开开发者工具,选择Network,刷新,选择XHR,如图。
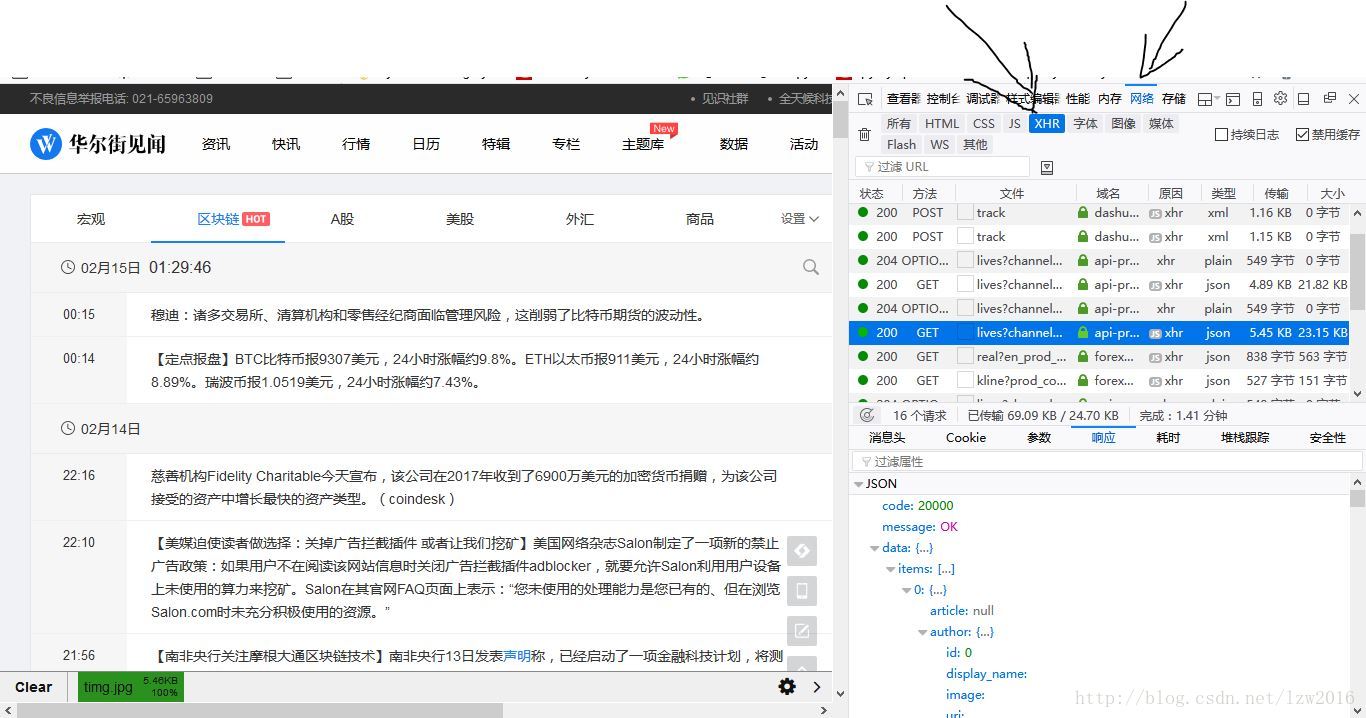
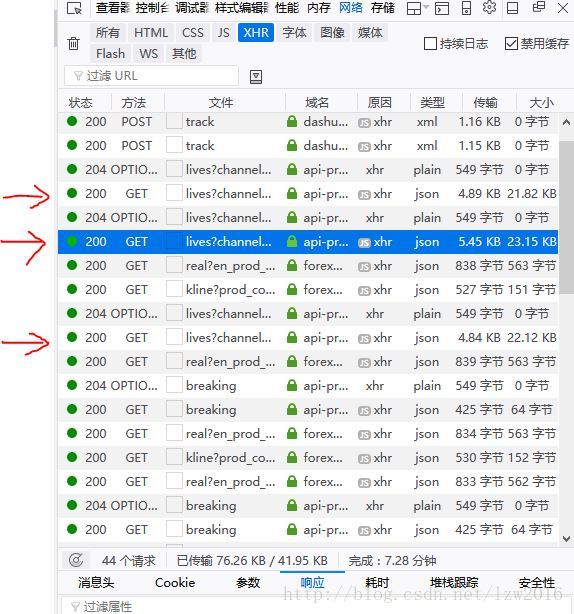
你可以从头开始一个个点击,查看响应(响应是指如下图的工具台上的响应)是否是你想要的数据。要么就滑动滑条,看看新的请求中名字是否有类似的请求,一般就是。
这里我们针对区块链数据,如图:
然后我们查看消息头的url,如‘https ://api-prod.wallstreetcn.com/apiv1/content/lives?channel=blockchain-channel&client=pc&cursor=1518567654&limit=20’,
请求的参数有:
channel=blockchain-channel
client=pc
cursor=1518567654
limit=20在浏览器中打开这个url,待定系数法删除某个参数,看看哪些是必须的。
由此可以猜测
limit=20应该是限制请求数据条数,可删;
client=pc字面意思应该是pc端;
channel=blockchain-channel这可能是指区块链相关数据,不可删;
cursor=1518567654初步怀疑要么在页面中,要么是上一个页面加载时附带的信息,查找后没找到。怀疑可能是时间戳,time模块验证果真是当前时间。可删,但实验后发现没有cursor最多可加载99条数据。
这只是针对区块链一个版块,其他都类似寻找即可,但找寻过程中发现了一个api提供和所有的数据。接口:https://api-prod.wallstreetcn.com/apiv1/content/lives/pc?limit=40
浏览器打开,最好装一个json相关的插件,方便查看数据。如图
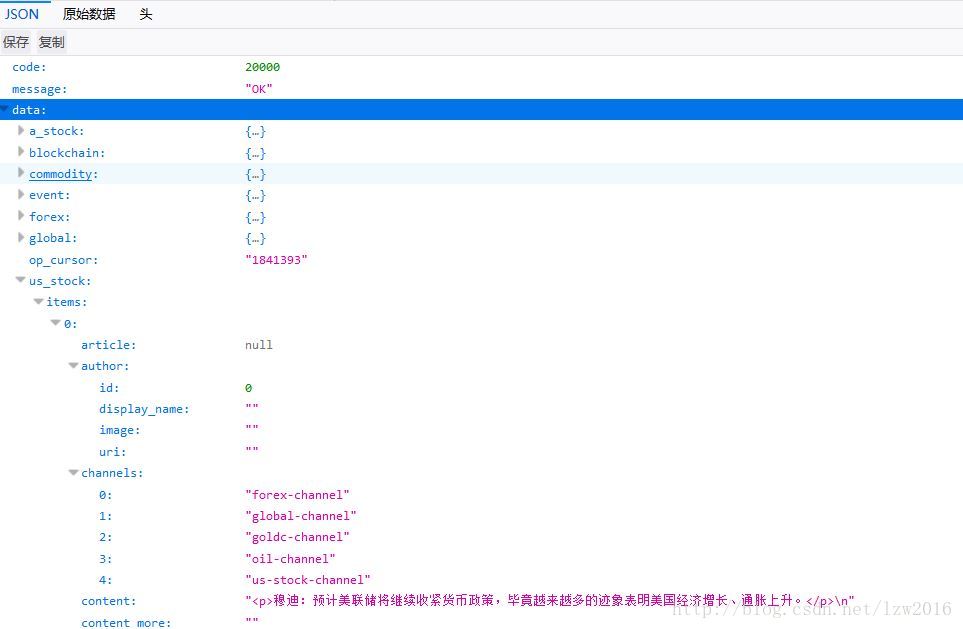
看英文就能知道global,blockchain,a_stock,us_stock,forex ,commodity分别对应分为六大板块:宏观,区块链,A股,美股,外汇,商品。
就是这样的
再附上资讯的接口api:
看清了这是代码别直接粘贴了
'https://api-prod.wallstreetcn.com/apiv1/content/articles?category={}&limit=20&platform=wscn-platform'.format(p) for p in
['global','shares','commodities','china','us','europe','japan','charts','economy']limit参数可人为控制,还有就是cursor参数。你能发现他返回的数据中带有display_time,next_cursor这样的数据,后者结合limit可访问下一时间段的数据。你自己指定当前时间戳到某一时间戳之间也没问题。