理解数据仓库中星型模型和雪花模型
原创三劫散仙 最后发布于2017-07-06 18:32:27 阅读数 18910 收藏
展开
在数据仓库的建设中,一般都会围绕着星型模型和雪花模型来设计表关系或者结构。下面我们先来理解这两种模型的概念。
(一)星型模型图示如下:
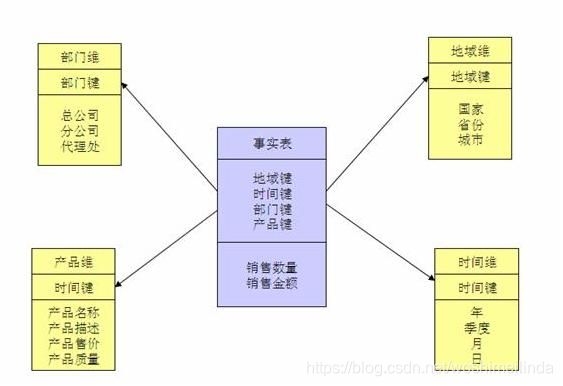
星型模是一种多维的数据关系,它由一个事实表和一组维表组成。每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。强调的是对维度进行预处理,将多个维度集合到一个事实表,形成一个宽表。这也是我们在使用hive时,经常会看到一些大宽表的原因,大宽表一般都是事实表,包含了维度关联的主键和一些度量信息,而维度表则是事实表里面维度的具体信息,使用时候一般通过join来组合数据,相对来说对OLAP的分析比较方便。
(二)雪花模型图示如下:
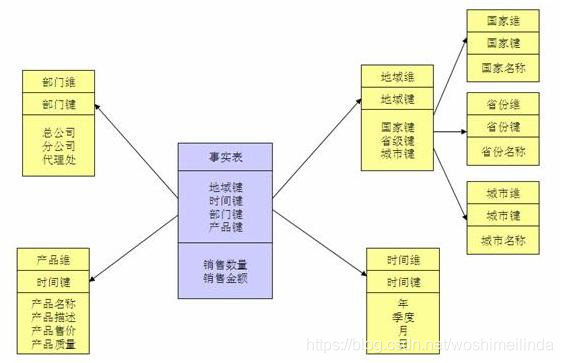
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 "层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。雪花模型更加符合数据库范式,减少数据冗余,但是在分析数据的时候,操作比较复杂,需要join的表比较多所以其性能并不一定比星型模型高。
(三)星型模型和雪花模型的优劣对比:
属性 星型模型 雪花模型
数据总量 多 少
可读性 容易 差
表个数 少 多
查询速度 快 慢
冗余度 高 低
对实时表的情况 增加宽度 字段比较少,冗余底
扩展性 差 好
(四)应用场景
星型模型的设计方式主要带来的好处是能够提升查询效率,因为生成的事实表已经经过预处理,主要的数据都在事实表里面,所以只要扫描实时表就能够进行大量的查询,而不必进行大量的join,其次维表数据一般比较少,在join可直接放入内存进行join以提升效率,除此之外,星型模型的事实表可读性比较好,不用关联多个表就能获取大部分核心信息,设计维护相对比较简答。
雪花模型的设计方式是比较符合数据库范式的理念,设计方式比较正规,数据冗余少,但在查询的时候可能需要join多张表从而导致查询效率下降,此外规范化操作在后期维护比较复杂。
(五)总结

通过上面的对比,我们可以发现数据仓库大多数时候是比较适合使用星型模型构建底层数据Hive表,通过大量的冗余来提升查询效率,星型模型对OLAP的分析引擎支持比较友好,这一点在Kylin中比较能体现。而雪花模型在关系型数据库中如MySQL,Oracle中非常常见,尤其像电商的数据库表。在数据仓库中雪花模型的应用场景比较少,但也不是没有,所以在具体设计的时候,可以考虑是不是能结合两者的优点参与设计,以此达到设计的最优化目的。
————————————————
版权声明:本文为CSDN博主「三劫散仙」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u010454030/article/details/74589791
