大神Inmon的《数据仓库》和kimball《数据仓库工具箱》算是两个经典吧,最近出了本很厚的《数据仓库与商业智能宝典》,但也是人家kimball以前经典文章的合集。
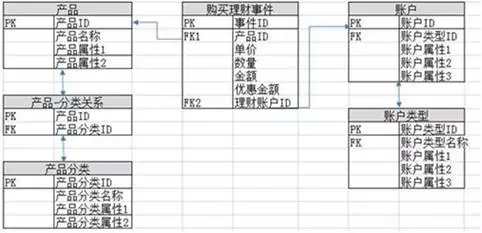
关系建模又叫ER建模,是数据仓库之父Inmon推崇的,其从全企业的高度设计一个3NF模型的方法,用实体加关系描述的数据模型描述企业业务架构,在范式理论上符合3NF,其是站在企业角度进行面向主题的抽象,而不是针对某个具体业务流程的,它更多是面向数据的整合和一致性治理,正如Inmon所希望达到的“single version of the truth”。
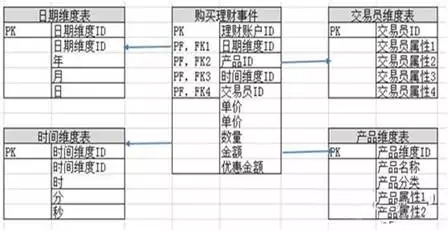
维度模型则是数据仓库领域另一位大师Ralph Kimball 所倡导的。维度建模以分析决策的需求为出发点构建模型,一般有较好的大规模复杂查询的响应性能,更直接面向业务,典型的代表是我们比较熟知的星形模型,以及在一些特殊场景下适用的雪花模型。
Inmon的ER建模优点体现在规范性较好,冗余小,数据集成和数据一致性方面得到重视,适用于较为大型的企业级、战略级的规划,但缺点是需要全面了解企业业务、数据和关系,对于建模人员要求很高,实施周期非常长,成本昂贵,笔者刚进公司的时候就经历了中国移动的的ER数据仓库项目,的确不是一个新人能短时消化的。
Kimball的维度建模相对能快速上手,快速交付,但缺点是冗余会较多,灵活性比较差,但其实现在看来也没什么,淘宝在大数据之路书中也提到“淘宝数据平台变迁的过程正好解释了二者的不同,最初,淘宝业务单一、系统简单,主要是简单的报表系统;后期数据量越来越大,系统越来越多,尝试用ER建模的数据仓库,但是在实践中发现快速变化的业务之下,构建ER模型的风险和难度都很高,现在则主要采用基于维度建模的模型方法了。”
但Inmon和kimball关于关系建模和维度建模的争论其实也没什么值得探讨的,没有谁更好,在企业内,这两种建模方式往往同时存在,底层用关系建模合适一点,技术的优雅换来了数据的精简,往上维度建模更合适一些,靠数据的冗余带来了可用性,优势互补,都说关系建模不易,概念模型是个坎,其实维度建模也不易,维度的梳理和运营是艰巨的,否则就是烂摊子的活。
在数据建模上,很多人纠结于如何建模,用关系建模、维度建模亦或其它?回过头来也是浮云,其实刚起步的时候没有那么多的循规蹈矩,满足报表和取数的需求即可,尽量做到“高内聚,松耦合”,这是服务的原则,放到数据建模照样适用。
很多企业花了巨大的代价建设了一套数据模型,周期长达1-2年,几年后却推倒重来,问题的根子不在于当初的项目完成的情况如何,包括建模方式是否合理,而在于项目完成了成鸟兽散,缺乏持续的运营。
想想企业的数据仓库模型,有多大的比例在日常的运营中进行了改进呢,有10%吗?阿里在建设数据中台,很大的挑战在于日常运营中对于中台业务的把控能力和持续改进的勇气,数据模型要成为使能者,不是简单的满足需求,也不是为了博得业务人员一时的满意,而是要立足于长远,始终主动、自发和持续的自我进化。
前段时间团队成员说为了满足数据挖掘需求要做一张超级宽表,很能说明问题,任何一个企业的数据模型都会碰到类似的挑战,但这也是混乱的开始,以下是经典的对话:
A:“现在数据挖掘变量准备太慢了,要搞一张大宽表,我们已经梳理了,需要从几十张表中取出字段,这个是这些表的清单?”
B:“跨度这么大,这么多字段,从DWD到DWI,再到DWA,有想过更好的办法吗?”
A:“这个?我们看了,融合模型缺这缺那的,还是再做一张吧,只是为这类数据做的!”
B:“你这张宽表下次会碰到融合模型同样的问题,融合模型是当前平衡做的相对好的,能否去增强融合模型,按字段归属到各融合模型,而不要另起条线,资源也有限的,让这些表的融合模型负责人过来讨论下?”
数据仓库模型的持续提升始终来自于日常朴实无华的需求驱动,数据中台蕴含着企业数据文化的再造,涉及到一系列机制流程的完善,认识到这点很重要。