1.现代操作系统内存管理
- 主流的操作系统(Windows,Linux)都采用虚拟内存管理的方式,具体说就是:页式管理、段式管理、段页式管理。
- 操作系统分配资源的单位是进程,所以,内存管理的过程也是以进程为单位的。
进程的地址空间
这里的地址空间指的都是虚拟地址空间。
要将进程的地址空间分为两部分:用户空间和内核空间。内核空间中存放内核的代码和数据,这个是用户空间不能随意访问的,只能通过系统调用陷入内核空间。用户空间存放用户的代码和数据。
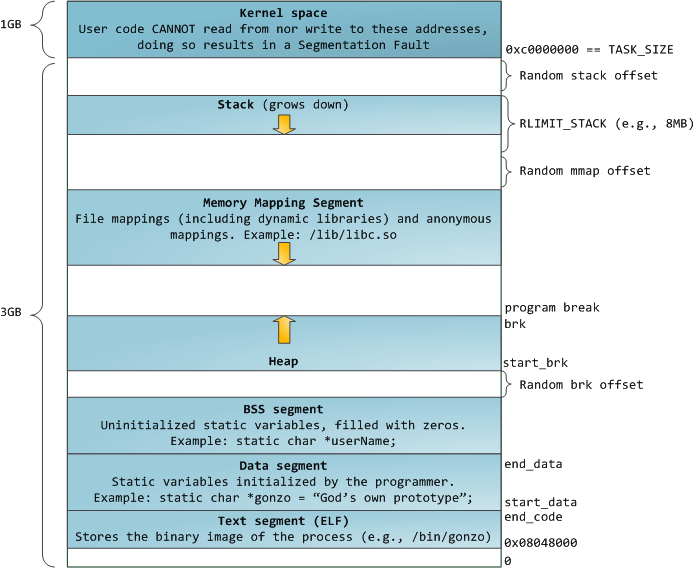
在Linux32位系统下,将1G用作内核空间,3G用于用户空间。虚拟的,虚拟的,虚拟的。
C++典型的内存分配

一个C++程序运行的时候,操作系统自动为其生成一个PCB,将程序的内容链接到此PCB的虚拟空间中,用户空间的内存模型刚好对应C++程序的内存。
一个C程序对应的内存模型:
- 代码区:存放程序执行的二进制代码,只读。
- 数据区:
- 已初始化的静态变量和全局变量。编译时就分配好内存
- 未初始化的静态变量和全局变量。
- 有的系统将常量放在代码区,而有的放在数据区。
- 栈区:这就是所说的栈内存,由高地址向低地址增长。
- 堆区:堆内存,由低地址向高地址增长。
一个C++对应的内存模型
1.栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清楚的变量的存储区。里面的变量通常是局部变量、函数参数等。
2.堆,就是那些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
3.自由存储区,就是那些由malloc等分配的内存块,他和堆是十分相似的,不过它是用free来结束自己的生命的。
4.全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量又分为初始化的和未初始化的,在C++里面没有这个区分了,他们共同占用同一块内存区。
5.常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改)
内存分配
栈内存分配:
扫描二维码关注公众号,回复: 9637023 查看本文章
栈内存分配一般由编译器负责分配和释放,栈上存放的是:局部变量,函数返回地址等。
堆内存分配
堆内存的操作,一般由使用者来操作,系统提供了操作堆内存的借口,而且,编程语言也提供了操作堆内存的方法。
堆内存一般是由(malloc/free/new/delete)来操作的。
堆内存的管理
堆内存由大小的限制,而且,操作不需要程序员关心,只 大专栏 堆内存和栈内存及C++内存分配需要确保不会栈溢出就好。
申请堆内存的过程:
通过malloc第一次申请内存,会触发一个缺页中断,然后陷入内核,通过调用brk系统调用,申请一片大的连续内存地址空间,放到空闲链表。然后,再执行一次刚才引起缺页中断的命令,即(malloc)。
假设操作系统或者一个进程已经获得了一块连续地址的内存,系统或进程在执行过程中需要利用这块内存来满足各种内存请求。由于内存请求存在动态性,即每次请求的内存大小可能不相同,甚至差异很大,并且这些小内存块的生命周期也不尽相同,所以,系统需要提供合适的算法来尽可能地满足这些动态的内存请求。在现代计算机系统中,堆(heap )正是这样一个提供动态内存分配能力的内存抽象。操作系统使用堆来满足各种动态内存请求,应用程序通过堆获得内存。
操作系统对于堆内存的管理,主要有两种方式:
位图法
使用这种方法,内存被分为很多以字节划分的单元,然后,用一个类似于数组的东西,用每一位0/1来标记这个内存块空闲或者已被使用。
缺点:位图要占用内存。需要大内存,搜索连续的0较为费时。
空闲链表法
在初始化时,整个空闲的内存被当做一个一个大的链表块,加入到空闲链表中,每当申请内存时,从空闲链表中找一块空的链表并且合适的可满足要求的内存块,取出所需要大小的内存交给申请者。然后,将已分配出去的内存加入到已分配链表中,当此块内存释放的时候,再将其加入到空闲链表中。
所以,针对这种分配法,提出了很多算法
- 最先匹配法(first-fit ),从空闲链表中找到第一个满足客户请求的空闲块。
- 最佳匹配法(best-fit ),从空闲链表中找到最接近于客户请求大小的空闲块。
- 最差匹配法(worst-fit),从空闲链表中找到最大的空闲块。
- 下一个匹配法(next-fit ),从空闲链表的当前位置往后扫描,找到第一个满足客户请求的空闲块。
缺点:通过较多次的分配后,产生大量的内存碎片(因为,每次分配的内存大小不同)。内存碎片又分为外碎片(两块)
而且,实现的时候,一般都是双链表,方便检查两块是否可以合并。
Slab算法
伙伴系统
需要注意的是,1.上述都是针对于虚拟内存的,虚拟内存到物理内存的映射,由一个硬件称为MMU的单元管理。
2.操作系统并没有提供内存管理的这些方法,这些操作都是由库函数完成的。
堆内存和栈内存的区别
大小的区别
栈内存,大小限制一般为1MB-2MB
堆内存,普通程序没有限制(2GB-3GB)
增长方向的区别
栈,由高地址向低地址增长
堆,低地址向高地址增长
空间管理的区别
栈,由编译器自动管理,弹栈和压栈,不会产生内存碎片。
堆,手动申请和释放,会产生大量内存碎片。
效率的区别
栈的效率高。现代机器有直接支持栈的指令,寄存器等
堆,是在库函数层面实现的,效率低。而且,栈是进程初始化就分配好的,而堆是动态分配的。
分配方式的区别
栈是编译时分配空间,而堆是动态分配(运行时分配空间)