遗传算法
基本思想:1、根据问题的目标函数构造适值函数(Fitness Function);
2、产生一个初始种群(100-1000);
3、根据适值函数的好坏,不断选择繁殖;
4、若干代后得到适值函数最好的个体即最优解。
构成要素: 1、种群(Population),种群大小(Pop-size)
2、基因表达法——编码方法;
3、遗传算子(Genetic Operator)——交叉、变异
4、选择策略:一般为正比选择)——选择种群中适应值高的个体,适者生存,优胜劣汰。
5、停止准则(Stopping Rule/Criterion)
算法流程图:

算法步骤:1、初始种群的产生:随机产生(依赖于选择的编码方法——二进制编码/实数编码);种群大小(依赖于计算机的计算机能力和计算复杂度)。
2、编码方法——二进制编码(用0,1字符串表达)。二进制适用于三种情况:背包问题+实时优化+指派问题。二进制编码缺点:编码长不利于计算;二进制编码优点:便于位值计算,包括的实数范围大。
3、适值函数——根据目标函数设计。用适值函数F(x)标定目标函数f(x)可采用方法:-minf(x)或maxf(x)
4、遗传算法——交叉和变异。
5、选择策略——最常用的是正比选择,选择概率的计算公式: ,得到选择概率P后,采用轮转法,计算得到轮转法的元素:
,得到选择概率P后,采用轮转法,计算得到轮转法的元素: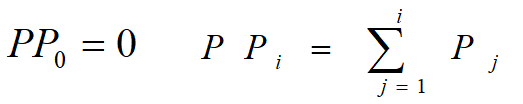 ,随机产生
,随机产生![]() ,当
,当![]() ,则选择个体i。
,则选择个体i。
图例:
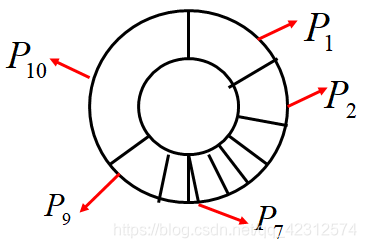
6、停止准则 ——通常指定最大迭代次数。
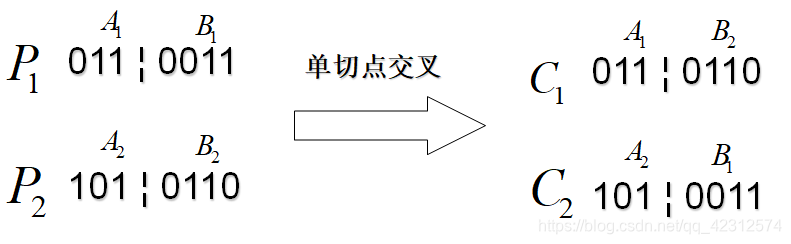
交叉:不是所有点都交叉,设定一个交叉概率 ,一般选较大数,比如0.9
(一)单切点交叉
随机产生一个断点(Cutting Point)[1,n-1]
例题:
(二)双切点交叉
例题:

变异:初始种群中没有需要的基因,在种群中按变异概率 任选若干位基因改变位值0→1或1→0,
有意想不到的结果, 一般设定得比较小,在5%以下。变异的可能是很小的,比如在陷入局部最优时
例题:NP:种群数量。




粒子群算法(Particle Swarm Optimization)
优点:简单易行、收敛速度快、设置参数少
算法介绍:
每个寻优的问题解都被想像成一只鸟,称为“粒子”。所有粒子都在一个D维空间进行搜索。
所有的粒子都由一个fitness function 确定适应值以判断目前的位置好坏。
每一个粒子必须赋予记忆功能,能记住所搜寻到的最佳位置。
每一个粒子还有一个速度以决定飞行的距离和方向。这个速度根据它本身的飞行经验以及同伴的飞行经验进行动态调整。
求最优解的过程中的符号表达:
D维空间中,有N个粒子;
粒子i位置:xi=(xi1,xi2,…xiD),将xi代入适应函数f(xi)求适应值;
粒子i速度:vi=(vi1,vi2,…viD)
粒子i个体经历过的最好位置:pbesti=(pi1,pi2,…piD)
种群所经历过的最好位置:gbest=(g1,g2,…gD)
通常,在第d(1≤d≤D)维的位置变化范围限定在![]() 内,速度变化范围限定在
内,速度变化范围限定在![]() 内(即在迭代中若Vid,Xid,超出了边界值,则该维的速度或位置被限制为该维最大速度或边界位置)
内(即在迭代中若Vid,Xid,超出了边界值,则该维的速度或位置被限制为该维最大速度或边界位置)
q粒子i的第d维速度更新公式:![]() ,
,
由三部分组成:粒子先前的速度(可理解为惯性速度)![]()
粒子本身的思考(粒子i当前位置与自己最好位置之间的距离)![]()
粒子间的社会经验(粒子i当前位置与群体最好位置之间的距离)![]()
图解:

q粒子i的第d维位置更新公式: ![]()
![]() —第k次迭代粒子i飞行速度矢量的第d维分量
—第k次迭代粒子i飞行速度矢量的第d维分量
![]() —第k次迭代粒子i位置矢量的第d维分量
—第k次迭代粒子i位置矢量的第d维分量
c1,c2—加速度常数,调节学习最大步长
r1,r2—两个随机函数,取值范围[0,1],以增加搜索随机性
w —惯性权重,非负数,调节对解空间的搜索范围
粒子群优化算法的算法流程图

粒子群算法的构成要素:
群体大小m:m是一个整型参数。m很小时陷入局部最优的可能性很大;m很大时,POS优化能力很好,当群体数目增长至一定水平时,再增加不再有显著的作用。
权重因子:惯性因子w:w=1是基本粒子群算法;w=0表示失去对粒子本身的速度的记忆。
学习因子c1:c1=0——无私型粒子群算法。缺点:迅速丧失群体多样性,易陷入局部最优而无法跳出。
学习因子c2:c2=0——自我认知型粒子群算法。缺点:完全没有信息的社会共享,导致算法的收敛速度很慢。
最大速度Vm:Vm较大时,探索能力增强,但是粒子容易飞过最优解;Vm较小时,开发能力增强,但容易陷入局部最优。Vm一般设为每维变量的变化范围的10%~20%。
邻域的拓扑结构:分为两种:将群体内所有个体都作为粒子的领域、只将群体中的部分个体作为粒子的领域。领域拓扑结构决定群体历史最优位置。故将粒子群算法分为全局粒子算法和局部粒子算法。
停止准则:最大迭代步数、可接受满意度。
粒子空间初始化:较好地选择粒子的初始化空间,将大大缩短收敛时间.初始化空间根据具体问题的不同而不同,也就是说,这是问题依赖的.
例子:








