说zab协议之前必须提一下 paxos 协议
paxos协议主要就是如何保证在分布式环网络环境下,各个服务器如何达成一致最终保证数据的一致性问题
ZAB协议,基于paxos协议的一个改进。
zab协议为分布式协调服务zookeeper专门设计的一种支持崩溃恢复的原子广播协议
zookeeper并没有完全采用paxos算法, 而是采用zab Zookeeper atomic broadcast
zab协议的原理
1. 在zookeeper 的主备模式下,通过zab协议来保证集群中各个副本数据的一致性
2. zookeeper使用的是单一的主进程来接收并处理所有的事务请求,并采用zab协议,
把数据的状态变更以事务请求的形式广播到其他的节点
3. zab协议在主备模型架构中,保证了同一时刻只能有一个主进程来广播服务器的状态变更
4. 所有的事务请求必须由全局唯一的服务器来协调处理,这个的服务器叫leader,其他的叫follower
leader节点主要负责把客户端的事务请求转化成一个事务提议(proposal),并分发给集群中的所有follower节点
再等待所有follower节点的反馈。一旦超过半数服务器进行了正确的反馈,那么leader就会commit这条消息。
5.然后再进行leader 和 follower 直接的数据同步。
这里有几个地方要注意一下:
1、follower服务器的投票并不是真正意义上的投票,而是follower 服务器 表示收到了 leader节点发过来的消息,给予一个收到的提示。 跟分布式事务中的 两阶段提交 中的第一阶段类似。
2、zab协议 与 分布式事务不同的是, 分布式事务 的两阶段提交要求所有事务处理节点(器)都要投票同意。
而zab协议中 只要求半数 服务器节点投票同意即可。
为什么只要半数就可以了呢?是因为zab协议就是为了保证在网络不可靠的情况下,整个集群还能正常的工作。
有超过半数的服务器投票同意,那么leader节点就执行写的操作,commit之后,再进行原子广播给其它的follower节点, 让 follower节点来同步数据
如果跟两阶段提交一样,还需要所有节点都同意的话,那明显与zab协议的使用场景不同了。
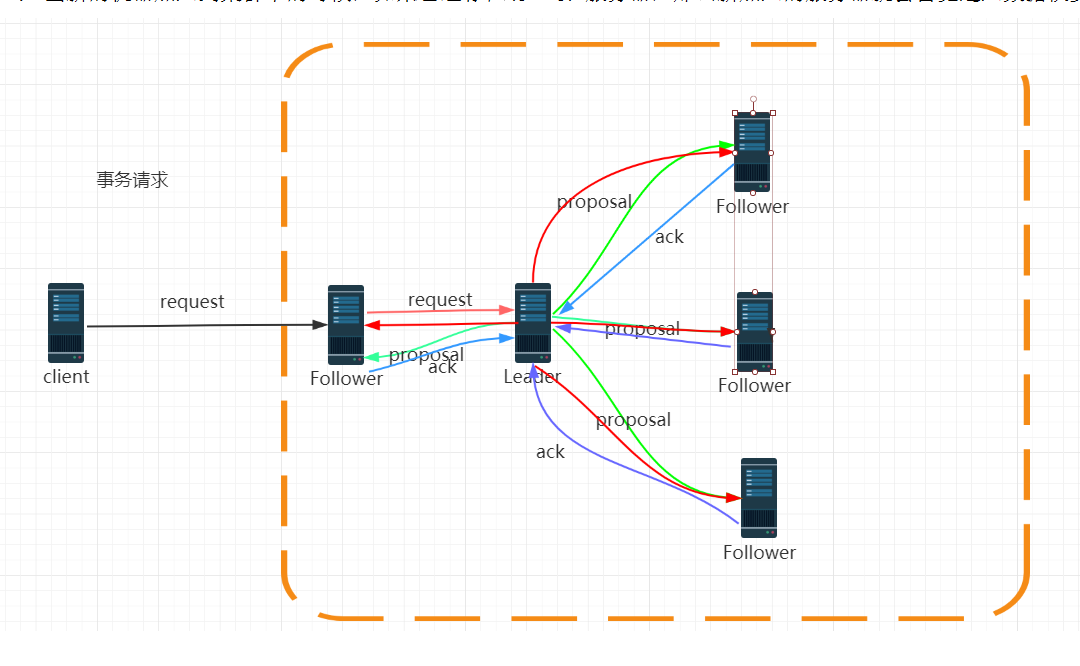
图的流程大致是:
1、客户端发来一个request给第一个follower节点,如果是读请求,follower节点直接将数据返回。
2、如果是写请求,也就是事务请求,那么follower节点就将请求转发给leader,leader再像集群中的 follower节点发起一个事务请求提议(proposal)。
3、follower节点正常情况下 都会返回一个ack 给 leader ,表示 follower 节点收到 leader的消息了,这里就是所谓的投票。
正常情况下都会投票的,没有投票的情况就是 有的follower 节点 挂掉了 投不了票就没投。
3、当机器中超过半数的服务器 都投票了(leader 自己本身也参与投票),那么 leader就commit 这个事务请求,然后再通过原子广播 通知 集群中其它的 follower 跟 Ob 节点来同步数据。