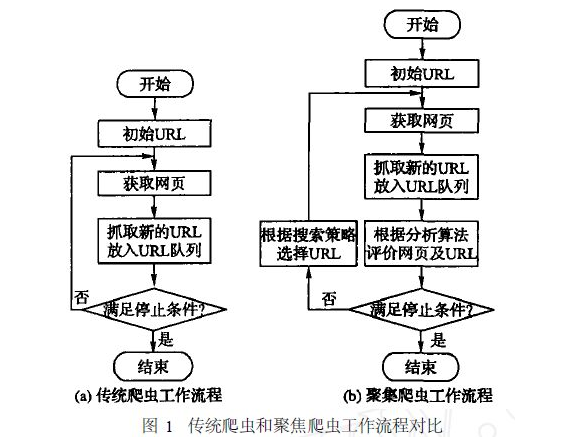
根据使用场景,网络爬虫可分为通用爬虫(传统爬虫)和聚焦爬虫两种
通用网络爬虫捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。但是大多数情况下,网页里面90%的内容对用户来说是无用的。
聚焦爬虫需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
而我们现在要学的就是聚焦爬虫。
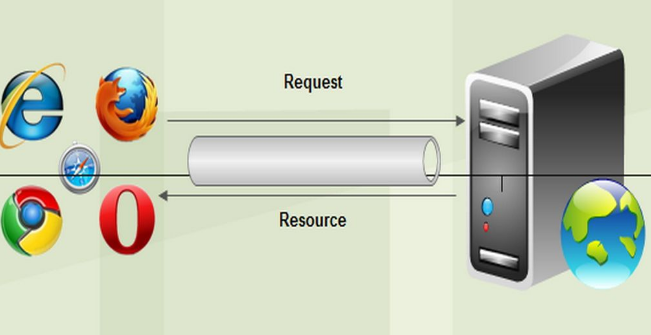
http请求:
浏览器的一个url向http服务器发送请求,分为:get和post两种。
浏览器发送一个request请求去获取URL的html文件,服务器把response文件对象发送回给浏览器。
浏览器解析response中的HTML,其中的img文件,css文件,js文件,浏览器会自动再次发送request请求获取图片,css文件或js文件。
当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
HTTP请求主要分为Get和Post两种方法
GET是从服务器上获取数据,POST是向服务器传送数据
GET请求参数显示,都显示在浏览器网址上,HTTP服务器根据该请求所包含URL中的参数
来产生响应内容,即“get”请求的参数是url的一部分。例如:http://www.baidu.com/s?wd=Chinese
向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据被包含在请求体中。POST请求可能会导致新的资源的建立或已有资源的修改,一般主要是表单提交,请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送,通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传操作等),请求的参数包含在“Content-Type”消息头里,指明该消息体的媒体类型和编码,
注意:避免使用Get方式提交表单,因为有可能会导致安全问题。 比如说在登陆表单中用Get方式,用户输入的用户名和密码将在地址栏中暴露无遗。
Python爬虫工作的流程图:

urllib2库的基本使用
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。 在Python中有很多库可以用来抓取网页,我们先学习urllib2。urllib2 在 python3.x 中被改为urllib.request
在python2中,urllib2的库基本使用:
# 导入urllib2 库
import urllib2
# 向指定的url发送请求,并返回服务器响应的类文件对象
response = urllib2.urlopen("http://www.baidu.com")
#read()方法读取文件全部内容,返回字符串
html = response.read()
# 打印字符串
print(html)
在python3中,urllib库的使用
#导入urllib库
import urllib.request
# 向指定的url发送请求,并返回服务器响应的类文件对象
response=urllib.request.urlopen('http://www.baidu.com')
#read()方法读取文件全部内容,返回字符串
html=response.read()
print(html)
如何模拟浏览器进行访问:
最好通过抓包工具,或者浏览器的调试工具,找到Headers

#导入模块
import urllib.request
import urllib.parse
#url,模拟浏览器
url='http://www.baidu.com'
hearder={
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
#发送请求
request=urllib.request.Request(url,headers=header)
response=urllib.request.urlopen(request).read()
#写入文件
f=open("./1.html","wb")
f.write(reponse)
f.close()