Java基础
1、List和set集合,Map集合的区别以及它们的实现类有哪些?有什么区别?
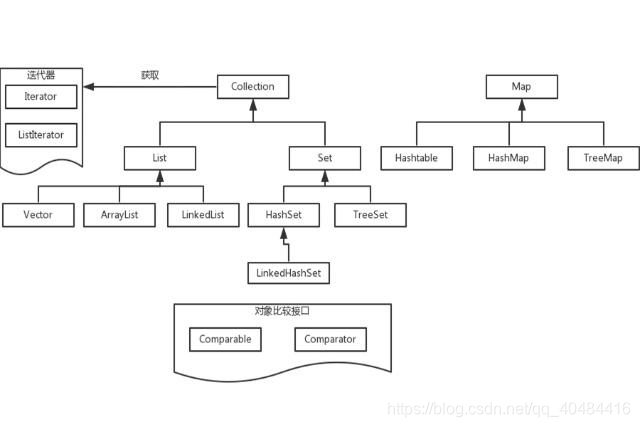
List 是可重复集合,Set 是不可重复集合,这两个接口都实现了 Collection 父接口。
Map 未继承 Collection,而是独立的接口,Map 是一种把键对象和值对象进行映射的集合,它的每一个元素都包含了一对键对象和值对象,Map 中存储的数据是没有顺序的, 其 key 是不能重复的,它的值是可以有重复的。
List 的实现类有 ArrayList,Vector 和 LinkedList:
ArrayList 和 Vector 内部是线性动态数组结构,在查询效率上会高很多,Vector 是线程安全的,相比 ArrayList 线程不安全的,性能会稍慢一些。
LinkedList:是双向链表的数据结构存储数据,在做查询时会按照序号索引数据进行前向或后向遍历,查询效率偏低,但插入数据时只需要记录本项的前后项即可,所以插入速度较快。
Set 的实现类有 HashSet 和 TreeSet;
HashSet:内部是由哈希表(实际上是一个 HashMap 实例)支持的。它不保证 set 元素的迭代顺序。
TreeSet:TreeSet 使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator 进行排序。
Map 接口有三个实现类:Hashtable,HashMap,TreeMap,LinkedHashMap;Hashtable:内部存储的键值对是无序的是按照哈希算法进行排序,与 HashMap 最大的区别就是线程安全。键或者值不能为 null,为 null 就会抛出空指针异常。TreeMap:基于红黑树 (red-black tree) 数据结构实现,按 key 排序,默认的排序方式是升序。LinkedHashMap:有序的 Map 集合实现类,相当于一个栈,先 put 进去的最后出来,先进后出。
List和map的区别:一个是存储单列数据的集合,另一个是存储键和值这样的双列数据的集合,List 中存储的数据是有顺序,并且允许重复;Map 中存储的数据是没有顺序的,其 key 是不能重复的,它的值是可以有重复的。
2、HashSet 是如何保证不重复的
在向hashSet中add()元素时,判断元素是否存在的依据,不仅仅是hash码值就能够确定的,同时还要结合equles方法
HashSet 类中的add()方法:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}put()方法:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
可以看到for循环中,遍历table中的元素,
1,如果hash码值不相同,说明是一个新元素,存;
如果没有元素和传入对象(也就是add的元素)的hash值相等,那么就认为这个元素在table中不存在,将其添加进table;
2(1),如果hash码值相同,且equles判断相等,说明元素已经存在,不存;
2(2),如果hash码值相同,且equles判断不相等,说明元素不存在,存;
如果有元素和传入对象的hash值相等,那么,继续进行equles()判断,如果仍然相等,那么就认为传入元素已经存在,不再添加,结束,否则仍然添加;
3、HashMap 是线程安全的吗,为什么不是线程安全的(最好画图说明多线程环境下不安全)?
不安全
https://coolshell.cn/articles/9606.html
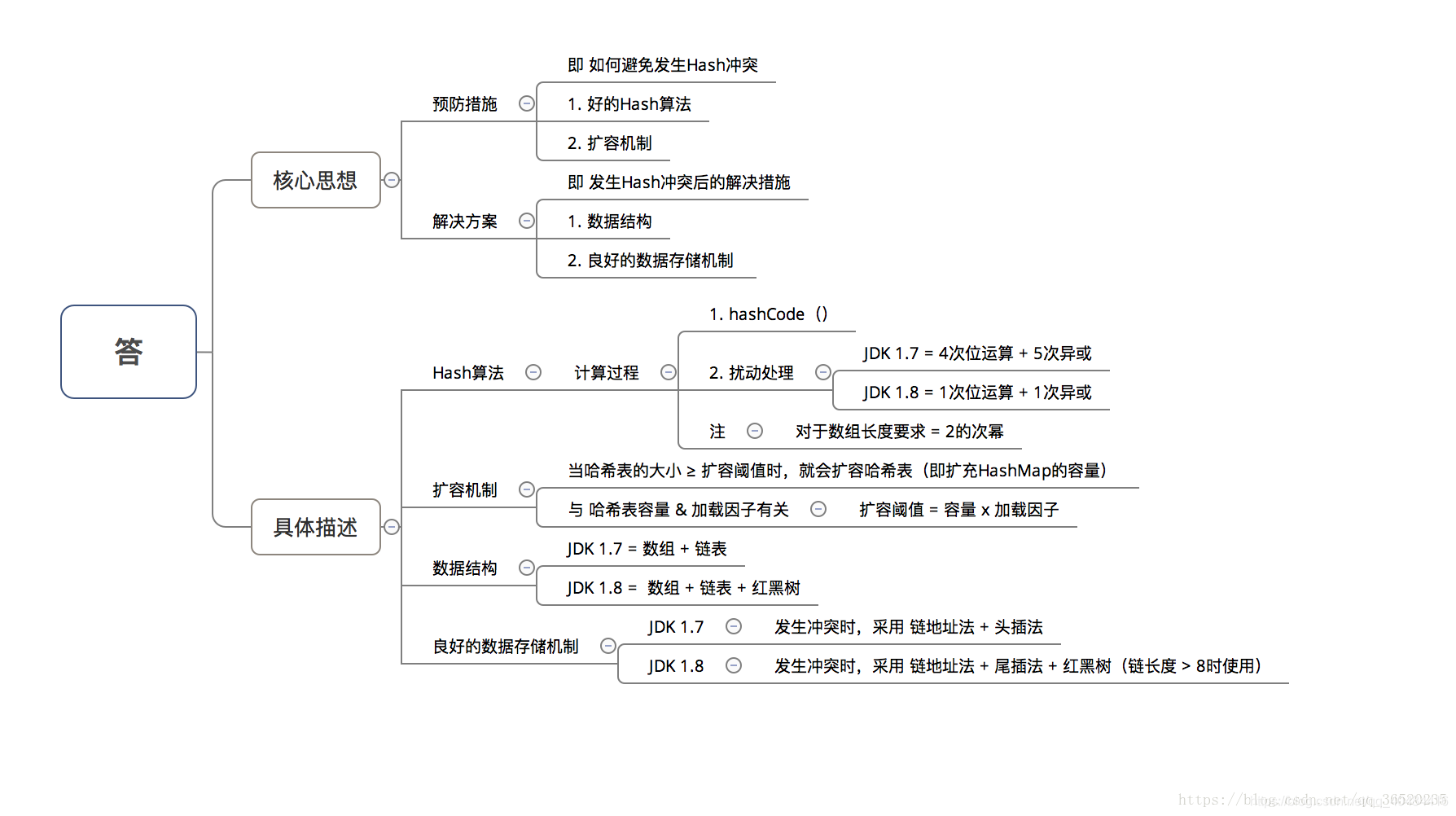
hashmap如何解决冲突
为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键

4、HashMap 的扩容过程
https://www.cnblogs.com/zhuoqingsen/p/8577646.html
5、HashMap 1.7 与 1.8 的 区别,说明 1.8 做了哪些优化,如何优化的?
6、final finally finalize
final用于声明属性,方法和类,分别表示属性不可交变,方法不可覆盖,类不可继承。
java中的关键字,修饰符。
A).如果一个类被声明为final,就意味着它不能再派生出新的子类,不能作为父类被继承。因此,一个类不能同时被声明为abstract抽象类的和final的类。
B).如果将变量或者方法声明为final,可以保证它们在使用中不被改变.
1)被声明为final的变量必须在声明时给定初值,而在以后的引用中只能读取,不可修改。
2)被声明final的方法只能使用,不能重载。
这是一道再经典不过的面试题了,我们在各个公司的面试题中几乎都能看到它的身影。final、finally和finalize虽然长得像孪生兄弟一样,但是它们的含义和用法却是大相径庭。
final关键字我们首先来说说final。它可以用于以下四个地方:
1).定义变量,包括静态的和非静态的。
2).定义方法的参数。
3).定义方法。
4).定义类。
定义变量,包括静态的和非静态的。定义方法的参数
第一种情况:
如果final修饰的是一个基本类型,就表示这个变量被赋予的值是不可变的,即它是个常量;
如果final修饰的是一个对象,就表示这个变量被赋予的引用是不可变的
这里需要提醒大家注意的是,不可改变的只是这个变量所保存的引用,并不是这个引用所指向的对象。
第二种情况:final的含义与第一种情况相同。
实际上对于前两种情况,一种更贴切的表述final的含义的描述,那就是,如果一个变量或方法参数被final修饰,就表示它只能被赋值一次,但是JAVA虚拟机为变量设定的默认值不记作一次赋值。被final修饰的变量必须被初始化。初始化的方式以下几种:
1.在定义的时候初始化。
2.final变量可以在初始化块中初始化,不可以在静态初始化块中初始化。
3.静态final变量可以在定义时初始化,也可以在静态初始化块中初始化,不可以在初始化块中初始化。
4.final变量还可以在类的构造器中初始化,但是静态final变量不可以。
finally是异常处理语句结构的一部分,表示总是执行。
java的一种异常处理机制。
finally是对Java异常处理模型的最佳补充。finally结构使代码总会执行,而不管无异常发生。使用finally可以维护对象的内部状态,并可以清理非内存资源。特别是在关闭数据库连接这方面,如果程序员把数据库连接的close()方法放到finally中,就会大大降低程序出错的几率。
finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,供垃圾收集时的其他资源回收,例如关闭文件等。
finalize:Java中的一个方法名。
Java技术使用finalize()方法在垃圾收集器将对象从内存中清除出去前,做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没被引用时对这个对象调用的。它是在Object类中定义的,因此所的类都继承了它。子类覆盖finalize()方法以整理系统资源或者执行其他清理工作。finalize()方法是在垃圾收集器删除对象之前对这个对象调用的。
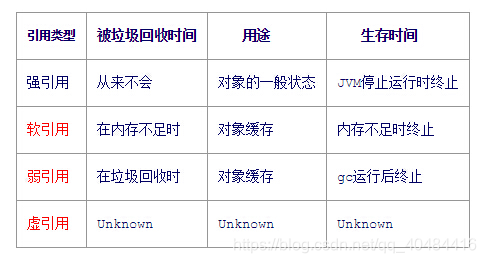
7、强引用 、软引用、 弱引用、虚引用