cellfun 常用于向量化编程,比for循环要快
对元胞数组中的每个元胞应用函数
语法
A = cellfun(func,C)
A = cellfun(func,C1,…,Cn)
A = cellfun(___,Name,Value)
[A1,…,Am] = cellfun(___)
说明
A = cellfun(func,C) 将函数 func 应用于元胞数组 C 的每个元胞的内容,每次应用于一个元胞。然后 cellfun 将 func 的输出串联成输出数组 A,因此,对于 C 的第 i 个元素来说,A(i) = func(C{i})。输入参数 func 是一个函数的函数句柄,此函数接受一个输入参数并返回一个标量。func 的输出可以是任何数据类型,只要该类型的对象可以串联即可。数组 A 和元胞数组 C 具有相同的大小。
您不能指定 cellfun 计算 A 的各元素的顺序,也不能指望它们按任何特定的顺序完成计算。
A = cellfun(func,C1,…,Cn) 将 func 应用于 C1,…,Cn 的各元胞的内容,因此 A(i) = func(C1{i},…,Cn{i})。函数 func 必须接受 n 个输入参数并返回一个标量。元胞数组 C1,…,Cn 的大小必须全部相同。
A = cellfun(___,Name,Value) 应用 func 并使用一个或多个 Name,Value 对组参数指定其他选项。例如,要以元胞数组形式返回输出值,请指定 ‘UniformOutput’,false。当 func 返回的值不能串联成数组时,可以按元胞数组的形式返回 A。您可以将 Name,Value 对组参数与上述任何语法中的输入参数结合使用。
当 func 返回 m 个输出值时,[A1,…,Am] = cellfun(___) 返回多个输出数组 A1,…,Am。func 可以返回不同数据类型的输出参数,但每次调用 func 时返回的每个输出的数据类型必须相同。您可以将此语法与前面语法中的任何输入参数结合使用。
从 func 返回的输出参数的数量不必与 C1,…,Cn 指定的输入参数的数量相同。
示例1 单个元胞输入
C = {1:10, [2; 4; 6], []};
A = cellfun(@mean,C) % 对元胞中每一个元素求均值
A = 1×3
5.5000 4.0000 NaN
示例2 多个元胞输入
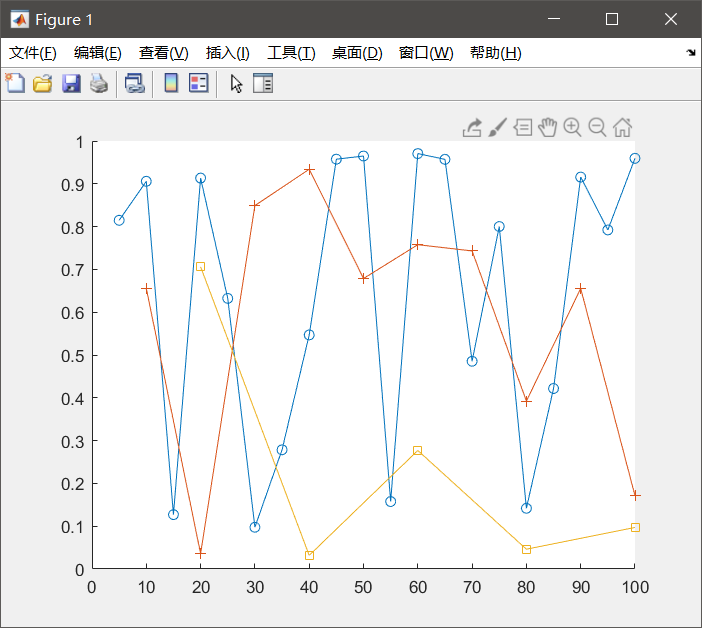
X = {5:5:100, 10:10:100, 20:20:100};
Y = {rand(1,20), rand(1,10), rand(1,5)}
figure
hold on
p = cellfun(@plot,X,Y);
p(1).Marker = 'o';
p(2).Marker = '+';
p(3).Marker = 's';
hold off
示例3 多个数组输出
C = {1:10, [2; 4; 6], []}
[nrows,ncols] = cellfun(@size,C)
C = 1x3 cell array
{1x10 double} {3x1 double} {0x0 double}
nrows = 1×3
1 3 0
ncols = 1×3
10 1 0
示例4 UniformOutput参数
A = cellfun(@mean,C,‘UniformOutput’,false) 以元胞数组的形式返回 mean 的输出。
>> C = {1:10, [2; 4; 6], []};
>> A = cellfun(@mean,C,'UniformOutput',false)
A =
1×3 cell 数组
{[5.5000]} {[4]} {[NaN]}
>>A = cellfun(@mean,C,'UniformOutput',true)
A =
5.5000 4.0000 NaN
更多向量化编程函数参见 arrayfun structfun bsxfun
