楔子:某个时间,由于不清不楚的某些原因,导致了一次严重的线上事故。后来,开发不清不楚的配合把项目升级到了 Redis 高可用集群的哨兵模式(Redis-Sentinel),再后来,我们逐渐的又不清不楚的淡忘了这件事。节点化的工作很容易导致一定程度上只知其然而不知其所以然,这是项目开发中的一个众相。回想起来,我还是想记点什么。
该篇可以为 Redis 容灾+高可用 应用场景提供解决方案。
1. 哨兵进击
1.1. 闪亮登场的哨兵
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(Instance),Redis 的 Sentinel 为其提供了高可用性。因为当主服务器宕机后,如果手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。所以,如果能创建一个可以不用人为干预而应对各种故障的高可用的 Redis 部署,那就爽歪歪了。
Redis-Sentinel 为 Redis 的作者 antirez,因为 Redis 集群的被各大公司使用,每个公司要写自己的集群管理工具,于是 antirez 花了几个星期写出了 Redis-sentinel(Redis 哨兵模式),这个"机器人"可以 7*24 小时工作,它能够自动帮助我们做一些事情,如监控,提醒,自动处理故障等等。
1.2. 身怀绝技的哨兵
这么一个技术超群的哨兵可以做些什么呢?
- 监控(Monitoring):哨兵会不断地检查主节点 Master 和从节点 Slave 是否运作正常
- 提醒(Notification):当被监控的某个 Redis 出现问题时,哨兵可以通过 API 向管理员或者其它应用程序发送通知
- 自动故障迁移(Automatic failover):
如果一个 Master 不能正常工作时,哨兵会开始一次自动故障迁移操作,它会将失效 Master 下的其中一个 Slave 升级为新的 Master,并让失效 Master 下的其它 Slave 改为复制新的 Master。
当客户端试图连接失效 Master 时,集群会向客户端返回 新Master 的地址,如此,可使得集群可以使用 新Master 代替 失效Master

1.3. 神形兼备的哨兵
一个可能会思考的哨兵?一个有行为的机器人?
Redis Sentinel 是一个分布式系统, 你可以在一个架构中运行多个 Sentinel 进程。一个 Sentinel 可以与其他多个 Sentinel 进行连接, 各个 Sentinel 之间可以互相检查对方的可用性, 并进行信息交换。
每个哨兵(sentinel)会向其它哨兵(sentinel)、master、slave 定时发送消息,以确认对方是否“活”着。如果发现对方在指定时间(可配置)内未回应,则暂时认为对方已挂(即所谓的“主观认为宕机”或“主观下线”:Subjective Down,简称 sdown)
若“哨兵群”中的多数 sentinel 都报告某一 master 没响应,系统才认为 该master “彻底死亡”(即客观上的真正宕机或“客观下线”:Objective Down,简称 odown),通过一定的 vote 算法,从剩下的 slave 节点中,选一台提升为 master,然后自动修改相关配置
1.4. 三头六臂的哨兵
首先,练就一个三头六臂的哨兵(Redis Sentinel)需要准备以下工序:
| 服务类型 | 是否是主服务器 | IP地址 | 端口 |
|---|---|---|---|
| Redis | 是 | 127.0.0.1 | 6379 |
| Redis | 否 | 127.0.0.1 | 6380 |
| Redis | 否 | 127.0.0.1 | 6381 |
| Sentinel | - | 127.0.0.1 | 26379 |
| Sentinel | - | 127.0.0.1 | 26380 |
| Sentinel | - | 127.0.0.1 | 26381 |
首先,准备 Sentinel。这里我们需要将解压好的 Redis 资源拷贝成三份,以端口号重命名文件夹,分别用作 master、两个 slave:
- Redis-6369:用作 master 角色(主节点)
- Redis-6380:用作 slave 角色(从节点)
- Redis-6381:用作 slave 角色(从节点)
从上面的需求准备可以看出,哨兵模式的基础是一主多从,所以 上一击 我们做的就是这节的基础。再来练一遍吧,先把这三份 Redis 中的 6380、6381 的 redis.windows.conf 文件配置成 slave。如果有什么疑问,可以参考:Redis进击(二)搭建Redis主从复制服务集群(一主两从、反客为主)【Windows环境】
注:如果不改,三份 Redis 要启动服务,端口都默认的 6379,所以到启第二个的时候就会报错:[45244] 05 Sep 18:23:18.410 # Creating Server TCP listening socket *:6379: bind: No error
另:Windows 下的 Redis 安装与配置如果有什么疑问,可以参考:Redis进击(一)从0到1,Redis的安装与使用
2. 站岗放哨
2.1. 配置 Sentinel
再次,我们需要修改配置文件 sentinel.conf。Windows 环境下的 Redis 解压包中目前是没有这个文件的,那我们来新建它~
在每个 Redis 文件夹下新增一个名为 sentinel.conf 的文件,然后配置如下内容:
# ------------------------------------------------------------------------------------ #
# 这个是Redis-6379的配置内容,其它两个Redis-6380、Redis-6381同理新增然后改一下端口即可 #
# ------------------------------------------------------------------------------------ #
# 当前Sentinel服务运行的端口
# 在默认情况下,Sentinel 使用 TCP 端口 26379(普通 Redis 服务器使用的是 6379 )
port 26379
# 哨兵监听的主节点mymaster;最后面的数字 3 表示最低通过票数;# 默认值 2
# 如果投票通过,则哨兵群体认为该主节点客观下线(odowm)
sentinel monitor mymaster 127.0.0.1 6379 3
# 哨兵认定当前主节点mymaster失效的判别间隔时间
# 如果在设置的时间内(毫秒),当前主节点没有响应或者响应错误代码,则当前哨兵认为该主节点主主观下线(sdown)
# 3s内mymaster无响应,则认为mymaster宕机了
sentinel down-after-milliseconds mymaster 3000
# 执行故障转移时,最多有1个从节点同时对新的主节点进行同步
# 当新的master上位时,允许从节点同时对新主节点进行同步的从节点个数;默认是1,建议保持默认值
# 在故障转移期间,将会终止客户端的请求
# 如果此值较大,则意味着"集群"终止客户端请求的时间总和比较大
# 反之此值较小,则意味着"集群"在故障转移期间,多个从节点仍可以提供服务给客户端
sentinel parallel-syncs mymaster 1
# 故障转移超时时间。
# 当故障转移开始后,但是在此时间内仍然没有触发任何故障转移操作,则当前哨兵会认为此次故障转移失败
sentinel failover-timeout mymaster 10000这个是 Redis-6379 的新增 sentinel.conf 文件与配置,另外 Redis-6380、Redis-6381 两个同理新增,然后修改 port 为目录对应的端口即可。配置内容与解释都在上面的代码中,可以参考下,也许读完会有一定收获。
注:在默认情况下, Sentinel 使用 TCP 端口 26379 (普通 Redis 服务器使用的是 6379 )。
2.2. 语法说明
sentinel monitor [master-group-name] [ip] [port] [quorum]
- master-group-name:master名称(可以自定义)
- ip port : IP地址和端口号
- quorun:票数,Sentinel需要协商同意master是否可到达的数量。
2.3. 启动 Sentinel
可以用 CMD 命令分别启动各个 Redis 目录下的 redis-server.exe 和 sentinel.conf,命令如下:
- Redis 服务端启动命令:redis-server.exe redis.windows.conf
- Redis 哨兵启动命令:redis-server.exe sentinel.conf --sentinel
但是,这操作太繁杂了,还有客户端呢。所以我们优化下,做个小工具:
Redis 6379 下新增 Redis 服务端启动脚本文件 redis-6379-master-server.bat,内容如下:
@echo off
SET DIR=%~dp0\Redis-6379\
START %DIR%redis-server.exe %DIR%redis.windows.confRedis 6379 下新增 Redis Sentinel 哨兵启动脚本文件 redis-6379-sentinel.bat,内容如下:
@echo off
SET DIR=%~dp0\Redis-6379\
START %DIR%redis-server.exe %DIR%sentinel.conf --sentinelRedis 6379 下新增 Redis 客户端启动脚本文件 redis-6379-mater-client.bat,内容如下:
@echo off
START %~dp0\Redis-6379\redis-cli.exe -p 6379另外 Redis-6380、Redis-6381 两个同理新增,然后配置如上内容,记得修改 Redis 文件夹路径。配置好后效果如下:

划重点~ 启哨兵~
第一步,启动 Redis 集群。
依次执行 redis-6379-master-server.bat、redis-6380-slave-server.bat、redis-6381-slave-server.bat。

确认三个 Redis 的服务端启动OK,连接主节点/主服务器 master OK。
第二步,启动哨兵实例。
依次执行 redis-6379-sentinel.bat、redis-6380-sentinel.bat、redis-6381-sentinel.bat。
主节点/主服务器(master)的哨兵:26379

从节点/从服务器(slave)的哨兵:26380

从节点/从服务器(slave)的哨兵:26381

查看 Sentinel 的启动日志,它们都会生成哨兵ID,且都能自动识别主服务器和从服务器,并相互连通监视。
再查看一下主从服务器端的主从复制信息:

好了,到此,Windows 下的 Redis 哨兵模式已经构建好了。我们需要来验证一下。
3. 性能演练
高可用场景演示
3.1. 主服务器 master 宕机
在 6379 的 Redis 客户端上关闭 6379 主服务器,模拟异常发生:
127.0.0.1:6379> shutdown
not connected>哨兵 26381 的反映:

哨兵 26379 的反映:

哨兵 26381 的反映:【投票让位机制的选举故事】

【投票让位机制的选举故事】如上图文字标注。
如果服务器在给定的毫秒数之内(master-down-after-milliseconds 选项所指定的时间内), 没有返回 Sentinel 发送的 PING 命令的回复(valid reply), 或者返回一个错误, 那么 Sentinel 将这个服务器标记为主观下线(subjectively down,简称 SDOWN )。
不过,只有一个 Sentinel 将服务器标记为主观下线并不一定会引起服务器的自动故障迁移: 只有在足够数量的 Sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为客观下线(objectively down, 简称 ODOWN ), 这时自动故障迁移才会执行。客观下线条件只适用于主服务器。
服务器对 PING 命令的有效回复可以是以下三种回复的其中一种:
- 返回 +PONG
- 返回 -LOADING 错误
- 返回 -MASTERDOWN 错误
如果服务器返回除以上三种回复之外的其他回复,又或者在指定时间内没有回复 PING 命令,那么 Sentinel 认为服务器返回的回复无效(non-valid)。
举个例子,如果 master-down-after-milliseconds 选项的值为 30000 毫秒(30 秒,可配置),那么只要服务器能在每 29 秒之内返回至少一次有效回复,这个服务器就仍然会被认为是处于正常状态的。
从主观下线状态切换到客观下线状态并没有使用严格的法定人数算法(strong quorum algorithm), 而是使用了流言协议: 如果 Sentinel 在给定的时间范围内, 从其他 Sentinel 那里接收到了足够数量的主服务器下线报告, 那么 Sentinel 就会将主服务器的状态从主观下线改变为客观下线。 如果之后其他 Sentinel 不再报告主服务器已下线, 那么客观下线状态就会被移除。

从这个场景可以看到,当主服务器/主节点master宕机后,通过哨兵投票让位机制,哨兵选举出了新的master。且连在原master上的从节点已经重连到了新master上。原从节点上位变成master后,变得可读可写;而从节点还是只能读不可写。
3.2. 重启故障 master 6379
执行之前写好的脚本 redis-6379-master-server.bat,再次启动 6379 服务器,发现 6379 成为 6380 的从服务器:

查看 6380 服务器状态信息:原来的 master 6379 自动切换成 slave,不会自动恢复成 master。

从这个场景可以看到,当重启之前的故障master 时,它连向了 新master,而且 原master 成了 新master 的一个从节点。
3.3. 从服务器 Slave 宕机和重启
在 6381 的 Redis 客户端上关闭 6381 服务器,模拟异常发生:
127.0.0.1:6381> shutdown
not connected>哨兵 26380 的反映:
[55772] 06 Sep 14:28:20.837 # +sdown slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6380
查看主服务器 6380 状态信息:
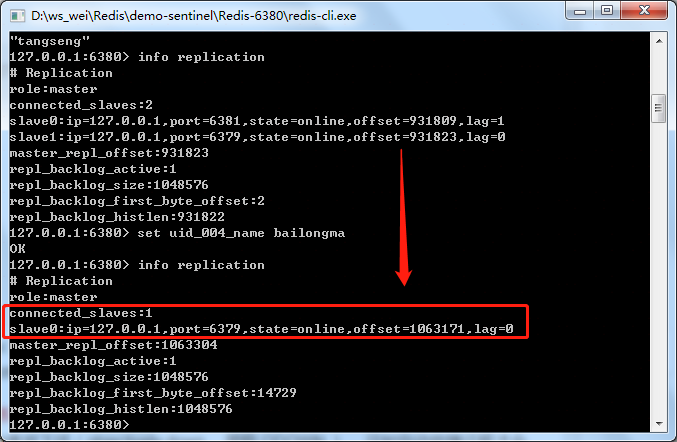
宕机的从节点 6381 消息,master 6380 的从节点由2个变成了1个。
执行之前写好的脚本 redis-6381-slave-server.bat,再次启动 6381 服务器,6380 从服务器又回归到了 master 6380 下:

从这个场景可以看到,从节点宕机重启恢复后,还是会以从节点身份连master,不会影响master。而且,从节点 slave 能照常读取到 master 在其宕机期间新增的键值。
参考文档资料:
https://redis.io/topics/sentinel
http://www.redis.cn/topics/sentinel.html
Redis 进击物语:
Redis进击(一)从0到1,Redis的安装与使用
Redis进击(二)搭建Redis主从复制服务集群(一主两从、反客为主)【Windows环境】
Redis进击(三)搭建Redis高可用集群的哨兵模式(Redis-Sentinel)【Windows环境】
Redis进击(四)Java中配置和使用Redis高可用集群的哨兵模式(Redis-Sentinel)【Spring&SpringBoot环境】
Redis进击(五)redis.conf配置文件说明备注手册
Redis异常:Creating Server TCP listening socket *:26379: bind : No such file or directory
Redis异常:JedisException: Can connect to sentinel, but 127.0.0.1:6379 seems to be not monitored...
Redis异常:JedisConnectionException: All sentinels down, cannot determine where is mymaster master is
