1)官网下载source源码。版本:spark-2.2.0
[root@hadoop000 spark-2.2.0]# wget https://www.apache.org/dyn/closer.lua/spark/spark-2.2.0/spark-2.2.0.tgz --no-check-certificate
2)解压
[root@hadoop000 spark-2.2.0]# tar zxvf spark-2.2.0.tgz
3)进入根目录,执行mvn命令
[root@hadoop000 spark-2.2.0]#
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Dhadoop.version=2.6.0-cdh5.7.0 -Phadoop-2.6 -Phive -Phive-thriftserver -Pyarn
途中报错:
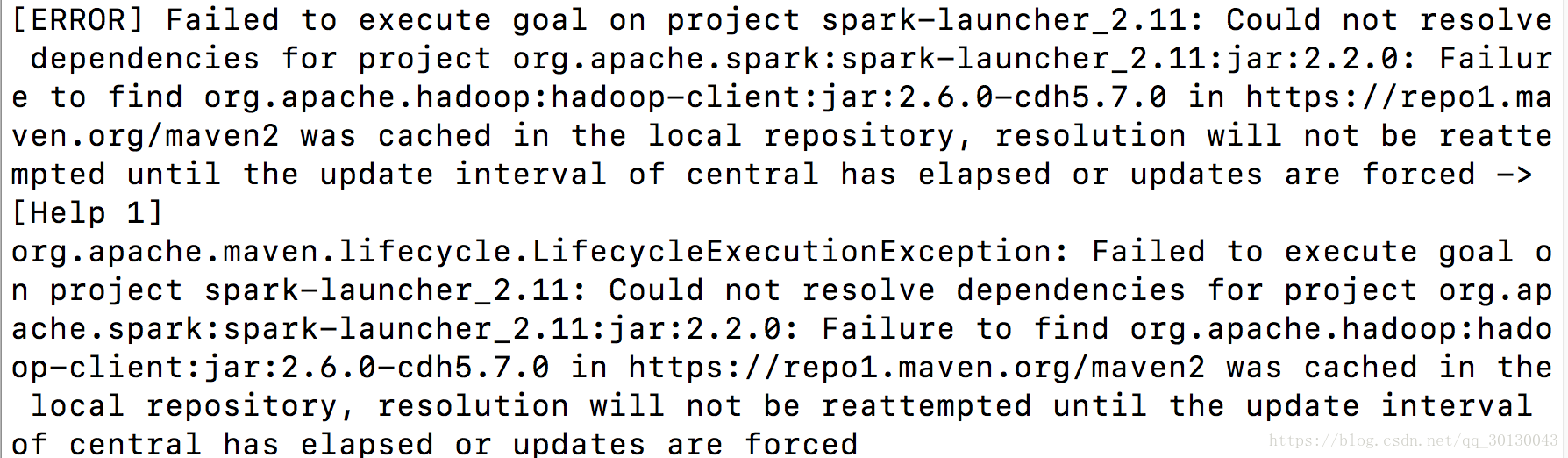
解决:hadoop的版本写的是CDH,这时要将CDH的仓库配进来,打开spark目录下的pom.xml文件,将CDH的仓库配进去
<repository>
<id>cloudera</id>
<name>cloudera Repository</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
</repository>