1. 写在前面
今天补了一下机器学习的数学知识,突然又遇到了判别模型和生成模型这两个词语,之前学习统计学习方法的时候也遇到过,当时就模模糊糊的,如今再遇到,发现我还是没明白, 但这次哪有轻易再放过去之理?所以查了很多资料,试图结合自己理解的,把这个知识点整理整理,毕竟这个知识点也是面试官非常喜欢问的一个问题。
所以,下面我尽量把语言说的白话一些。
2. 判定模型 VS 生成模型
从本质上讲,生成模型和判别模型是解决分类问题的两类基本思路。 首先,你得了解,分类问题,就是我给定一个数据x,去判断它对应的标签y。
我的目标就是P(Y|X)。 下面我直接开门见山,先说一下这两种模型针对这个目标是怎么去做的:
- 对于生成模型来说,我的目标虽然是P(Y|X), 但是对于训练集,我需要去学习X和Y的联合概率分布P(X,Y), 也就是对(X,Y)的联合概率进行建模,这样我面对一个新的X的时候,我就直接可以看看这样的特征到底哪一个Y才可能具有,我选择最有可能具有这样X的那个Y。即P(X,Y1), P(X,Y2)…P(X,Yn)里面最大的那个概率。 这里面我学习的是一种生成关系:哪一个Y更有可能有某种特征X,我就选哪一个
- 而对于判别模型来说,我的目标是是P(Y|X),对于训练集,我直接就去学习P(Y|X),即我学习的是这些不同类样本之间的那种区别,最后会有一条边界把不同类样本分开,这样我面对一个新的X的时候,我根据之前学习到的边界就可以直接预测出Y。在这里面,我学习的是一种映射关系:你给我的这种X,直接就是某种类别Y
好吧,如果不明白,先看下面的图,我再解释:
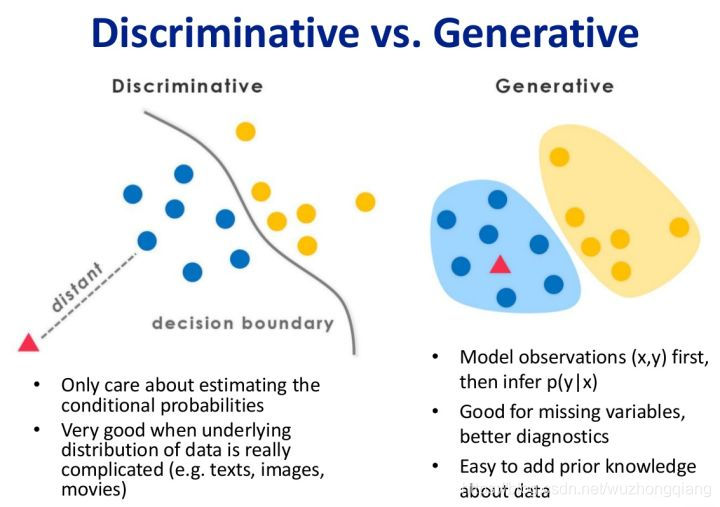
左边是判别模型,右边是生成模型。我可以再描述一下我说的话:
- 生成式模型是求得P(X,Y),对于未见示例X,你要求出X与不同标记Y之间的联合概率分布,然后大的获胜,如上图右边所示,并没有什么边界存在,对于未见示例(红三角),求两个联合概率分布(有两个类),比较一下,取那个大的。(所以传统的、耳熟能详的机器学习算法如线性回归模型、支持向量机SVM等都是判别式模型,这些模型的特点都是输入属性X可以直接得到Y(对于二分类任务来说,实际得到一个score,当score大于threshold时则为正类,否则为反类))
- 判别式模型来说求得P(Y|X),对未见示例X,根据P(Y|X)可以求得标记Y,即可以直接判别出来,如上图的左边所示,实际是就是直接得到了判别边界。(机器学习中朴素贝叶斯模型、隐马尔可夫模型HMM等都是生成式模型,熟悉Naive Bayes的都知道,对于输入X,需要求出好几个联合概率,然后较大的那个就是预测结果)
这样说,能明白了吗? 如果还没有明白,举栗子吧还是。
3. 没有栗子,就没有明白
如果感觉还是太复杂,看来说的还是不白活,那么我举两个栗子吧:
3.1 栗子一:
假设你的孩子从来没有见过大象和猫, 听都没听过,这时,你给他看了一张大象和猫的图片,如下:

然后是猫咪:

过了几天之后,你领孩子去了动物园,看到了真的大象, 你问你孩子,这时大象还是猫?
你孩子应该怎么办呢?
这时候,他开始回忆之前看过的图片,大概记起来,大象和猫比起来,有个长鼻子,而眼前这个家伙也有个长鼻子,所以他兴奋的告诉你: 这是大象,因为有个长鼻子。 你说:哈哈,说的真棒,回头给你买一头回去当宠物!
其实,你孩子也有可能这样做,他努力的回忆之前看过的两张图片,然后回忆更多的细节特征,然后用笔把大象和猫的大致样子画了出来。 然后把眼前的这个家伙把自己画的一一比对,他发现,眼前的这个家伙更像是大象,于是他高兴的说:这是一个大象,因为他和手里面画的左边这个差不多一样。 你孩子是真的牛!
在上面这个栗子中,你孩子的第一种解决问题的思路就是判别模型,因为他只记住了大象和猫的不同之处。 第二种解决问题的思路就是生成模型,因为他实际上学习了什么是大象,什么是猫。
3.2 栗子二:
假设我们想从(1,0), (1,0), (2,0),(2,1)这四个样本里面学习如果通过x去判断y的模型。
- 用生成模型,我们要学习P(x,y), 如下所示:
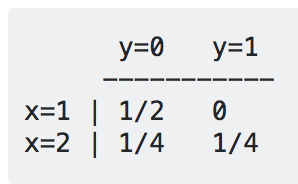
我们学习了四个概率值,它们的和是1,这就是P(x,y) - 用判别模型,我们直接学习P(y|x), 如下所示:
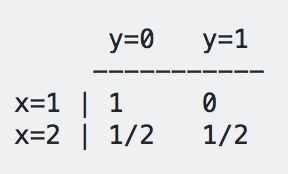
我们同样学习了四个概率值,但是这次,是每一行的两个概率值和为1。
下面来看看,如何使用这两个模型做判断。
假设我们有一个新x=1:
- 对于生成模型,我们比较P(x=1, y=0) = 1/2,P(x=1,y=1)=0, 我们发现P(x=1,y=0)的概率大一些,所以曰:y=0
- 对于判别模型,我们比较P(y=0|x=1) = 1, P(y=0|x=1)=0, 我们发现P(y=0|x=1)这一个大,所以判断y=0
我们可以发现,最后的预测结果一样,但是得出结果的逻辑却是完全不同的。
3.3 栗子三:
先给你一些羊群让你学习,然后给你一只新的羊,让你判断是山羊还是绵羊,你怎么办?
- 对于判别模型来讲,要确定是山羊还是绵羊,我之前学习的时候我重点学习山羊和绵羊之间的区别,得到一个能够根据区别正确分离山羊和绵羊的模型来,拿到这只新的羊,我直接根据它的特征就可以确定是山羊还是绵羊(毕竟山羊绵羊的某些特征是不一样的)
- 对于生成模型来讲,要确定是山羊还是绵羊,我之前学习的时候重点是根据之前的模型,我学习出一个山羊群,学习出一个绵羊群体, 然后拿到这只羊之后,我放到这样群里看看像不像山羊,再拿到绵羊群里看看像不像绵羊,哪个更像,我就说是什么。
细细品味上面的例子,判别式模型是根据一只羊的特征可以直接给出这只羊的概率(比如logistic regression,这概率大于0.5时则为正例,否则为反例),而生成式模型是要都试一试,最大的概率的那个就是最后结果。
这样应该更加清晰点了吧。
4. 生成模型和判别模型的名字来源
在机器学习中任务是从属性X预测标记Y,判别模型求的是P(Y|X),即后验概率;而生成模型最后求的是P(X,Y),即联合概率。从本质上来说:
- 判别模型之所以称为“判别”模型,是因为其根据X就可以直接去“判别”Y;
- 生成模型之所以称为“生成”模型,是因为其预测的根据是联合概率P(X,Y),而联合概率可以理解为“生成”(X,Y)样本的概率分布(或称为 依据);它背后的思想是,x是特征,y是标签,什么样的标签就会生成什么样的特征,比如标签是大象,那么可能生成的特征就有大耳朵,长鼻子等。
当我们来根据x来判断y时,我们实际上是在比较,什么样的y标签更可能生成特征x,我们预测的结果就是更可能生成x特征的y标签。(具体来说,机器学习已知X,从Y的候选集合中选出一个来,可能的样本有(X,Y_1), (X,Y_2), (X,Y_3),……,(X,Y_n),实际数据是如何“生成”的依赖于P(X,Y),那么最后的预测结果选哪一个Y呢?那就选“生成”概率最大的那个吧。)
5. 这两种模型的优缺点
- 生成模型
- 优点:
- 缺点:


- 判别模型
- 优点:
- 缺点: 没有生成模型的那些优点

最后再来总结一下机器学习方法中哪些属于生成模型哪些属于判别模型,根据这些算法的特点,再来体会生成和判别模型的差异:
- 生成模型:朴素贝叶斯、隐马尔可夫(HMM)这是重点的EM算法
- 判别模型: K近邻,感知机,logistic回归,SVM,提升方法等
这些机器学习算法,我基本上都用大白话描述了一遍,不懂得,可以看看
十大机器学习算法的一个小总结
