编码的发展:
初始,首先出现的是ASCII编码,其中每个元素占8个比特位,即一个字节。如图所示:
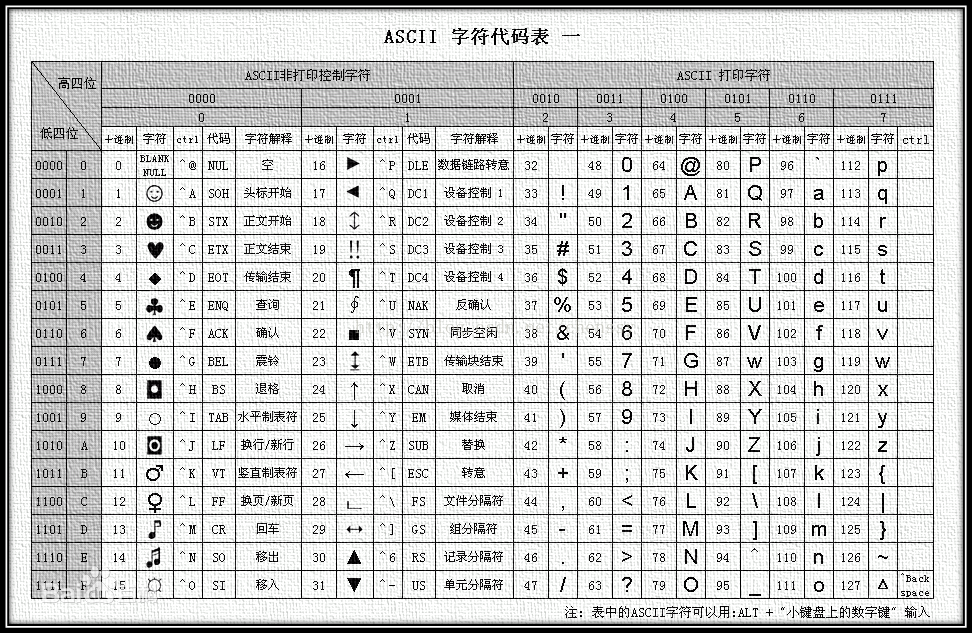
一个字节,8个比特位,2*8 = 256,即一个字节最多可以标识256个字符。这对于西方国家来说是完全够用的。
后来随着计算机在全世界范围的普及与发展,越来也多语言需要在计算机上标识,一个字节的所表示的字符远远不够用。
于是基于中文的编码,1980年,中国国家标准总局发布了GB2312,其中收录了7000多个汉字。
1995年,GB18030 可以存2万多个汉字现在常用中文编码GBK,且Windows中文模式默认编码为GBK,不是utf-8
国际标准编码为 Unicode,其中,一个汉字或者英文字母都占两个字节。
utf-8 是以Unicode为基础的扩展集,是可变长的字符编码集,其中英文字符占一个字节,一个汉字占3个字节。
其中详细的分配关系可以看这里:https://cloud.tencent.com/developer/article/1343240
python中,二进制和字符串的转换
python 3.x 不支持字符串和二进制的拼接,因此两者之间的操作之前,需要进行转换。


1 msg = "我爱北京天安门" 2 print(msg.encode("utf-8")) // 字符串转换成二进制 3 4 msg_en = b'\xe6\x88\x91\xe7\x88\xb1\xe5\x8c\x97\xe4\xba\xac\xe5\xa4\xa9\xe5\xae\x89\xe9\x97\xa8' 5 print(msg_en.decode("utf-8")) // 二进制 转换成 字符串
三种格式匹配输出
1 # @Author : Hozi 2 # @Time : 2020/3/3 16:34 3 4 # 读取输入 , 此处默认都是str类型。 5 name = input("name:") 6 age = input("age:") 7 job = input("job:") 8 salary = input("salary:") 9 10 # 格式输出的三种方式 11 # 直接拼接法。(最好不要用拼接) 12 info = """ 13 --------- info of """+name +"""--------- 14 name :""" + name + """ 15 age :""" + age + """ 16 job :""" + job + """ 17 salary:""" + salary 18 19 print(info) 20 21 # 占位符方法 22 info2 = """ 23 --------- info of %s--------- 24 name :%s 25 age :%s 26 job :%s 27 salary:%s 28 """ % (name, name, age, job, salary) 29 30 print(info2) 31 32 # .format()方法 33 info3 = """ 34 --------- info of {_name}--------- 35 name :{_name} 36 age :{_age} 37 job :{_job} 38 salary:{_salary} 39 """.format( 40 _name=name, 41 _age=age, 42 _job=job, 43 _salary=salary) 44 45 print(info3)
第三方库 os 和 sys
1 # @Author : Hozi 2 # @Time : 2020/3/3 19:15 3 4 import sys 5 print(sys.path) # 打印环境变量 6 7 print(sys.argv) # 是一个从程序外部获取参数的命令,其是一个列表。 8 """ 9 test.py 文件中内容 : a = sys.argv; print(a) 10 在命令端执行: 11 输入 test.py --> 文件路径 12 输入 test.py 0,1,2 --> ['文件路径','0','1','2'] 。 若代码改为 a = sys.argv[1],此处输出为 0 13 14 """ 15 import os 16 # print(os.system("dir")) # 查看当前文件所在目录,只执行,不保存结果 17 18 # cmd_res = os.popen("dir").read() # 查看当前文件所在目录,执行且保存结果到cmd_res中 19 # print(cmd_res) 20 21 os.mkdir("new_dir") # 在当前目录新建文件夹。