一:面向对象编程
面向对象编程——Object Oriented Programming,简称OOP,是一种程序设计思想。OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
面向过程的程序设计把计算机程序视为一系列的命令集合,即一组函数的顺序执行。为了简化程序设计,面向过程把函数继续切分为子函数,即把大块函数通过切割成小块函数来降低系统的复杂度。
面向过程:核心在“过程”,分析出解决问题的步骤,先干什么,后干什么;优点是流程化,进而简单化;缺点是可扩展性差
面向对象的程序设计把计算机程序视为一组对象的集合,而每个对象都可以接收其他对象发过来的消息,并处理这些消息,计算机程序的执行就是一系列消息在各个对象之间传递。
面向对象:核心在“对象”,分析解决问题需要哪些“人”,然后创造出这些对象,让他们自己去把问题解决。优点是扩展性强
面向对象三大特点:数据封装,继承和多态
二:对象与类
对象:是人们要进行研究的任何事物,是特征与行为(功能)的结合体,即包含了数据与对数据的操作
类(class):用来描述具有相同的属性和方法的对象的集合;它定义了该集合中每个对象所共有的属性和方法
可以说,对象的抽象是类,类的具体化就是对象,即对象是类的实例
# 在程序中必须先定义类,才能创建对象
# 程序执行到类的定义时,先产生类的名称空间,然后会执行类里面的代码块,并把产生的名字放入该名称空间
class OlyStudent: # 定义类使用关键字class
school = 'oly' # 对象的共有属性
def learn(self): # 对象的共有方法;参数self为对象本身,必须得有;被调用时python会自动传入对象参数
print('%s is learning' %self.name)
def __init__(self,name,age,sex): # 此方法为对象创建个性化的属性;调用类时就会触发此方法的执行
self.name = name
self.age = age
self.sex = sex
# 调用类创建类的实例--对象
stu1 = OlyStudent('rock',18,'male') # 调用类,创建对象名称空间,触发__init__(self,'rock',18,'male'),将产生的名字放入对象名称空间
stu2 = OlyStudent('lula',28,'female')
print(stu1.school) #调用对象某个属性,会先在该对象的名称空间找,找不到就去对应类的名称空间找
# 查看类与对象名称空间的名字及其对应的值
print(OlyStudent.__dict__)
print(stu1.__dict__) # {'name': 'rock', 'age': 18, 'sex': 'male'}
# 属性的增删查改
print(stu2.school) # 使用点号的语法调用对象的属性和方法 查
OlyStudent.school = 'pku' # 是已有属性则改值,没有该属性则增加此属性 增/改
del stu1.sex # 删除某属性
print(stu1.__dict__) # {'name': 'rock', 'age': 18}
访问限制:
class Foo:
def __init__(self,name,password):
self.__name = name # 将属性名命名为以__开头,这样这个属性就成了对象的私有变量,无法通过外部访问
self.__password = password
def ger_name(self): # 可以通过增加这种方法来方便从外部访问到对象的私有变量
return self.__name
def get_pwd(self):
return self.__password
foo1 = Foo('rock','123')
# print(foo1.__name) # AttributeError: 'Foo' object has no attribute '__name'
# print(foo1._Foo__name) # rock python解释器自动把__name转成了_Foo__name,但不建议这样访问该属性!!!
# print(foo1.__dict__) # {'_Foo__name': 'rock', '_Foo__password': '123'}
print(foo1.ger_name()) # rock
print(foo1.get_pwd()) # 123
三:类的继承
新定义一个类,可以继承自某个或某几个已有的类;新的类叫子类(Subclass),被继承的类叫基类、父类或超类(Base class,Super class)
class OlyPeople: # 父类是对子类的再抽象,提取出各子类共同的属性和方法,这样可以减少重复代码
school = 'oly'
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
def f1(self):
print('f1 from OlyPeople')
# 子类继承自父类,最大的好处是子类继承了父类的所有功能,即子类可以使用父类的所有属性和方法
class Teacher(OlyPeople): # 括号中传入其父类,建立父子类关系;可以传入多个父类,即与多个父类建立父子类关系
def __init__(self,name,age,sex,level,salary): # 子类可以定制自己的属性和方法,若与父类发生名字冲突,会覆盖继承而来的
super().__init__(name,age,sex) # 得到父类中已定义的属性,避免重复定义,产生冗余代码
self.level = level
self.salary = salary
def teach(self):
pass
def f1(self):
print('f1 from Teacher')
tea1 = Teacher('rock',18,'male',9,25) # 调用类创建对象,会自动触发__init__()的执行,若类中没有,会去其父类中找该函数
print(tea1.school) # 得到继承自父类的属性school
tea1.f1() # 对象调用一个属性与方法查找顺序:始终先从对象自己的名称空间找,没有再去其对应类中找,还没有再去类的父类中找
# 以上执行结果 oly;f1 from Teacher
'''
对象调用一个属性与方法的查找顺序:
对象自己的名称空间 --> 对应类的名称空间 --> 父类的名称空间 --> 父类的父类的名称空间... --> object
'''
'''
继承自object类的子子孙孙类,都叫新式类;python3中的类全是新式类,没有指定继承类的默认继承自object类
不是继承object类的所有类,都叫经典类;Python2中有经典类
'''
class Foo: # python3中默认为 class Foo(object):
pass
'''
新式类与经典类的主要区别在于查找对象的属性和方法(菱形继承结构,即其父类有同一祖先)
新式类:广度优先,一条分支找下去,不找那个共同祖先,然后去下条分支找,最后去共同祖先那找
经典类:深度优先,一条分支找下去,直接找到共同祖先那,然后去下条分支找。。
'''
Foo.mro() # 可列出对象能调用的名字在类及其父类中的查找路径
多继承名字查找:(新式类:广度优先)
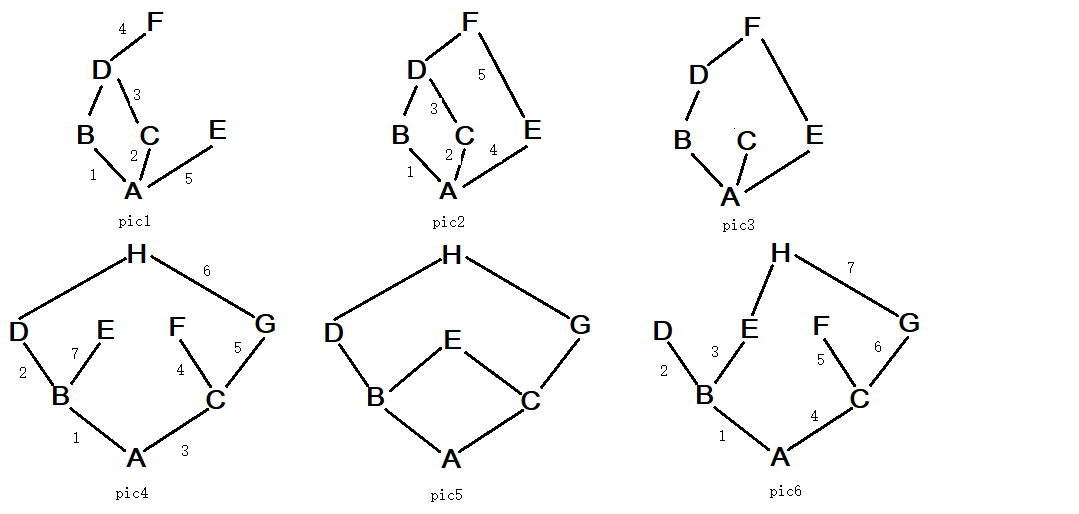
print(A.mro()) # 查看名字在多继承结构中的查找顺序 #图3:[<class '__main__.A'>, <class '__main__.B'>, <class '__main__.D'>, <class '__main__.C'>, <class '__main__.E'>, <class '__main__.F'>, <class 'object'>] #图5这种结构会报错 #TypeError: Cannot create a consistent method resolution #order (MRO) for bases H, E
四:类的数据封装
class Foo:
def __init__(self,name,age): # 此处使用构造方法把数据封装到对象中(这就是面向对象的数据封装方式)
self.name = name
self.age = age
def user_info(self):
print('name:%s age:%s' %(self.name,self.age))
obj1 = Foo('rock',18) #调用类创建对象,自动执行__init__(),把数据name='rock' age=18 封装到对象obj1中
print(obj1.name,obj1.age) # 通过对象调用属性的方式直接获取封装的数据
obj1.user_info() # 通过self参数间接获取封装的数据
五:类的多态
# Python不支持Java和C#这一类强类型语言中多态的写法,但是是原生多态,Python崇尚“鸭子类型”。
# 动态语言的“鸭子类型”:一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被看做是鸭子。
# 多态:多种形态,即多种类型
class Animal:
def run(self):
print('Animal is running')
class Dog(Animal):
def run(self):
print('Dog is running')
class Duck_like: # 虽然不属于Animal类,但具有与Animal类相同的方法run(),所以其对象也可以调用run_twice()方法
def run(self): # 这就是“鸭子类型”
print('Duck_like is running')
def run_twice(animal):
animal.run()
animal.run()
run_twice(Animal()) # Animal对象属于Animal类,即一种形态
run_twice(Dog()) # Dog对象属于Dog类,也属于Animal类,即具有二种形态
run_twice(Duck_like()) # 从python中的run_twice()方法角度看属于 “鸭子类型”
# run_twice()方法设定的是接收Animal类,但其子类也属于Animal类,所以run_twice()就具备了同时接收其他类型(Animal子类或鸭子类型)的能力
# Animal is running
# Animal is running
# Dog is running
# Dog is running
# Duck_like is running
# Duck_like is running
class Tiger(Animal): # 新增Animal子类
def run(self):
print('Tiger is running')
run_twice(Tiger()) # 我们只需知道Tiger对象属于Animal类,就可以调用run_twice()方法,而不用管具体实现细节
# Tiger is running
# Tiger is running
# Python多态符合“开闭”原则
# 对扩展开放:允许新增Animal子类
# 对修改封闭:不需要修改依赖Animal类型的run_twice()等函数。