1. 索引
1.1 B+ Tree索引
答:InnoDB默认的索引方式。有序索引,将相邻数据都存在一起,把随机IO变成顺序IO。
1.1.1 底层数据库为什么用B+树
答:总结:
- B+树的数据全部存储在叶子结点中,B树的非叶子节点也会存储数据。使得B+树的查询是从root到叶子节点。
- B+树的内部结点比B树更小,读写代价小。
1.1.2 聚簇索引(主索引)和非聚簇索引(辅助索引)
答:B+ Tree索引分为主索引和辅助索引。
- 聚簇索引(主索引):叶子结点存储整行数据。直接找key就能获得数据。一个表只能包含一个主索引。
- 非聚簇索引(辅助索引):叶子结点存储主键的值。需要先取得主键,再用此主键走一遍主索引。
1.1.3 回表
答:回表就是指普通索引查询,先搜索普通索引树获得主键值,再到主键索引树搜索一次。
1.2 哈希索引
答:以O(1)时间搜索,但无法排序分组,只能精准查找。
自适应哈希索引:当某个索引被频繁引用时,在B+树索引上再创建一个哈希索引,提供快速查找。
1.3 全文索引
答:MyISAM支持全文索引,用于查找文本中的关键词,match against查找。5.6.4版本后InnoDB也支持。
1.4 索引优化
1.4.1 索引列顺序
答:把选择性最强的索引放在前面。索引选择性=不重复的索引值 / 记录总数。
1.4.2 覆盖索引
答:覆盖索引是select的数据列只用从索引中就能够取得,不必读取数据行,即查询列要被所建的索引覆盖。
1.4.3 前缀索引
答:根据选择性,只索引字符串的最左M个字符。
1.4.4 索引下推
答:联合索引时,在遍历索引时,先对其余其他字段判断,过滤不满足条件的记录,减少回表次数和数据数量。
1.5 索引使用情景
答:
- 经常需要条件查询的列且有区分度,可以建立索引。
- 小型表,不需索引,全表扫描就可。中到大型表,推荐索引。
- 特大型表,索引的建立和维护代价过大,不如用分区技术。
2. 存储引擎
答:MySQL是一个关系型数据库,默认端口号是3306。5.5前用MyISAM,5.5后用InnoDB。
2.1 InnoDB
答:5.5版本后的默认引擎。默认可重复读的事务隔离级别,主索引是聚簇索引,内部做了诸多优化(插入缓冲区、哈希索引等),支持热备份。
2.2 MyISAM
答:5.5版本前的默认引擎。
2.3 MyISAM和InnoDB区别
答:区别如下:
- 行级锁。MyISAM只支持表级锁,InnoDB支持表级锁和行级锁。
- 事务支持。MyISAM不支持事务,InnoDB提供事务支持和崩溃恢复。
- 外键。MyISAM不支持外键,InnoDB支持外键。
- InnoDB支持多版本并发控制,可以处理大量数据。
- MyISAM支持全文索引。
总结一下:InnoDB支持行级锁、事务、外键。
3. 事务
答:事务就是逻辑上的一组操作,要么都执行,要么都不执行。
3.1 四大特性ACID
答:ACID。
- 原子性(Atomicity):事务是最小的执行单位,要么全部执行,要么全部不执行。
- 一致性(Consistency):保证数据库状态要一致,多个事务对同一数据读取结果是相同的。
- 隔离性(Isolation):多个事务并发,各个事务是不受其他事务干扰的。
- 持久性(Durability):一个事务一旦提交,此修改在数据库中是持久保存的。
3.2 并发事务的问题
- 脏读(Dirty read):事务A读取了事务B修改未提交的数据,B回滚,A的数据不一致。
- 丢失修改(Lost to modify):事务A和B同时读取数据,A修改后先提交,B修改后再提交会将A的修改覆盖。
- 不可重复读(Unrepeatable read):事务A两次读取数据间,有事务B修改更新,导致两次读取数据不一致。
- 幻读(Phantom read):事务A两次读取数据间,有事务B增加了记录,导致两次读取数据记录数不一致。
注:幻读指结构上发生变化。不可重复读指数值上发生变化。
3.3 隔离级别
答:MySQL定义了四个隔离级别。
- 读未提交(Read-Uncommitted):最低级别,允许读取尚未提交的数据。会发生脏读、幻读、不可重复读。
- 读已提交(Read-Committed):允许读取已经提交的数据。阻止脏读。
- 可重复读(Repeatable-Read):读事务时禁止写事务,写事务时阻止一切。阻止脏读和不可重复读。InnoDB默认隔离级别。
- 可串行化(Serialization):最高级别。所有事务依次执行,不会互相干扰。阻止三个事务问题。
4. 锁机制
4.1 按粒度分
答:分为表级锁和行级锁。
- 表级锁:粒度最大的锁。对整张表加锁,资源消耗少,加锁快,不会死锁,但锁冲突概率高。
- 行级锁:粒度最小的锁。对当前操作行加锁,加锁慢,开销大,会死锁,但大大减少冲突。
4.1.1 常见行级锁
答:有三种。
- Record Lock:单行锁,锁定符合条件的行。
- Gap Lock:间隙锁,锁定一个范围,不含记录本身。
- Next-key Lock:Record+Gap,锁定一个范围,含记录本身。
4.1.2 表级锁使用场景
答:当事务比较复杂,使用行级锁容易死锁回滚。更新大表的大部分数据,表级锁效率更好。
4.1.3 行级锁何时会锁住整张表
答:更新的列没有建立索引,会直接锁住整张表。
4.2 按是否可写分
答:可以进一步划分为共享锁和排他锁。
- 共享锁(Shared Lock):读锁。锁定的资源能被其他用户读取,但不能修改,直到资源上的S锁全部被释放。
- 排他锁(Exclusive Lock):写锁。事务T对数据A加X锁,则只允许T读取修改,直到X锁释放。在更新操作,如insert、update 或 delete时,始终应用排它锁。
4.3 死锁
答:MySQL中的死锁是多个事务使用行级锁对某行数据加锁造成。
4.3.1 解决方案
答:分为两个方面。
业务层面:
- 指定锁的获取资源顺序。(操作系统中的哲学家就餐问题)
- 同一个事务一次锁定尽可能多的资源。
- 事务拆分成小事务。
数据库设置:
- 设置超时时间。InnoDB默认是50s。
- 开启死锁检测。发生死锁时,回归死锁链上一个事务,让其他事务继续执行。
4.4 悲观锁和乐观锁
答:分为:
- 悲观锁:利用数据库的锁机制实现,再整个数据处理过程都加锁,保证排他性。
- 乐观锁:CAS实现。按照当前事务的数据和数据表中数据是否一致,来决定是否执行操作。
4.4.1 乐观锁的ABA问题
答:加入数据版本记录机制或者使用时间戳。
ABA问题:事务X读取数据A时,事务Y修改成B,又修改回A,事实上数据发生过改变的,存在并发问题,但事务X无法得到数据发生过变化。
5. 大表优化
答:单表记录数过大时,数据库性能下降明显,需要进行一系列的优化。
5.1 限定数据范围
最简单的手段,限制数据范围条件来查询数据。
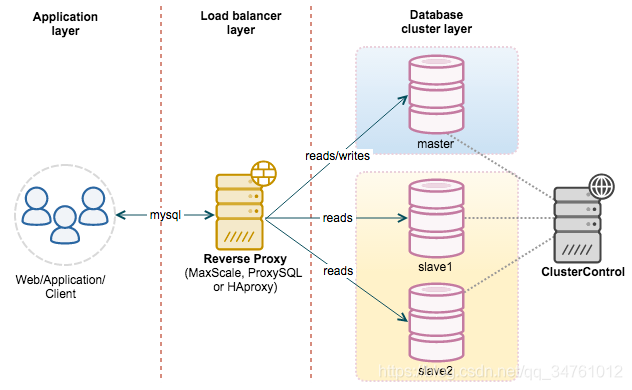
5.2 读写分离
主服务器处理写操作或实时性高的读操作,从服务器处理读操作。
- 实现方式:增设代理服务器,决定将应用传来的请求转发到哪个服务器。
- 原因:极大减少了锁的争用;用冗余换可用性;从服务器可用MyISAM节约资源。
5.3 水平拆分
水平拆分将一张表A拆分成多个相同结构的表a1,a2,a3存储,每个子表只占一部分数据。
又细分为库内分表和分库分表。
- 库内分表:子表仍在一个数据库实例中,仍要竞争同一个物理机资源。
- 分库分表:子表分散在不同数据库中。
优点:业务改造简单;解决了单表数据量过大的问题。
缺点:跨库的一致性难保证;join关联性能差;扩容和维护难度过大。
5.4 垂直拆分
又细分为垂直分库和垂直分表。
- 垂直分库:基于业务划分数据库,让每个业务都有独立数据库。
- 垂直分表:基于数据表的列切分,把一张列1-7的表拆成列1-4和列1 5-7的表。
优点:业务解耦;高并发下提升了性能。
缺点:增加了业务复杂度;主键冗余;数据量过大仍未解决,需要配合水平拆分。
5.5 拆分后的问题
- 事务一致性
两阶段提交性能较差。通常追求最终一致性,出现问题进行事务补偿。 - 分页和排序
排序字段非分片字段,需要先子表内排序,再汇总排序,最后返回给用户。 - 全局唯一主键
子库的自增主键满足不了需求,所以使用分布式ID用作全局唯一主键。
注:所以推荐使用成熟的中间件,如sharding-jdbc,Atlas,Cobar
6. MySQL架构和执行流程
6.1 基础架构
答:MySQL主要分为Server层和存储引擎层。
- Server层:跨存储引擎的功能都在此实现,如视图、触发器、函数等,有一个binlog日志。
- 存储引擎:负责数据的存储和读取。常用的是InnoDB,自带redolog模块。
6.2 基本组件
答:Server层有五个主要组件。
- 连接器:身份验证和权限设置。
- 查询缓存:执行查询语句前,先查有没有缓存的结果集。(8.0后废弃)
- 分析器:没有命中缓存,则进入分析器进行词法和语法分析。
- 优化器:按照MySQL认为最优的方案执行。
- 执行器:用户有权限,则调用存储引擎,执行语句。
6.3 执行流程
6.3.1 查询语句
权限校验---->查询缓存---->分析器---->优化器---->权限校验---->执行器---->引擎
6.3.2 更新语句
分析器---->权限校验---->执行器---->引擎---->redo log prepare---->binlog---->redo log commit
以修改张三的年龄为例:
- 先查询到张三这条数据,如果有缓存,用缓存。
- 拿到查询的语句,把 age 改为 19。
- 调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态。
- 通知执行器,执行完成,可以提交。
- 执行器收到通知后记录 binlog,调用引擎接口,提交 redo log 为提交状态。
- 更新完成。
7. 日志模块和关键字区分
7.1 日志模块
答:MySQL主要有redolog和binlog。
- redolog(重做日志):InnoDB特有,物理日志。记录哪个数据页做了修改。
- binlog(归档日志):Server层自带,逻辑日志,记录本次修改的SQL语句。通常使用row二进制格式,保证数据记录的准确性。
7.1.1 redolog和binlog的两阶段提交
答:用两阶段提交是为了保证数据一致性。redolog prepare引擎数据保存 -> binlog执行器收到信号 -> redolog commit执行器调用
针对此种提交方式发生异常宕机,MySQL先判断redolog是否完整,完整则直接提交。redolog只是prepare状态,查看binlog是否完整,完整就继续提交redolog,否则回滚事务。
7.1.2 MySQL为什么会突然慢一下
答:更新数据库时,先写日志,等合适时间再更新磁盘。当redolog写满,需要flush脏页,将数据写入磁盘,这是会使执行速度慢一下。
7.2 where、group by和having关键字
答:三个关键字总结为:
- where用来筛选from子句中产生的行;
- group by用来分组where子句的输出;
- having用来从group by分组结果中筛选行。
7.2.1 where和having差别
答:where用在分组前,针对行。having用在分组后,针对组,能用max、avg等聚合函数。
7.2.2 执行顺序
where找符合条件的数据---->group by分组---->聚集函数计算每个组---->having去掉不合要求的组
8. 优化
参考 https://www.cnblogs.com/huchong/p/10219318.html 作者:听风。
