Set接口
Set集合继承自Collection集合
类似数学中的集合概念;特点:集合中元素不能重复,且元素无序排列
无序排列理解:元素所在的位置与向集合中添加元素的顺序没有关系
元素不重复原因:底层数据结构是一个哈希表,能保证元素是唯一的,元素不重复!!!
它通过它的接口子实现类HashSet集合去实例化,而HashSet集合底层是HashMap集合的实例!!!
实例1
package org.westos_01;
import java.util.HashSet;
import java.util.Set;
public class SetDemo {
/**
* 说明问题:
* 1)Set集合元素不重复(从打印的内容以及集合元素个数)
* 2)集合元素无序(添加的顺序与打印的顺序)
* 3)添加、增、删、查询方法的使用---这四个方法的返回值类型都是boolean类型
* 4) Set集合存储字符串元素并遍历---for增强循环(jdk5后的版本)
*/
public static void main(String[] args) {
//创建Set集合对象
Set<String> set = new HashSet<String>() ;
//添加元素(增)
set.add("hello");
set.add("java") ;
set.add("java") ;
set.add("world") ;
set.add("world") ;
set.add("world") ;
System.out.println("集合中添加的元素:"+set);//打印的是内容(原因:传入参数类型是String,底层重写了toString()方法)
System.out.println("集合中元素的个数:"+set.size());
//增强for遍历
for(String s :set){
System.out.println(s);
}
//删除元素(删)
System.out.println("是否成功删除:"+set.remove("hello"));//删除是否成功
System.out.println("删除后集合中的元素:"+set);
//查询
System.out.println("是否包含此元素:"+set.contains("hello"));
}
}
HashSet类
特点:按照哈希算法(了解这个算法)来存取集合的元素
此类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 Set 的迭代顺序;特别是它不保证该顺序恒久不变。
注:HashSet有一个子类:LinkedHashSet类
存取和查找的机理
机理:当向集合中添加一个元素时,HashSet会调用对象的hashCode()方法获取哈希码,然后根据这个哈希码进一步计算出对象在集合中存放的位置。
问题1 为什么能保证HashSet集合元素唯一?
当创建一个HashSet集合的对象时,会先调用其构造方法(蓝框标记)看源码1
即:
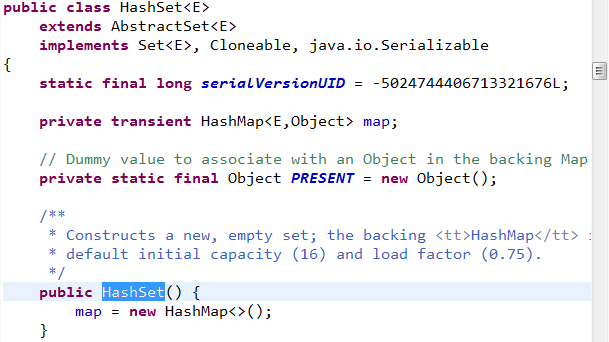
源码说明:可以看到实际上是创建了一个HashMap类对象的实例,map是HashMap类对象的实例
此时add()添加元素,看对应的源码2

源码说明:其实是调用了HashMap的put方法
看HashMap的put()方法的源码3

源码说明:调用了HashMap中的hash()方法和putVal()方法
看hash方法(重要)的源码4

源码说明:携带hashSet集合元素key,调用对象(传入参数类型)的hashCode()方法,进行位运算;涉及到Object类hashCode()方法重写
看putVal()方法(具体用处不知,后续会提到)
源码5
package 测试集;
import java.util.HashMap.Node;
import java.util.HashMap.TreeNode;
public class Demo {
//对putVal方法说明
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K, V>[] tab;
Node<K, V> p;
int n, i;
/* 第一步
* 判断哈希表是否存在,如果不存在,创建一个哈希表
*/
if ((tab = table) == null || (n = tab.length) == 0)
/* 当new HashMap实例时,
* 并没有初始化其成员变量transient Node<K,V>[] table;,
* 也就是说并没有为table分配内存,
* 只有当put元素时才通过resize()方法对table进行初始化。
* */
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K, V> e;
K k;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0;; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果hash码相同,则调用相应的集合元素(元素参数类型)的equals()方法判断,涉及到equals()方法的重写
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//如果没有找到该key的结点,则执行插入操作,需要对modCount增1。
if (++size > threshold)
resize();//在执行插入操作之后,如果size超过了threshold(阈值容量),这要扩容。
afterNodeInsertion(evict);
return null;
}
}
/**
(1)通过hash值得到所在bucket的下标,如果为null,表示没有发生碰撞,则直接put;散列表中的slot通常称为bucket
(2)如果发生了碰撞,则解决发生碰撞的实现方式:链表还是树。
(3)如果没有找到该key的结点,则执行插入操作,需要对modCount增1。
(5)在执行插入操作时,如果bucket中bin的数量超过TREEIFY_THRESHOLD,则要树化。
(6)在执行插入操作之后,如果size超过了threshold,这要扩容。
*/
源码说明:根据获取的hashCode进一步计算对象是否重复
源码6----table 哈希表

源码说明:当new HashMap实例时,并没有初始化其成员变量table(也即并没有为table分配内存)。只有当put元素时才通过resize方法对table进行初始化
源码7----resize()方法(随后补充)
相关链接:1 点击打开链接(比较好),2 点击打开链接,3 点击打开链接,4 点击打开链接,5 点击打开链接,6 点击打开链接
HashSet集合的add()方法,底层是依赖于双列集合HashMap<K,V>的put(K key,V value)来实现的
put(K key,V value):
底层又依赖于HashCode()和equals()方法,传递添加元素的时候,首先判断的是
每一个元素对应的HashCode值是否一样,如果HashCode值一样,还比较他们的equals()方法,由于现在集合存储的是String类型,String类型本身重写了equals()方法,所以,默认比较的是内容是否相同,如果内容相同,这里最终返回的就是第一次存储的那个元素,由这两个方法保证元素唯一性!