前面一节我们初步学习了HDFS,仅停留在那个阶段是不行的,我们还要深入学习HDFS架构,学习其工作原理,这节课我们便一起来学习HDFS的架构。
首先,我们来看一下Hadoop1.0和Hadoop2.0伪分布式架构下HDFS的组成,如下图所示,我们可以看到,HDFS架构由NameNode(负责管理节点)、DataNode(负责存储数据)、Secondary NameNode(它不是NameNode的热备份,即当NameNode挂掉之后,Secondary NameNode是无法代替NameNode进行工作的,它只是NameNode的一个秘书而已,帮助NameNode处理一些琐碎的事情)。

接下来我们看一下HDFS架构图,如下图所示,客户端(Client)想从HDFS系统中读取数据,它要与NameNode打交道,Client与NameNode进行一些元数据的操作(Metadata ops)后,NameNode会查询自己的元数据信息,这些元数据信息保存在内存和本地磁盘当中,放在内存中是为了查询迅速,但是内存致命的缺点是设备掉电后内存中的内容都消失了,这对我们来说简直是无法忍受的,因此为了数据的安全,还在本地磁盘保存了一份数据,本地磁盘保存的数据是元数据的镜像。NameNode会返回给Client一些元数据(Metadata),元数据这个概念可能大家不太明白,这里举个通俗的例子,比如你去图书馆借书,图书管理员会把你的借书信息存入电脑,借书信息包括书的名称、作者、版本、借书人的名字、借书时间,归还截止时间等,那么我们说像这样的数据就叫元数据,也就是说我们通过这样的数据能够清楚明了的知道我们想知道的信息。Client在获取到这些元数据后便知道它要读取的内容在哪些DataNode上了,接下来Client便开始找对应的DataNode进行读取数据,这里有一点需要说明的是,Client在读取数据时有一种机架感知感应,即Client会从离自己最近的保存有它要读取数据的DataNode上读取数据(比如说,现在有两个DataNode都存有Client想要读取的数据,其中一个与Client只隔着一台交换机,另一个与Client则隔着3台交换机,那么Client便会从离它近的那个DataNode上读取数据,这就是机架感应)。假如读取的文件大小是512M,按照分块的思想,它被分成了4个区块存储,那么Client在读取数据的时候只能先读取第一个区块然后再读取第二个区块,以此类推,直到读完四个区块的内容,这样做也是为了防止在读取到中间某个区块的时候突然出现故障而不得不从头开始读的情况,分块挨个读取的话,即使某个区块发生了问题,我们只需重新从那个区块读取数据即可,前面读取过的就不用再重复读取了。
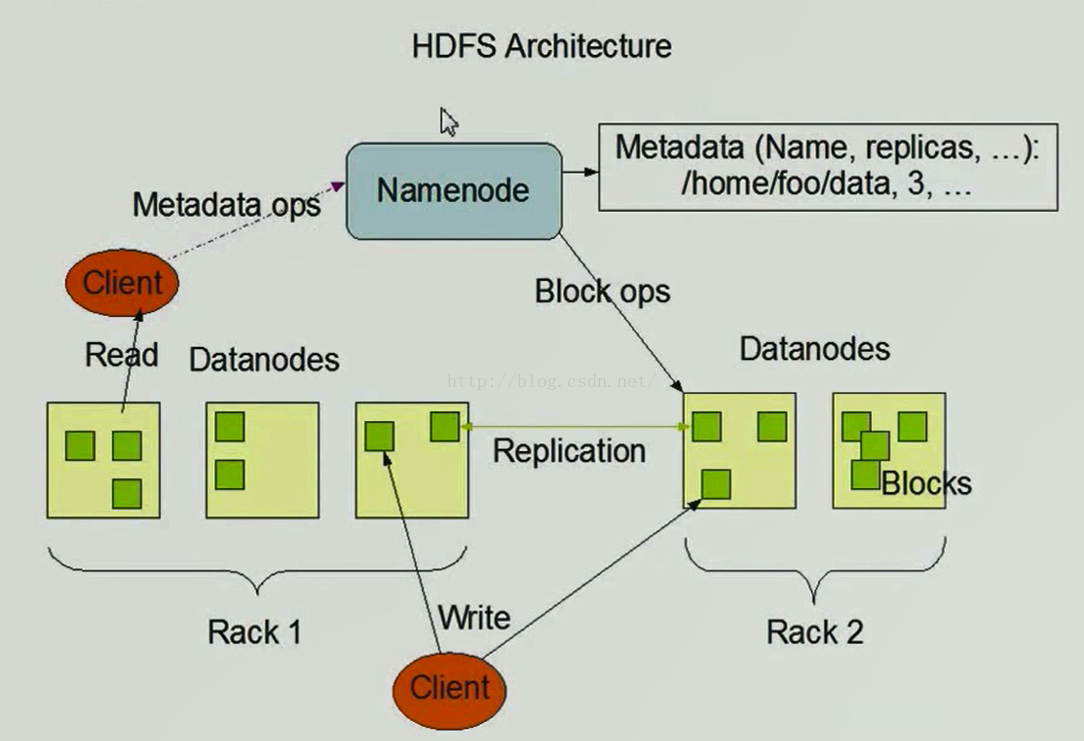
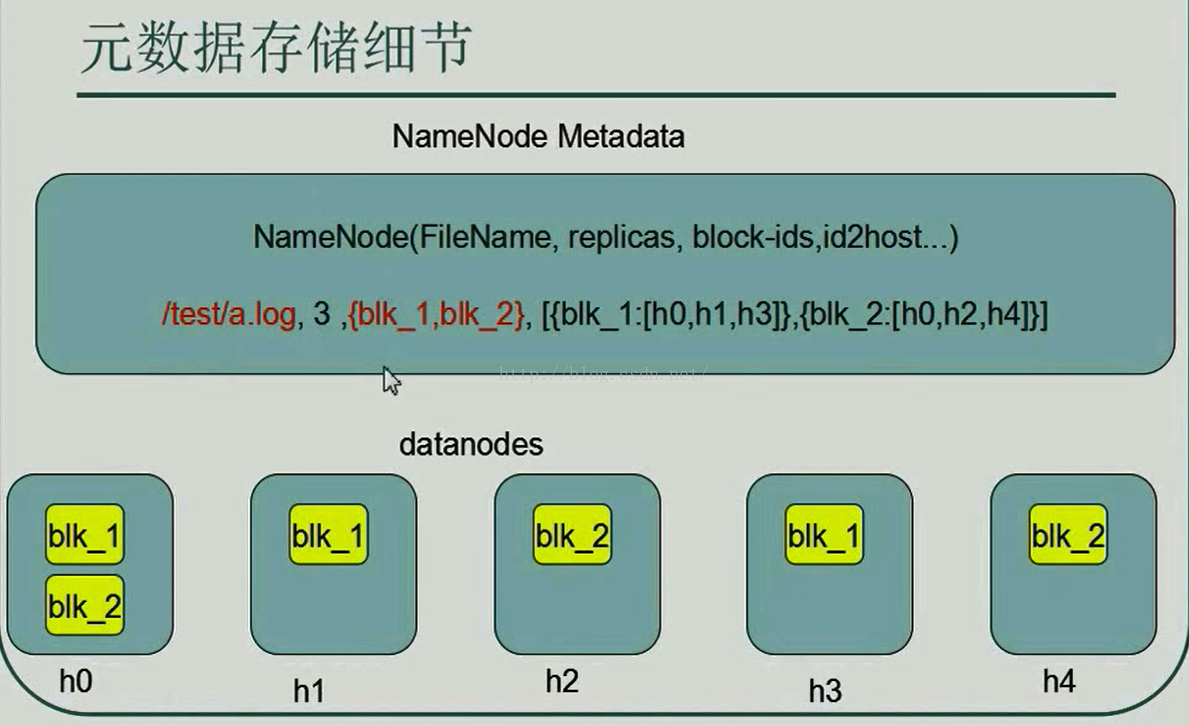
上图中我们说Client向NameNode申请读取数据的请求时,NameNode会查看自己的元数据信息,元数据信息示意图如下图所示,NameNode的元数据信息有很多内容,这里只列举出了其中的几个重要的信息,比如FileName(文件名)、replicas(副本数量)、block-ids(文件被切割成的区块数量及区块组成),id2host(区块都在哪些DataNode上)等。
下图中还举了个例子,在/test目录下有一个a.log文件,这个文件默认的副本数量是3,这个文件的文件由blk_1和blk_2两个区块组成,blk_1这个区块在h0、h1、h3这三个地址中保存着,blk_2这个区块在h0、h2、h4这三个地址中保存着。Client拿到这个元数据信息后,便可以选择区块进行读取或下载了,现在假如Client要下载这个a.log文件,而我们的Client客户端离h1比较近,那么Client便先从h1上读取blk_1,读取完blk_1之后便从h2上读取blk_2,如果在读取blk_2时发生错误,那么Client再查询元数据信息发现h0和h4上也有blk_2区块,因此它便根据机架感应(即就近原则)选择较近的区块读取blk_2。
那么,我们可能要有疑问了,既然Client能知道读取某个区块是否成功,那么肯定是有一套机制的,它用到的便是CRC32校验和机制,原理是:每个文件的每个区块都有一个原始的校验和值,我们在把这个文件上传到HDFS系统的时候元数据便保存了这个初始值,如果后续这个文件的某个区块发生任何变化,那么这个校验和的值便会发生变化,那么当Client读取这个文件的这个区块的时候如果发现校验和已经发生了改变,那么说明这个文件很可能已经被损坏了。
接下来我们具体学一下NameNode、DataNode、Secondary NameNode分别是干什么用的,具体的工作原理是什么。NameNode维护着整个系统的文件目录树,这样当客户端发送过来请求的时候,它便可以迅速做出回应,告诉客户端这个文件在哪些DataNode上存放着。当然,如果用户想向HDFS系统的某个目录上传文件,它也会记录下来这个文件的存放目录。
NameNode中包含fsimage(元数据镜像文件)、edits(操作日志文件)、fstime(保存最近一次恢复的时间)。前面我们说了NameNode为了保证数据的安全性,除了在内存中保存着一份数据外,在本地磁盘上保存着一份元数据镜像文件,就是fsimage,但是fsimage并不是与内存中的数据实时同步的(Hadoop2.0已经可以实时同步了,我们这里说的是Hadoop1.0和Hadoop2.0的伪分布式),它存储的只是一段时间内的内存数据。edits文件保存着用户的操作信息,比如上传了一个文件或下载了一个文件,上传成功了或者失败了等都会记录到该文件中。fstime保存的是还原点的时间,这里我们举个例子,假如你5月1号买了一台电脑,你在5月6号做了一个还原点,当你用到5月20号的时候发现电脑中病毒了,那么你需要把电脑还原到5月6号的状态,当然5月6号到5月20号这之间的数据便会丢失了。由于是在5月20号做的还原,那么fstime便记录了这个时间。所以对还原来说并不能保证所有的数据都被保留下来。
上面所说的三个文件都被保存在Linux系统本地磁盘上,大家应该会有疑惑,既然这些文件属于HDFS中NameNode的内容,为什么要保存到Linux系统本地磁盘呢?其实举个例子大家就明白了,比如说,我们使用的电脑,它有休眠功能,当电脑休眠时它会把电脑运行的信息序列化到本地磁盘当中,当电脑结束休眠重新运行时电脑便会从本地磁盘读取这些数据并还原到休眠前的状态(比如我们休眠前打开了几个网页,结束休眠后还会继续显示这几个网页,但是这些数据却不是让浏览器保存的,而是让本地磁盘保存的)。

接下来我们用实例来验证NameNode内存中的数据被序列化到本地磁盘了,如下图所示,我们便找到了edits和fsimage文件。
Last login: Mon Sep 5 17:51:16 2016 from itcast01
[root@itcast01 ~]# cd /itcast/hadoop-2.2.0/
[root@itcast01 hadoop-2.2.0]# ls
bin etc include lib libexec LICENSE.txt logs NOTICE.txt README.txt sbin share tmp
[root@itcast01 hadoop-2.2.0]# cd tmp/
[root@itcast01 tmp]# ls
dfs nm-local-dir
[root@itcast01 tmp]# cd dfs/
[root@itcast01 dfs]# ls
data name namesecondary
[root@itcast01 dfs]# cd name
[root@itcast01 name]# ls
current in_use.lock
[root@itcast01 name]# cd current/
[root@itcast01 current]# ls
edits_0000000000000000001-0000000000000000002 edits_0000000000000000016-0000000000000000023 edits_0000000000000000117-0000000000000000118 fsimage_0000000000000000116.md5 seen_txid
edits_0000000000000000003-0000000000000000004 edits_0000000000000000024-0000000000000000115 edits_inprogress_0000000000000000119 fsimage_0000000000000000118 VERSION
edits_0000000000000000005-0000000000000000015 edits_0000000000000000116-0000000000000000116 fsimage_0000000000000000116 fsimage_0000000000000000118.md5
[root@itcast01 current]#
我们再来看一张NameNode的工作特点的图片,如下图所示。

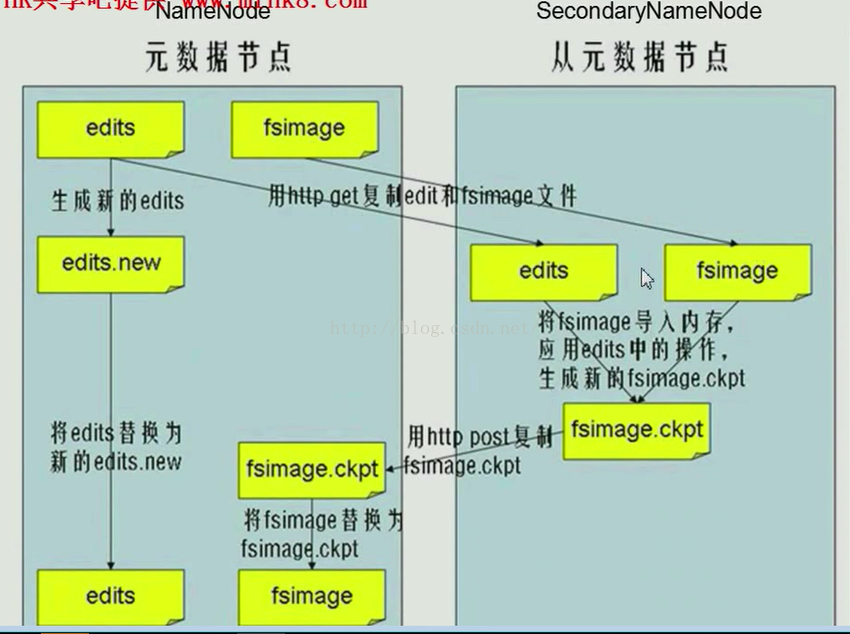
光说理论,没有图的话,总觉得难以理解,现在把NameNode和SecondaryNameNode的工作原理图贴出来,如下图所示,从图中我们可以清楚的知道NameNode中存在着edits和fsimage两种文件,Secondary NameNode是NameNode的秘书,他俩不应该在同一个磁盘上,因为万一磁盘发生损坏,它们两个同时损坏,数据就都丢失了,而如果保存在不同的设备上的话,即使NameNode出现了损坏,Secondary NameNode也可以重新顶上去。当满足一定的条件时Secondary NameNode会采用Http协议的方式从NameNode下载edits和fsimage文件,下载文件前,NameNode会重新生成一个edits文件(edits.new),让后续的操作信息都存到这个新的edits文件当中,旧的edits文件便可以不受新操作的影响,这个过程也叫做切换。,然后将这两个文件加载到内存并进行合并,生成新的fsimage.ckpt,然后将新的fsimage.ckpt推送给原来的NameNode,这时NameNode有两个fsimage,我们用新的fsimage替换旧的fsimage,也就是先删除原来的fsimage,然后把新生成的fsimage.ckpt的后缀去掉改成fsimage。等到fsimage新的文件替换掉旧的fsimage的时候旧的edits文件才会被新的edits文件所替换。这样新的fsimage和新的edits文件都产生了,以后循环往复都这样进行。
上面说到Secondary NameNode当满足一定的条件时会从NameNode下载fsimage和edits文件,那么我们所说的一定条件是什么条件呢?如下图所示,我们可以看到有两种情况,一种是当时间达到3600秒时,另一种是当我们向edits文件写入的数据达到64M时,都会触发checkpoint操作。

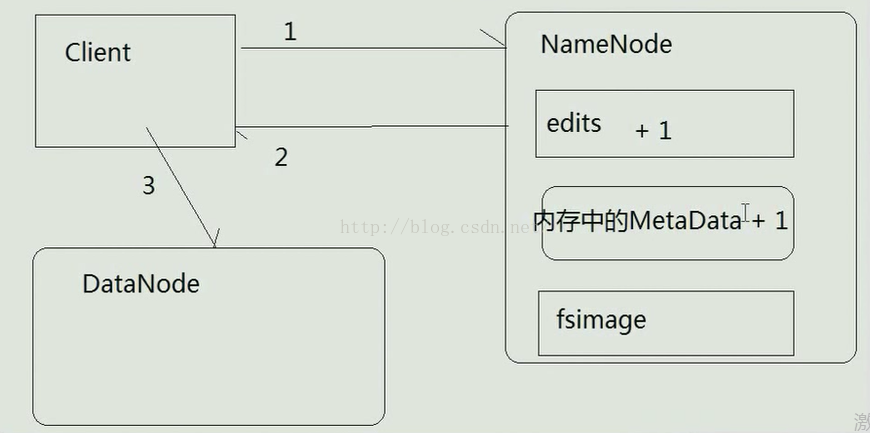
那么为什么我们说fsimage和edits文件合并后就与内存中的Metadata元数据一致了呢?我们以下图为例进行说明,假如Client向NameNode申请上传数据,NameNode告诉Client应该向哪个DataNode上进行上传,上传完一个文件的信息会现在edits文件中记录下来,也就是说edits文件中的记录数相比以前多1,然后再向内存中写入元数据信息,这样内存中的MetaData的数量也加1,而fsimage文件并不会马上就更新数据,需要等待合并时机之后才能更新数据,这样当我们上传完两个文件之后,edits文件和内存中的Metadata中的数据都+2了,当达到合并时机后,fsimage和edits文件进行合并,从而生成了新的fsimage文件,同时edits文件也会生成一个新的文件以记录新的操作信息。这会儿我们发现内存中的Metadata的元数据信息就与fsimage中的元数据信息一致了。我们再假如Client过了几天之后又要上传了某个文件,这时由于edits文件先前跟fsimage合并之后并没有任何操作信息,以至于edits文件中元数据的数量是0,而fsimage由于已经经过多次合并,元数据的数量是2,与内存中的MetaData数量一致。但此时我们要上传文件,这样edits文件中元数据的数量会加1(原来是0个,现在变成了1个),内存中的Metadata数据量也会加1(加上原来的2个,变成了3个),但是fsimage这时由于还不到合并的时间,所以它的元数据数量是2,我们发现fsimage和内存中的Metadata数量又不一致了,等到触发合并的时机一到,fsimage和edits文件便又开始合并,合并之后旧的edits被新的edits文件所取代,其内的元数据为空,fsimage的元数据数量变为3,从而与内存中的Metadata元数据数量一致。
说完了NameNode,我们再来说一下DataNode,我们先来看一下关于描述DataNode的图片,如下图所示,DataNode在存储数据时是以文件块为基本单位的,这在前面我们已经说过多次了,文件块默认的大小在Hadoop1.0的时候是64M,但是到了Hadoop2.0的时候大小变成了128M。现在假如我们要向HDFS上传一个147M的文件,因为该文件的大小超过了一个文件块的大小,那么它势必会被分成两个块,第一个块的大小我们可以肯定的知道就是128M,但是第二个块的大小是多少呢?我们一般会想当然的认为既然每个块的默认大小是128M,虽然135M的文件被分割成两部分后第二部分的大小只有19M,那么仍然会申请一个128M的区块进行存储,这种想法其实是不对的,因为要是这样的话,我们上传的小文件都占用那么大的空间,就会造成资源的极大浪费。

为了证明我们上面所说的一个147M的文件上传到HDFS系统所占用的第二个区块的大小只有19M,我们来实际操作一下。
我们先启动Hadoop,如下图所示
启动完之后我们查看当前进程,我们发现NameNode、DataNode、Secondary NameNode都正常起来了。
我们以root根目录下的jdk-7u80-linux-x64.tar.gz文件来进行实验,因为它的大小(147M)超过了128M并且又不到256M,我上面所说的147M就是举的它的大小。
如果我们想使用命令查看一个文件的大小(我们人眼能看得出的大小,比如多少K,多少M,而不是多少字节因为光看多少字节我们看不出到底有多少M)。
下面命令中 ls -lh中的h的意思是human能看懂的方式。
接下来我们看看HDFS系统的根目录下现在都有哪些文件,我们可以使用命令:hadoop fs -ls / 或者使用hadoop fs -ls hdfs://itcast01:9000/来查看,不过我们老写hdfs://itcast01:9000/这串字符串是不是感觉挺烦的,那么你可以直接使用/来代替刚才的那长串字符串。我们可以看到根目录下有四个文件,为了不让这些文件影响我们的测试效果,我们先把这些文件都删掉。

我们来看看如何删除这些文件,如下图所示。

接下来我们开始上传那个jdk文件,如下图所示,发现上传成功。这里需要说明的是,由于我们的HDFS系统是在Linux系统之上搭建的一个系统,因此我们上传的文件最终还是要保存到我们的Linux本地磁盘中。

我们从本地磁盘中去找保存的两个区块,如下图所示一步一步的敲命令进入到finalized文件夹下,我们看到下图标红的两个文件,就是我们说的上传的jdk文件被分成两个区块保存的文件。
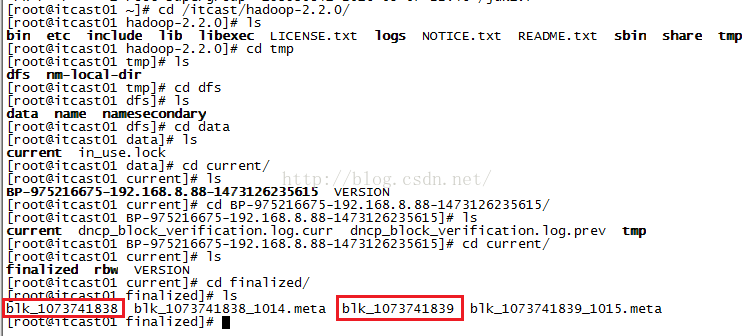
那么这两个区块的大小是多少呢?我们通过命令ls -lh查看,发现第一个区块大小是128M,第二个区块大小就是19M,而不是所谓的128M,这样做可以避免资源的浪费。

至此,本小节我们便学习完了。
转自 https://blog.csdn.net/u012453843/article/details/52463165