一、函数新特点
1.1、内联函数
c 语言中有宏函数的概念。宏函数的特点是内嵌到调用代码中去,避免了函数调用的开销。但是由于宏函数的处理发生在预处理阶段,缺失了语法检测和有可能带来的语意差错。
比如:
#include <stdio.h>
#define MAX(a,b) \
((a)>(b)?(a):(b))
int main(void)
{
int a = 48;
int b = 57;
int c = 0;
c = MAX(a,b);
printf("c = %d\r\n",c);
return 0;
}
运行结果:

如上面代码我们使用C语言的宏函数来进行大小的比较,一般情况下都是没有什么问题,但是如果传入的参数为:
c = MAX(a++,b++);
那么宏定义展开之后:
((a++)>(b++)?(a++):(b++))
可是我们的目的在比较完后进行参数自增一,因为这里b大于a,所以起码自增2了,因为比较和返回都是b++,所以使用宏定义就特别注意这些细节问题,因为在预编译阶段他是不会替你做这些事情,只是一股脑的展开。
于是基于这些,C++中使用了一种内联函数的定义,该定义和宏函数特别相似,但是不同的是宏函数在预编译阶段,内联函数是在编译阶段,所以就不会产生宏定义那样的错误。
C++提供了 inline 关键字,实现了真正的内嵌,在这之前不管是宏函数还是内联函数,其实最终的目的是为了避免反复出栈和压栈,利用存储节约时间的开销。
#include <iostream>
using namespace std;
inline void printA(void)
{
cout << "a" << endl;
}
int main(void)
{
for (int i; i < 1000; i++){
printA();
}
return 0;
}
其实使用inline也是有一些特点的。
1)内联函数声明时inline关键字必须和函数定义结合在一起,否则编译器会直
接忽略内联请求。
#include <iostream>
using namespace std;
inline void printA(void);
int main(void)
{
for (int i; i < 1000; i++){
printA();
}
return 0;
}
void printA(void)
{
cout << "a" << endl;
}
这样申明和定义分离,所以最终编译器就会忽略内联要求了。
2) C++编译器直接将函数体插入在函数调用的地方。

如圈出来的部分,内联函数直接插入调用的地方。
3)内联函数没有普通函数调用时的额外开销(压栈,跳转,返回)。
4)内联函数是一种特殊的函数,具有普通函数的特征(参数检查,返回类型等) 。
5) 内联函数由 编译器处理,直接将编译后的函数体插入调用的地方,
宏代码片段 由预处理器处理, 进行简单的文本替换,没有任何编译过程。
1)基于以上五个特点,那么对于内联函数也是有一些限制的
2)不能存在任何形式的循环语句
3)不能存在过多的条件判断语句
4)函数体不能过于庞大
5)不能对函数进行取址操作
6) 函数内联声明必须在调用语句之前
7)编译器对于内联函数的限制并不是绝对的,内联函数相对于普通函数的优
势只是省去了函数调用时压栈,跳转和返回的开销。因此, 当函数体的执行开
销远大于压栈,跳转和返回所用的开销时,那么内联将无意义。
1.2、默认参数和占位参数
一般如下代码编写,因为函数没有传递参数,导致编译器报错。
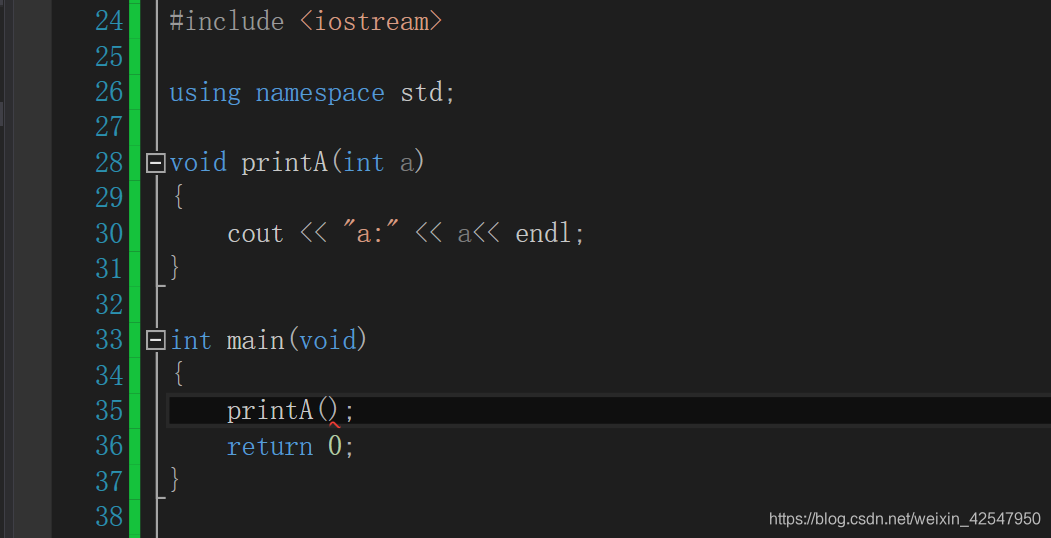
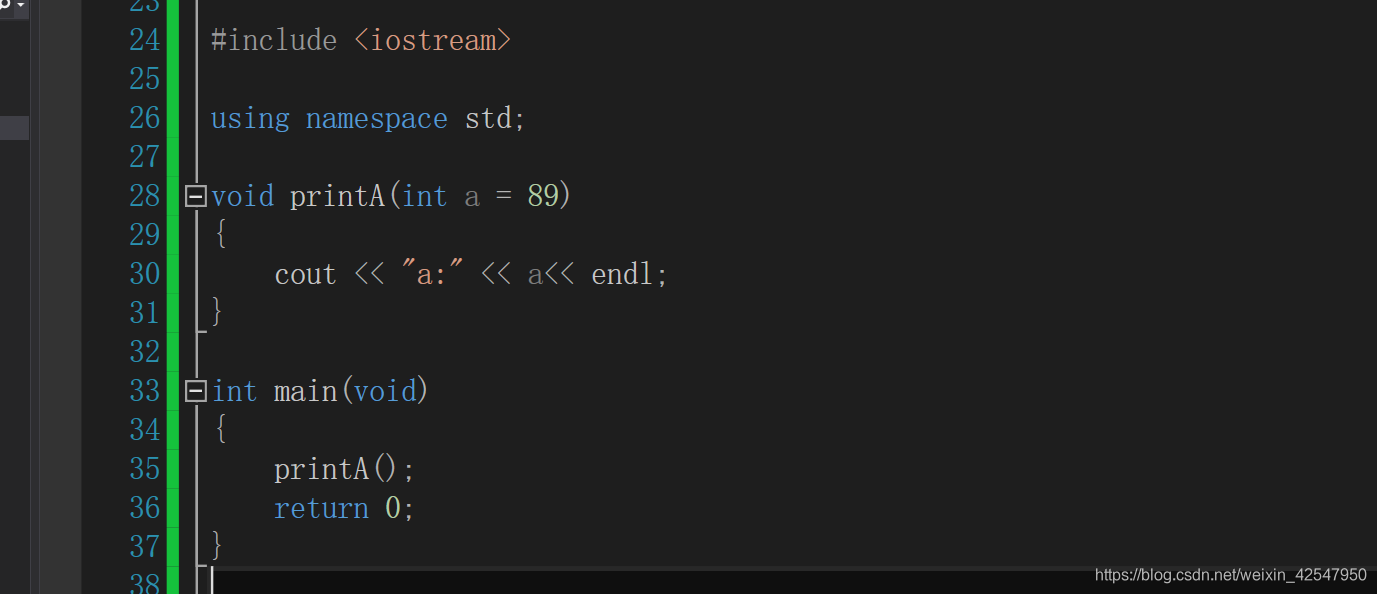
那么在C++中是否能解决呢,有的,可以使用默认参数,也就是定义时候如下:
void printA(int a = 89)
{
cout << "a:" << a<< endl;
}
其中a = 89,就是默认给a一个参数,也就是默认参数,这样就可以进行编译通过了。
其中需要注意一点,占位参数是从右到左的,什么意思呢,你不能如下面这样写:
void printA(int a = 89,int b)
{
cout << "a:" << a<< endl;
}
就是默认参数在左边,必须将默认参数放到后面:
void printA(int b, int a = 89)
{
cout << "a:" << a<< endl;
}
其实我们可以想一下,为什么默认参数放在右边,如果放在左边,那么如下:
printA(10);
那么这个10到底给那个形参?但是默认参数放置在右边,那么我就知道10是给b的,这样也能够满足编译,因为a有默认参数,所以不会报错了。
1.3、重载
函数重载(Function Overload):用同一个函数名定义不同的函数,当函
数名和不同的参数搭配时函数的含义不同。
重载规则:
1,函数名相同。
2,参数个数不同,参数的类型不同,参数顺序不同,均可构成重载。
3,返回值类型不同则不可以构成重载。
看一下下面这段代码:
#include <iostream>
using namespace std;
void printA(int a, int b)
{
cout << "fun 1" << endl;
}
void printA(int a, char *b)
{
cout << "fun 2" << endl;
}
void printA(int a, double b)
{
cout << "fun 3" << endl;
}
int main(void)
{
printA(10,20);
printA('a', 20);
printA(10, "zhangsan");
printA(10, 2.4f);
return 0;
}
运行结果:

我们一个个来看:
第一个是运行函数1,这个毫无疑问10,20都是int型,所以只有第一个匹配。
第二个也是运行函数1,但是他有一个区别就是第一个参数是char型,由此我们得知,重载也是会找隐式转换的。
第三个运行函数2毫无问题,因为字符串只有第二个重载函数才能匹配的上
第四个运行函数3,这里f代表的是float而不是double,可是这里也能运行,那么和第二个一样可以隐式转换。
所以我们总结出函数可以重载的三个要素:
1、函数名和参数的列表相同,那么可以重载
2、在不满足第一个点的情况下接着寻找隐式转换
3、如果第一和第二点都不满足,那么将不能重载
1.4、函数重载和函数指针
我们先来回顾一下函数指针定义方式有三种,如下面
第一种:
#include <iostream>
using namespace std;
typedef void(fun_way1)(int, int);
void printA(int a, int b)
{
cout << "a:" << a << endl;
cout << "b:" << b << endl;
}
int main(void)
{
fun_way1 *pfun = NULL;
pfun = printA;
pfun(10,20);
return 0;
}
第二种:
#include <iostream>
using namespace std;
typedef void(*fun_way1)(int, int);
void printA(int a, int b)
{
cout << "a:" << a << endl;
cout << "b:" << b << endl;
}
int main(void)
{
fun_way1 pfun = NULL;
pfun = printA;
pfun(10, 20);
return 0;
}
第三种:
#include <iostream>
using namespace std;
void(fun_way1)(int, int);
void printA(int a, int b)
{
cout << "a:" << a << endl;
cout << "b:" << b << endl;
}
int main(void)
{
void(*fun_way1)(int, int) = printA;
fun_way1(10, 20);
return 0;
}
我们看这三种,不管哪一种,函数指针定义的形参列表都是固定,那么在这里,函数指针就不可能使用重载,因为构成重载的参数列表这个条件已经被限定死了,所以只能指定特定的函数。
那么重载是怎么运行的呢?
C++利用 name mangling(倾轧)技术,来改名函数名,区分参数不同的同名函数。
实现原理:用 v c i f l d 表示 void char int float long double 及其引用。
比如:
void func(char a); //func_c(char a)
void func(char a,int b, double c); //func_cid(char a,int b,double c)
其实重载到最终也是运行不同的函数,只是这一步编译器帮我们实现了。
