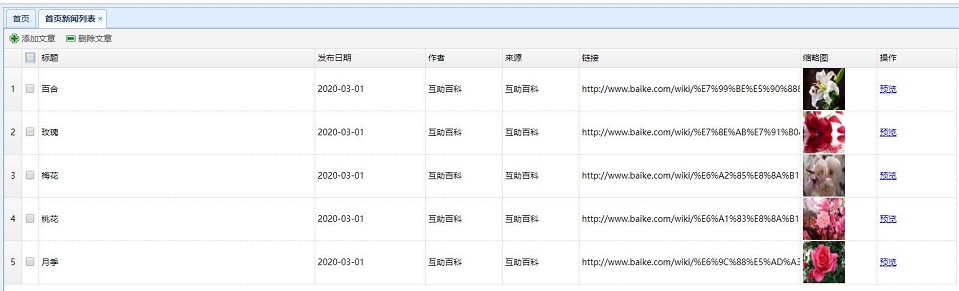
首页新闻列表点击进入新闻内容页
一种方法是请求api获得json数据返回,就像加载新闻列表时做的那样;但是这里我想尝试另一种方法,就是通过与html页面进行通信,直接加载html页面
先把新闻页面做出来,在后台的新闻管理增加预览功能
在新闻列表页datagrid中添加
<th field="operate" width="70" data-options="formatter:prev">操作</th>
增加函数
function prev(value,row,index) { return '<a href="javascript:preView('+row.id+')">预览</a>' } function preView(newsId){ $.post("prevNews",{newsId:newsId},function (obj) { }) }
新建PrevNewsServlet别名prevNews,在里面通过id查询到文章内容,返回给请求的新闻列表页
@Override protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { int newsId=Integer.parseInt(req.getParameter("newsId")); //System.out.println(newsId); JSONObject result=new JSONObject(); New news=new T_NewImpl().queryOneRecordFromHpNewsById(newsId); if(news!=null){ result.put("code",1); JSONObject jsonObject=JSONObject.fromObject(news.toString()); result.put("news",jsonObject); }else { result.put("code",0); } resp.setContentType("text/html;charset=utf-8"); resp.getWriter().println(result);
resp.getWriter().flush(); resp.getWriter().close(); }
在新闻列表页处理一下请求,打开预览窗口preView.jsp
$.post("prevNews",{newsId:newsId},function (obj) {
let result=JSON.parse(obj);
if(result.code>0){
//alert(result.news.content)
let dataForUrl=encodeURI(JSON.stringify(result.news))
window.open("preView.jsp?news="+dataForUrl)
//post
}
preView.jsp里获取数据,设置html布局
获取数据:先把字符串转json,再用urlencode解码
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title></title>
</head>
<body>
<%--<%=decodeUri(toJson(request.getParameter("news")).getString("content"))%>--%>
<div style="width: 1000px;margin:0 auto;margin-top: 30px;font:12px/20px Arial,sans-serif;border: #0581E1 1px dotted;border-radius: 5px">
<div id="title" style="font:bold 15px/25px Arial,sans-serif" align="center">
<%=decodeUri(toJson(request.getParameter("news")).getString("title"))%>
</div>
<div id="info" style="font-size: small;margin-top: 10px;padding-left:30px;padding-right:30px;border-bottom: #0581E1 1px dotted">
<span>作者:<%=decodeUri(toJson(request.getParameter("news")).getString("author"))%></span><span>创建时间:<%=decodeUri(toJson(request.getParameter("news")).getString("pubdate"))%></span>
</div>
<div id="content" style="font-size: medium;margin-top: 10px;padding-left:10px;padding-right:10px;">
<%=decodeUri(toJson(request.getParameter("news")).getString("content"))%>
</div>
</div>
</body>
</html>
<%!
JSONObject toJson(String str){
return JSONObject.fromObject(str);
}
%>
<%!
//java.lang.IllegalArgumentException: URLDecoder: Illegal hex characters in escape (%) pattern - Error at index 0 in:
String decodeUri(String str) throws UnsupportedEncodingException {
// str = str.replaceAll("%(?![0-9a-fA-F]{2})", "%25");
String string= java.net.URLDecoder.decode(str,"utf-8");
return string;
}
%>
会遇到几个解码错误的问题,最后文字传递的时候,直接转成url编码了
public String toString2() throws UnsupportedEncodingException { String newTitle=URLEncoder.encode(title,"utf-8"); String newContent=URLEncoder.encode(content,"utf-8"); String newOrigin=URLEncoder.encode(origin,"utf-8"); String newHref=URLEncoder.encode(href,"utf-8"); String newThumb=URLEncoder.encode(thumb,"utf-8"); String newAuthor=URLEncoder.encode(author,"utf-8"); return "{" + "id=" + id + ", title='" + newTitle + '\'' + ", author='" + newAuthor + '\'' + ", pubdate=" + pubdate.getTime() + ", origin='" + newOrigin + '\'' + ", href='" + newHref + '\'' + ", content='" + newContent + '\'' + ", thumb='" + newThumb + '\'' + '}'; }
修正一个bug。第五篇中,中文乱码或者上传图片不完整的问题。
之前发表文字页面需要post内容,还要上传一张图片,把提交表单的enctype设置成了multipart/form-data。从后台读取二进制流数据,需要把二进制流数据转换成utf-8,否则中文就乱码。那图片也转换成utf-8编码了。所以遇到的问题是要么读取图片出错,要么中文乱码。。
我想先弄清一下,图片转utf-8是怎么转的,打开一张图片,使用二进制编辑
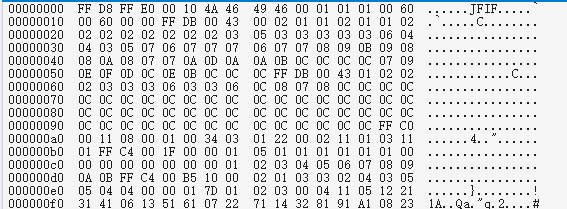
这张图片转码成utf-8之后输出成这样

图片二进制也组成字节,关于字节与utf-8的转换规则,可以参考ascii 和 byte以及UTF-8的转码规则
计算机指定了UTF8编码接收二进制并进行转移,当发现字节以0开头,表示这是一个标准ascii字符,直接转义 ,当发现1110开头,就说明接下来的三个字节表示一个汉字,则取3个字节去掉模板后转义,UTF8编码模板如下
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
那看那张图片的二进制FF D8 FF E0 00 10 4A 46 49 46 00 01 01 01 00 60
前面几个字符是转码不了的,直到
0x10->
0x4A->J
...
用window记事本做个测试:
微软使用BOM标记字符编码,比方,这是一个utf-8编码的文本文档,二进制表示是

EF BB BF就是它的BOM,
试着在里面添加一些图片的字节

显示也是一样的
还可以用java测试一下
byte[] by={104, 97, 112, 112, 121,(byte)0xFF,(byte)0xD8,(byte)0xE0,(byte)0x00,(byte)0x10,(byte)0x4A,(byte)0x46,(byte)0x49,(byte)0x46,(byte)0x00,(byte)0x01,(byte)0x1,(byte)0x01,(byte)0x00,99, 111, 109, 102, 111, 114, 116, 97, 98, 108, 101}; String p=new String(by,"utf-8"); System.out.println(p); System.out.println(Arrays.toString(p.getBytes()));
输出

多出来一些数据,说明如果把不可识别的字符编码进去再解码,数据会被破坏掉。
接着按需要,我现在要试着从字节数组
byte[] by={-26, -120, -111,104, 97, 112, 112, 121,(byte)0xFF,(byte)0xD8,(byte)0xE0,(byte)0x00,(byte)0x10,(byte)0x4A,(byte)0x46,(byte)0x49,(byte)0x46,(byte)0x00,(byte)0x01,(byte)0x1,(byte)0x01,(byte)0x00,99, 111, 109, 102, 111, 114, 116, 97, 98, 108, 101};
解码出"我happy"+{图片字节}+"comfortable",试着这样获取
byte[] by={-26, -120, -111,104, 97, 112, 112, 121,(byte)0xFF,(byte)0xD8,(byte)0xE0,(byte)0x00,(byte)0x10,(byte)0x4A,(byte)0x46,(byte)0x49,(byte)0x46,(byte)0x00,(byte)0x01,(byte)0x1,(byte)0x01,(byte)0x00,99, 111, 109, 102, 111, 114, 116, 97, 98, 108, 101}; String p=new String(by,"utf-8"); System.out.println(p); int start=p.indexOf("happy")+"happy".length(); int end=p.indexOf("comfortable"); start=p.substring(0,start).getBytes().length; //end=p.substring(0,end).getBytes().length; StringBuffer sb=new StringBuffer(p); String pr=sb.reverse().toString(); System.out.println(pr); System.out.println(Arrays.toString(pr.getBytes())); end=pr.indexOf("elbatrofmoc")+"elbatrofmoc".length(); end=pr.substring(0,end).getBytes().length; int picLen=by.length-(start+end); byte[] pic=new byte[by.length-(end+start)]; System.arraycopy(by,start,pic,0,by.length-(end+start)); ArrayList byteArray=new ArrayList<>(); for(int i=0;i<pic.length;i++){ byteArray.add(Integer.toHexString(pic[i]&0xff).toUpperCase()); } System.out.println(byteArray);
也可以把原字节数组保留两份,一份使用utf-8编码,另一份不使用utf-8。只有文字部分使用uft-8编码的字符串(最后我用的是这种方法)
效果

感觉又水了一天是怎么回事。。。