一,FPN特征金字塔网络
FPN的网络结构如下:

图片输入后会进行卷积操作,其实蓝色线条表示语义强度,线条越粗,语义越强。

右方的连接结构如虚线框所示:上面的特征图经过2倍上采样后,和左方对应的特征图经过1x1的卷积降维后,加在一起就成了右方的下一个特征图了。
FPN的优点:

如上图所示,我们可以看到我们的图像中存在不同尺寸的目标,而不同的目标具有不同的特征,利用浅层的特征就可以将简单的目标的区分开来;利用深层的特征可以将复杂的目标区分开来;这样我们就需要这样的一个特征金字塔来完成这件事。图中我们在第1层(请看绿色标注)输出较大目标的实例分割结果,在第2层输出次大目标的实例检测结果,在第3层输出较小目标的实例分割结果。检测也是一样,我们会在第1层输出简单的目标,第2层输出较复杂的目标,第3层输出复杂的目标。
二,FPN用于语义分割
FPN虽然是一个特征提取网络,但之前很多都是用于目标检测的。在何凯明的全景分割论文中,就用了FPN进行语义分割,大致结构如下:
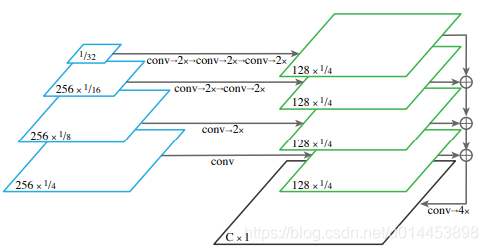
蓝色的框是卷积后的特征图。绿色框部分就相当于predit的部分。
可以看到,当用FPN做语义分割时,每个特征图(蓝色框)都会进行(卷积+两倍上采样)操作,提升到原图的1/4分辨率,再加在一起,最后再通过4倍上采样,提升到与原图相等的分辨率。
(上图的256和128表示特征图的通道数,分数1/4,1/8等等表示当前特征图缩小为原图的几分之几,C代表总类别数,x1表示与原图大小是相等的)
最后返回一个与原图大小相等的,通道数为类别数的特征图。
三,代码部分:
使用数据集:cityscapes
cityspaces数据集有很多个,我的是用下面的:(gtFine是label,下面的是原图)
![]()
类别数是20。
注意使用的label是下图红色框的那个:

为什么会那么暗呢?label为什么不是第一张而是红色框的呢?
1.上面四张其实都是同一张原图的label,只是看你 用哪一种而已。
2.红色框那种暗的原因是图片的值全是 -1~33的某些值。
这四张的输入原图如下:

模型代码:(这篇 博文只给贴出一部分代码,完整代码在下面的github链接中。)
'''FPN in PyTorch.
See the paper "Feature Pyramid Networks for Object Detection" for more details.
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models.resnet import ResNet
from torch.autograd import Variable
from model.backbone import build_backbone
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class FPN(nn.Module):
def __init__(self, num_blocks, num_classes, back_bone='resnet', pretrained=True):
super(FPN, self).__init__()
self.in_planes = 64
self.num_classes = num_classes
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
BatchNorm = nn.BatchNorm2d
self.back_bone = build_backbone(back_bone)
# Bottom-up layers
self.layer1 = self._make_layer(Bottleneck, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(Bottleneck, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(Bottleneck, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(Bottleneck, 512, num_blocks[3], stride=2)
# Top layer
self.toplayer = nn.Conv2d(2048, 256, kernel_size=1, stride=1, padding=0) # Reduce channels
# Smooth layers
self.smooth1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
# Lateral layers
self.latlayer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
self.latlayer2 = nn.Conv2d( 512, 256, kernel_size=1, stride=1, padding=0)
self.latlayer3 = nn.Conv2d( 256, 256, kernel_size=1, stride=1, padding=0)
# Semantic branch
self.semantic_branch = nn.Conv2d(256, 128, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(128, self.num_classes, kernel_size=1, stride=1, padding=0)
# num_groups, num_channels
self.gn1 = nn.GroupNorm(128, 128)
self.gn2 = nn.GroupNorm(256, 256)
def _upsample(self, x, h, w):
return F.interpolate(x, size=(h, w), mode='bilinear', align_corners=True)
def _make_layer(self, Bottleneck, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(Bottleneck(self.in_planes, planes, stride))
self.in_planes = planes * Bottleneck.expansion
return nn.Sequential(*layers)
def _upsample_add(self, x, y):
'''Upsample and add two feature maps.
Args:
x: (Variable) top feature map to be upsampled.
y: (Variable) lateral feature map.
Returns:
(Variable) added feature map.
Note in PyTorch, when input size is odd, the upsampled feature map
with `F.upsample(..., scale_factor=2, mode='nearest')`
maybe not equal to the lateral feature map size.
e.g.
original input size: [N,_,15,15] ->
conv2d feature map size: [N,_,8,8] ->
upsampled feature map size: [N,_,16,16]
So we choose bilinear upsample which supports arbitrary output sizes.
'''
_,_,H,W = y.size()
return F.interpolate(x, size=(H,W), mode='bilinear', align_corners=True) + y
def forward(self, x):
# Bottom-up using backbone
low_level_features = self.back_bone(x)
c1 = low_level_features[0]
c2 = low_level_features[1]
c3 = low_level_features[2]
c4 = low_level_features[3]
c5 = low_level_features[4]
# Bottom-up
#c1 = F.relu(self.bn1(self.conv1(x)))
#c1 = F.max_pool2d(c1, kernel_size=3, stride=2, padding=1)
#c2 = self.layer1(c1)
#c3 = self.layer2(c2)
#c4 = self.layer3(c3)
#c5 = self.layer4(c4)
# Top-down
p5 = self.toplayer(c5)
p4 = self._upsample_add(p5, self.latlayer1(c4))
p3 = self._upsample_add(p4, self.latlayer2(c3))
p2 = self._upsample_add(p3, self.latlayer3(c2))
# Smooth
p4 = self.smooth1(p4)
p3 = self.smooth2(p3)
p2 = self.smooth3(p2)
# Semantic
_, _, h, w = p2.size()
# 256->256
s5 = self._upsample(F.relu(self.gn2(self.conv2(p5))), h, w)
# 256->256
s5 = self._upsample(F.relu(self.gn2(self.conv2(s5))), h, w)
# 256->128
s5 = self._upsample(F.relu(self.gn1(self.semantic_branch(s5))), h, w)
# 256->256
s4 = self._upsample(F.relu(self.gn2(self.conv2(p4))), h, w)
# 256->128
s4 = self._upsample(F.relu(self.gn1(self.semantic_branch(s4))), h, w)
# 256->128
s3 = self._upsample(F.relu(self.gn1(self.semantic_branch(p3))), h, w)
s2 = F.relu(self.gn1(self.semantic_branch(p2)))
return self._upsample(self.conv3(s2 + s3 + s4 + s5), 4 * h, 4 * w)
def _init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.GroupNorm):
m.weight.data.fill_(1)
m.bias.data.zero_()
if __name__ == "__main__":
model = FPN([2,4,23,3], 32, back_bone="resnet")
input = torch.rand(1,3,512,1024)
output = model(input)
print(output.size())预测代码:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from torchvision.utils import save_image
import os
import sys
import numpy as np
import argparse
import pprint
import pdb
import time
import logging
import glob
import pandas as pd
import scipy.misc
from collections import namedtuple
import torch
from data.utils import decode_segmap, decode_seg_map_sequence
from mypath import Path
from utils.metrics import Evaluator
from data import make_data_loader
from model.FPN import FPN
from model.resnet import resnet
means = np.array([103.939, 116.779, 123.68]) / 255.
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser(description='Train a FPN Semantic Segmentation network')
parser.add_argument('--dataset', dest='dataset',
help='training dataset',
default='CamVid', type=str)
parser.add_argument('--net', dest='net',
help='resnet101, res152, etc',
default='resnet101', type=str)
parser.add_argument('--start_epoch', dest='start_epoch',
help='starting epoch',
default=1, type=int)
parser.add_argument('--epochs', dest='epochs',
help='number of iterations to train',
default=2000, type=int)
parser.add_argument('--save_dir', dest='save_dir',
help='directory to save models',
default="./",
type=str)
parser.add_argument('--num_workers', dest='num_workers',
help='number of worker to load data',
default=0, type=int)
# cuda
parser.add_argument('--cuda', dest='cuda',
help='whether use multiple GPUs',
default=True,
action='store_true')
# batch size
parser.add_argument('--bs', dest='batch_size',
help='batch_size',
default=5, type=int)
# config optimization
parser.add_argument('--o', dest='optimizer',
help='training optimizer',
default='sgd', type=str)
parser.add_argument('--lr', dest='lr',
help='starting learning rate',
default=0.001, type=float)
parser.add_argument('--weight_decay', dest='weight_decay',
help='weight_decay',
default=1e-5, type=float)
parser.add_argument('--lr_decay_step', dest='lr_decay_step',
help='step to do learning rate decay, uint is epoch',
default=500, type=int)
parser.add_argument('--lr_decay_gamma', dest='lr_decay_gamma',
help='learning rate decay ratio',
default=0.1, type=float)
# set training session
parser.add_argument('--s', dest='session',
help='training session',
default=1, type=int)
# resume trained model
parser.add_argument('--r', dest='resume',
help='resume checkpoint or not',
default=False, type=bool)
parser.add_argument('--checksession', dest='checksession',
help='checksession to load model',
default=1, type=int)
parser.add_argument('--checkepoch', dest='checkepoch',
help='checkepoch to load model',
default=1, type=int)
parser.add_argument('--checkpoint', dest='checkpoint',
help='checkpoint to load model',
default=0, type=int)
# log and display
parser.add_argument('--use_tfboard', dest='use_tfboard',
help='whether use tensorflow tensorboard',
default=True, type=bool)
# configure validation
parser.add_argument('--no_val', dest='no_val',
help='not do validation',
default=False, type=bool)
parser.add_argument('--eval_interval', dest='eval_interval',
help='iterval to do evaluate',
default=2, type=int)
parser.add_argument('--checkname', dest='checkname',
help='checkname',
default=None, type=str)
parser.add_argument('--base-size', type=int, default=512,
help='base image size')
parser.add_argument('--crop-size', type=int, default=512,
help='crop image size')
# test confit
parser.add_argument('--plot', dest='plot',
help='wether plot test result image',
default=False, type=bool)
parser.add_argument('--exp_dir', dest='experiment_dir',
help='dir of experiment',
type=str)
args = parser.parse_args()
return args
def main():
args = parse_args()
if args.dataset == 'Cityscapes':
num_class = 19
if args.net == 'resnet101':
blocks = [2, 4, 23, 3]
model = FPN(blocks, num_class, back_bone=args.net)
if args.checkname is None:
args.checkname = 'fpn-' + str(args.net)
#evaluator = Evaluator(num_class)
# Trained model path and name
experiment_dir = args.experiment_dir
#load_name = os.path.join(experiment_dir, 'checkpoint.pth.tar')
load_name = os.path.join(r'/home/home_data/zjw/SemanticSegmentationUsingFPN_PanopticFeaturePyramidNetworks-master/run/Cityscapes/fpn-resnet101/model_best.pth.tar')
# Load trained model
if not os.path.isfile(load_name):
raise RuntimeError("=> no checkpoint found at '{}'".format(load_name))
print('====>loading trained model from ' + load_name)
checkpoint = torch.load(load_name)
checkepoch = checkpoint['epoch']
if args.cuda:
model.load_state_dict(checkpoint['state_dict'])
else:
model.load_state_dict(checkpoint['state_dict'])
# test
img_path = r'./s1.jpeg'
image = scipy.misc.imread(img_path, mode='RGB')
image = image[:,:,::-1]
image = np.transpose(image,(2,0,1))
#image[0] -= means[0]
#image[1] -= means[1]
#image[2] -= means[2]
image = torch.from_numpy(image.copy()).float()
image = image.unsqueeze(0)
if args.cuda:
image,model = image.cuda(),model.cuda()
with torch.no_grad():
output = model(image)
pred = output.data.cpu().numpy()
pred = np.argmax(pred, axis=1)
# show result
pred_rgb = decode_seg_map_sequence(pred, args.dataset, args.plot)
#results.append(pred_rgb)
save_image(pred_rgb,r'./testjpg.png')
if __name__ == "__main__":
main()
预测效果:
输入:

输出:

可以看到,用FPN做语义分割可以做到识别一些比较细节性的东西,例如被树挡住的电线杆部分,和被树挡住的小车。
(完整代码:https://github.com/Andy-zhujunwen/FPN-Semantic-segmentation)
