Bert代码初识
简单读懂代码
modeling.py–定义一个bert模型的主体结构
BertConfig类
- BertModel类中所需要的超参数
- 定义从python dict中生成BertConfig的方法 from_dict(cls, json_object)
- 定义从json中生成BertConfig的方法 from_json_file(cls, json_file)
- 定义将BertConfig转换为python dict的方法 to_dict(self)
- 定义将BertConfig转换为json字符串的方法 to_json_string(self)
BertModel类
- 定义了激活函数,归一化函数以及过拟合函数等
- 定义了embedding_lookup函数 将输入input_ids[batch_size, seq_length]转换成[batch_size, seq_length, embedding_size]
- 定义了embedding_postprocessor函数 将token_type_embeddings和position_embedding加入到input_tensor中,对最后的结果进行归一化和dropout

- 定义了create_attention_mask_from_input_mask函数 构造attention mask ,将shape为[batch_size, to_seq_length]的mask转换为[batch_size, from_seq_length, to_seq_length] 的mask用于attention当中。例如输入句子的mask为[[1, 1, 0], [1, 1, 1]],它的维度是batch(2)*seq_len(3),经过该函数后输出的维度为[2,3,3],这样变化是为了方便做attention计算(该句子的自注意的计算操作)
- 定义了attention_layer,将输入的from_tensor当作query,query和key做相似度计算,然后归一化得到注意力权重,将对应的权重和value进行加权求和,这样使得结果向量中每个字向量中都包含当前句子中所有字向量的信息。这里面应用了多头注意,简单来说就是将[batch_size, seq_lenth, embedding_size] 划分成num_attention_heads 个[batch_size,seq_lenth, size_per_head]),分别做self-attention。
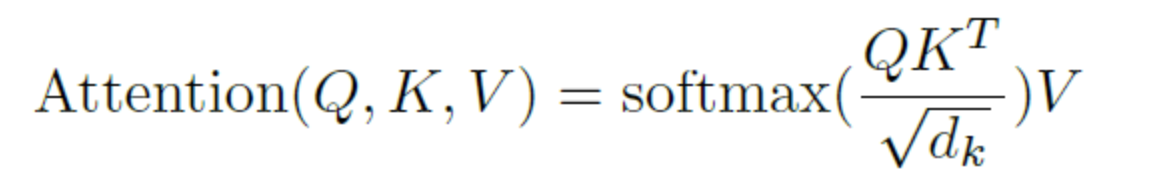
- 定义了transformer_model 是将输入的向量,循环调用transformer的前向过程,次数为隐藏层个数。每次前向过程都进行self_attention_layer、add_and_norm、feed_forward和add_and_norm操作,最后得到的是final_output[batch_size, seq_length, hidden_size]
过程
1.向输入的input=[batch_size, seq_length, embedding_size]的向量中增加token_type embedding和position embedding,然后进行layer_norm和dropout
2.将上一步的输出embedding输入到transform中,进行self_attention_layer、add_and_norm、feed_forward和add_and_norm四个步骤中
3.transformer_model是由多个Transformer堆叠在一起的,所以得到的all_encoder_layers是一个list,长度为num_hidden_layers(默认12),每一层对应一个值。 每一个值都是一个shape为[batch_size, seq_length, hidden_size]的tensor
4.sequence_output是最后一层的输出,shape是[batch_size, seq_length, hidden_size]
5.pool层的输出first_token_tensor是第一个Token([CLS])最后一层的输出,shape是[batch_size, hidden_size]
run_classifier.py–运行启动函数
- 定义了InputExample类,包括样本的id(guid)、句子a(text_a)、句子b(text_b)和标签(label),若是测试集,label统一设为0
- 定义了InputFeatures类(输入的特征),其中包括input_ids(token对应的索引),input_mask,segment_ids(在BertModel中被看作token_type_id),label_id(标签对应的id)以及is_real_example。
- 定义了DataProcessor类,这个类包含了四个公开数据集对应的子类,一个数据集对应着一个DataProcessor子类,每个子类都继承了这四个方法,从文件目录中获得train,dev和test样本数据以及一个获取label集合的函数。
如果需要在自己的数据集上面进行微调,则需要重新写一个DataProcessor子类,按照自己的数据样式从数据集中获取数据样本。 - 定义了convert_single_example函数。可以对一个InputExample转换为InputFeatures,若句子长则截断了长度超过最大值的句子,相反,则补全。
- 定义了create_model函数,获取BertModel的pooled_output[batch size,hidden size](也就是[cls],中包含整个句子的信息),将其做全连接后得到[batch size,num_labels],然后归一化得到每个句子对应不同标签的概率,然后计算loss损失。
- 定义了main函数,从FLAGS中构建model_fn和estimator,并根据参数中的do_train,do_eval和do_predict的取值决定要进行estimator的哪些操作。
tokenization.py–对原始句子的解析模块
- BasicTokenizer类
进行unicode转换、标点符号分割、小写转换、中文字符分割、去除重音符号等操作,最后返回的是关于词的数组 - WordpieceTokenizer类
WordpieceTokenizer的目的是将合成词分解成类似词根一样的词片。
例如[“unaffable”]切分为[“un”, “##aff”, “##able”]}这么做的目的是防止因为词的过于生僻没有被收录进词典最后只能以[UNK]代替的局面,因为英语当中这样的合成词非常多,词典不可能全部收录。 - FullTokenizer类
对一个文本段进行以上两种解析,最后返回词(字)的数组,同时还提供token到id的索引以及id到token的索引。
run_pretraining.py–预训练的执行
在执行预训练时针对这两个方法masked language model和next sentence训练参数,计算loss,然后进行梯度下降优化。对BERT模型本身的参数进行训练。若使用现有的预训练BERT模型在文本分类/问题回答等任务上进行fine_tune,则无需使用run_pretraining.py。
create_pretraining_data.py–将原始语料转换成适合模型预训练的输入数据
定义了如何将普通文本转换成可用于预训练BERT模型的tfrecord文件的方法。
分为了三个步骤1)构造tokenizer 2)构造instances 3)保存instances
optimization.py–bert的optimizer
加入weight decay功能和learning_rate warmup功能的AdamOptimizer。
*特别的参数
warmup_proportion,是一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习来进行训练。这么做的原因是由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
参考
技术分享:BERT系列(一)
Bert系列(四)——源码解读之Fine-tune
一本读懂BERT(实践篇)
Bert系列(三)——源码解读之Pre-train
Bert系列(一)——demo运行
