
猜猜他是谁
29年前,一位大学生毕业了,由于能力出众,本科学历的他得到了大学教师的工作,他还在西湖边开了自己的小公司,日子过得稳定顺利。3年后,一次出差他到了美国。看到人们敲的键盘、握的鼠标、像电视机一样的屏幕画面,他惊呆了,他第一次知道有种“网”是看不见的,叫“互联网”。
再3年后,他辞掉了大学老师的工作,借了可以在当时买一套房的12000块钱,创办了一个网站,开始做谁也没听过的互联网。在之后的无数年,他跑遍了国内国外,寻找投资人,但是因为他长的实在太不友好(ノДT),所以也有无数次,他被当成骗子轰了出去……直到他遇到了软银。
再之后,跑在时代前沿的他终于等到了他的时代,他的帝国开始生长繁衍、强大生息,与全球几十亿人的生活紧密相连,他的名字成为这个时代的符号之一,不过他依然在不断学习、创新。他创建的阿里巴巴也成为了互联网企业的标杆!

努力固然重要,但是在一个优质赛道上发力,常常会让我们事半功倍。芒格有句名言:钓鱼的第一条规则是,在有鱼的地方钓鱼。钓鱼的第二条规则是,记住第一条规则,说的就是这个道理。
请选准赛道再努力奔跑
俗话说得好“男怕入错行,女怕嫁错郎“。比不努力奔跑更可悲的是在下行的电梯里拼命的向上奔跑。那么对于职场人士来说哪个行业是优势赛道呢?我们看图说话。
自2015年开始,中国人工智能市场规模和员工薪酬逐年攀升。随着人工智能技术的逐渐成熟,科技、制造业等业界巨头不断深入布局。数据显示,2018年中国人工智能市场规模约为339亿元,增长率达到56.2%。据预测,2020年中国在人工智能的市场规模将突破700亿元。

学历不再是门槛,拥有硬核实力是关键!
一直以来AI都是唯学历论,大厂招聘只要研究生和博士生。但是人才太过短缺,也不得不让企业放下了“架子”和“成见”。2020年人才争夺大战正式拉开帷幕,百度、阿里、腾讯、华为、小米纷纷开出百万高薪offer。AI技术门槛也在逐步降低,例如:阿里AI岗位主要以本科、硕士为主,博士占比仅为4%了!在这一场战役里,阿里百万年薪引入了陈颖、谭平两位拥有海外背景的大牛科学家,华为更豪,为8位应届AI博士开出了200W年薪!

我们来看下去年互联网的第一和第二梯队开出的薪酬把,年薪20多万成为了白菜价,甚至某大厂“硬核”抢人,放话:只要AI人才,高中毕业都行!,

Python时代de宠儿
简单易学,小学生也可以上手学习的计算机语言。举个例子一个程序用C语言需要1000行的代码,用JAVA需要写100行,但是如果用Python你只需要20行,而且语法还很简洁。Python也是很多非IT人士如财务人员必须掌握的装逼利器,例如批量合同文件,就可以采用Python进行快速的读取和处理。
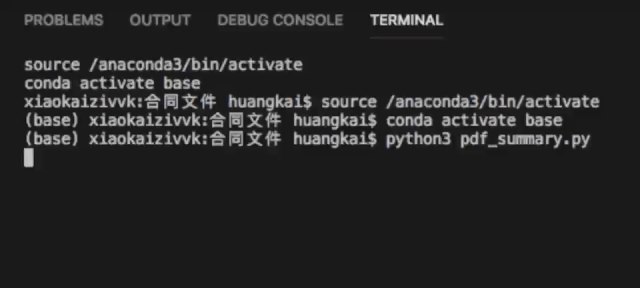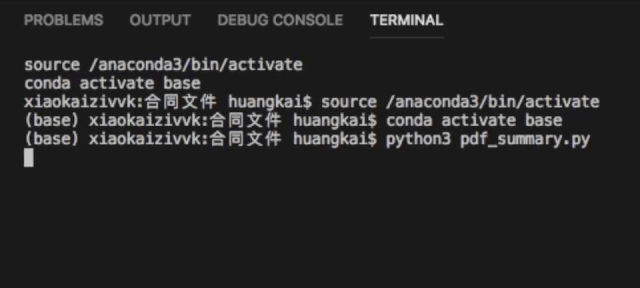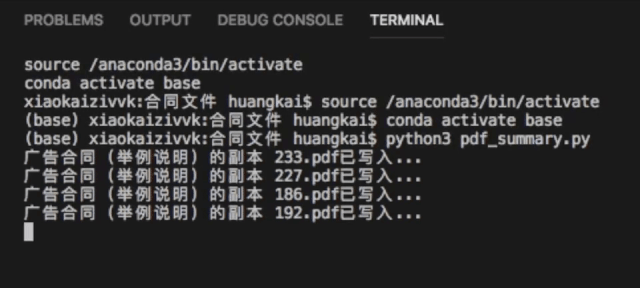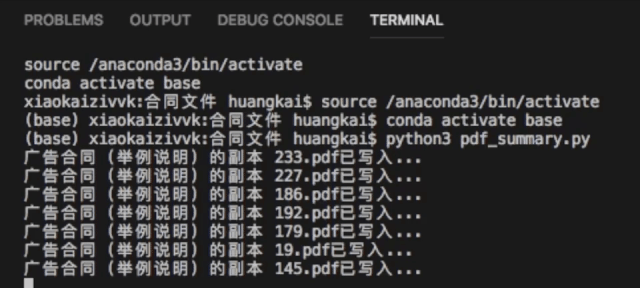
Python获取疫情数据
很多大型门户网站和手机应用都开设了专门的疫情实时追踪数据网站和功能,数据来源于国家及各地卫生健康委员会每日发布的信息,今天我们就以腾讯为例来获取疫情实时数据把,废话不说,上代码:
import requests, json
import openpyxl
province = [] # 省区
city = [] # 城市
dead = [] # 死亡人数
confirm = [] # 确诊人数
heal = [] # 治愈人数
cwy_confirm = [] # 今日新增确诊
def getHTMLText(url): # 定义了一个函数,用于获取html的文本。
try:
r = requests.get(url, timeout=30)
r.raise_for_status() # 如果状态不是200,引发HTTPError异常。
r.encoding = r.apparent_encoding # 从内容中分析,修正代码的编码方式。
return r.text
except:
return "产生异常"
# 获取数据的地址
url = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5"
data = json.loads(getHTMLText(url))
data_total = json.loads(data["data"])
Total = data_total["chinaTotal"]
ChinaAdd = data_total["chinaAdd"]
print("【全国疫情累计数据】确诊{}人,疑似{}人,死亡{}人,治愈{}人。".format(Total['confirm'], Total['suspect'], Total['dead'], Total['heal']))
print("【全国疫情新增数据】确诊新增{}人,疑似新增{}人,死亡新增{}人,治愈新增{}人。".format(ChinaAdd['confirm'], ChinaAdd['suspect'], ChinaAdd['dead'],
ChinaAdd['heal']))
print("【数据更新时间:】", data_total["lastUpdateTime"])
data_total_children = data_total["areaTree"][0]["children"]
for p in range(0, len(data_total_children)):
for c in range(0, len(data_total_children[p]["children"])):
details_city = data_total_children[p]["children"][c]
province.append(data_total_children[p]["name"]) # 所有的省份生成一个list。
city.append(details_city["name"])
confirm.append(details_city['total']['confirm'])
dead.append(details_city['total']['dead'])
heal.append(details_city['total']['heal'])
cwy_confirm.append(details_city['today']['confirm'])
wb = openpyxl.Workbook()
ws = wb.active
print(wb.get_sheet_names)
ws.cell(1, 2, value="省份")
ws.cell(1, 3, value="城市")
ws.cell(1, 4, value="确诊人数")
ws.cell(1, 5, value="治愈人数")
ws.cell(1, 6, value="死亡人数")
ws.cell(1, 7, value="确诊新增")
for n in range(0, len(city)):
ws.cell(n + 2, 2, value=province[n])
ws.cell(n + 2, 3, value=city[n])
ws.cell(n + 2, 4, value=confirm[n])
ws.cell(n + 2, 5, value=heal[n])
ws.cell(n + 2, 6, value=dead[n])
ws.cell(n + 2, 7, value=cwy_confirm[n])
wb.save('yiqing.xlsx')
只需要把代码复制,就可以获取当前全国各省市区的疫情信息,数据默认保存在代码同目录,并且保存的格式为常见的xlsx格式,当然我们也可以选择csv格式,代码获取结果如下。

Python刻画疫情词云图
数据虽然已下载,但是直接通过xls文件观看难免乏味且可视化不强,对于我们老百姓来说就想知道目前还有哪些城市是重灾区,在Py中可视化的库太多啦。matplotlib、seaborn、pyecharts… 今天给大家介绍一款高逼格称为wordcloud词云图,是对文本中出现频率较高的“关键词”予以视觉化的展现,词云图过滤掉大量的低频低质的文本信息。
# 第三方库大家可以通过pip一键安装即可
C:\Users\57423>pip install wordcloud
词云图在显示时需要一张背景图,大家可以互联网随便找一张图片(背景最好是纯白或者纯黑),轮廓要清楚,这样生成词云图才能知道内容填充在哪里,在本次案例中我们选择了钟南山院士的一张图作为背景。

功能实现非常简单,只需要加载前面获取的数据,然后通过wordcloud设置背景图片的尺寸和中文字体,最后设置生成词云图的保存路径即可。废话不说,上代码。
from imageio import imread # 加载图片
from wordcloud import WordCloud
import pandas as pd
# 加载疫情数据源
data = pd.read_excel("yiqing.xlsx")
# 确定要可视化的列信息
data = data [['城市','确诊人数']]
show = {}
for a, x in data.values:
show[a] = x
# bg.png的图片尺寸:width=600,height=600,
# font_path: 则指定可显示中文字体,否则乱码
# random_state: 如不指定每次生成数据排列随机
# mask: 指定作为遮罩的图片
wc = WordCloud(font_path=r"C:\Windows\Fonts\SimHei.ttf",
width=600,height=600,
background_color="white",
random_state=1,
mask=imread("bg.png"))
wc.generate_from_frequencies(frequencies=show)
# 指定保存词云图路径
wc.to_file("yiqing.png")

生成的词云图效果如下。选择的背景图不同,生成的词云图形状则不同,大家赶紧生成属于自己的词云图把!

疫情的蔓延痛噬着每一位国人的心,现在虽然情况有所缓解。但是战疫远未结束,切莫放松!宅在家撸技术就是对家人,对公司,对社会最大的贡献。让我们一起加油!


