此文章转载于Java的架构师技术栈微信公众号
OK,开始今天的文章。
一、LinkedList认识
1、由链表认识LinkedList
我们想要认识链表有一个例子可以形象的去表示,我们都看过警察捉贼的故事,比如说警察现在要抓一个小偷,得知小偷在A处,结果警察一去发现没有,但是A处的相关人员说小偷可能在B处,结果警察又去了B处,发现又没有,被告知可能在C处,警察又去了C处,没有之后得到情报又去了D、E、F等等。最终抓获了小偷,我们把整个抓捕过程其实就可以看成一条线索链,或者说叫做链表。我们可以看到每一处地点,我们就可以看做链表的一个节点,每一个节点要包含两个信息:一个是本地的信息,一个是下一个地点的信息。
下面使用一张图来直观的表示一下:


下面我们就可以对上面的这个链表进行一个分类:
-
单链表:就是上面我们提到的,只有下一处的地址。
-
双链表:表示不仅存储下一处的地址,还存储上一处的。
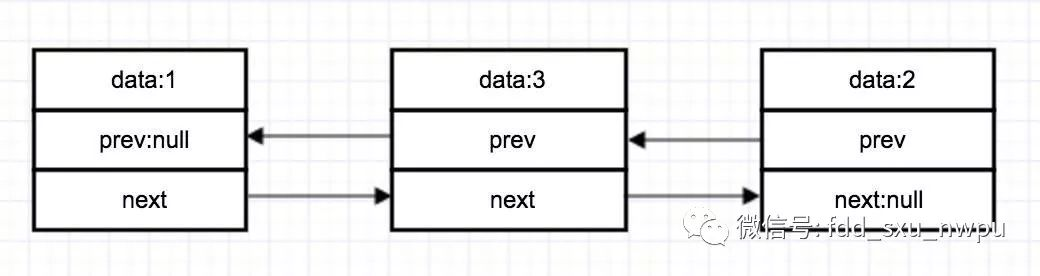

-
循环链表:就是说整个地址构成一个循环链。
-
有序链表:以某个标准,给链表的元素排序,比如比较内容大小、比较哈希值等
在上面我们已经看到了链表的实现方式还有分类,当然链表还有一些基本的特性,需要我们去了解:
-
在数组中,是通过索引访问元素的。但是链表不能,只能通过链一个一个的找。这个说明了链表的优势不在快速找到元素。
-
链表的优势在于定点删除/插入元素,因为链表影响的最多就是给定元素的左右的两个链
-
这里就有个trick, 由于改变右边链的时候,如果不先存储右边的结点,那么右边的结点的元素就找不到了,所以改变结点的指针的时候,会先暂存下一个结点。
-
另外单链表找不到它的父亲结点(上一个结点),所以会经常用prev来暂存上一个结点。
2、认识LinkedList
我们的LinkedList就是以双向链表实现的。既然它是以链表来实现的,所以也会有链表的基本特性。又因为其是使用双向链表来实现的,所以重点还是在于双向链表的特性
-
链表无容量限制,但双向链表本身使用了更多空间,也需要额外的链表指针操作。
-
除了实现List接口外,LinkedList还为在列表的开头及结尾get、remove和insert元素提供了统一的命名方法。这些操作可以将链接列表当作栈,队列和双端队列来使用。
3、从继承关系看LinkedList
为此我们需要先知道LinkedList在整个java集合框架体系里面处于一个什么样的位置。一张图来说明:
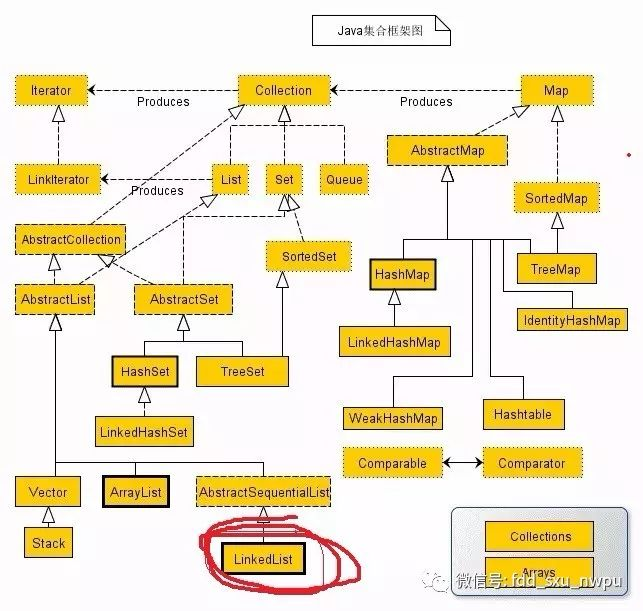

从上面我们发现LinkedList的最根部就是实现了Collection接口。下面我们去掉其他影响集合,从LinkedList为出发点来看继承关系:
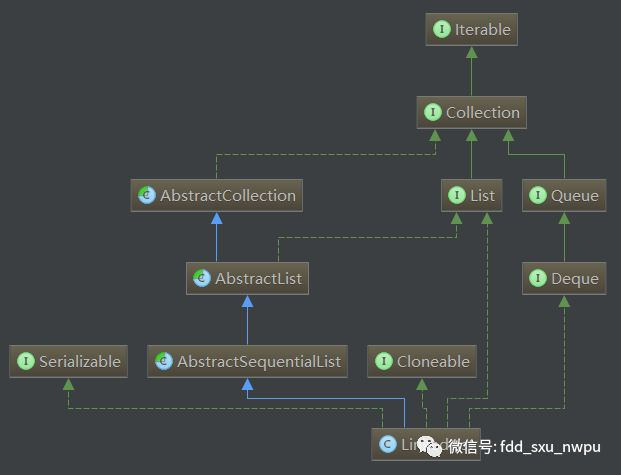

从上面我们可以看到,LinkedList继承的类与实现的接口如下:
Collection 接口、List 接口、Cloneable 接口、Serializable 接口、Deque 接口(5个接口)
AbstractCollection 类、AbstractList 类、AbstractSequentialList 类(3个类) 。
其中Deque定义了一个线性Collection,支持在两端插入和删除元素。
二、分析LinkedList
在上面从链表到继承关系,我相信你应该对LinkedList有一个基本的了解了。但是下面的分析才是最重要的一环。其实LinkedList中的增删改查操作底层就是基于链表的增删改查的操作,我们可以类比去记忆,然后自己动手去写一个LinkedList
1、Api操作分析
(1)节点Node结构
private static class Node<E> { E item;//元素值 Node<E> next;//后置节点 Node<E> prev;//前置节点 Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
从上面的node定义,我们就可以看到这是一个双向的链表。
(2)构造方法
public LinkedList() {} //调用 addAll(c) 表示将集合c所有元素插入链表中 public LinkedList(Collection<? extends E> c) { this(); addAll(c); }
(3)增加操作
首先是插入单个节点:
//在尾部插入一个节点:add public boolean add(E e) { linkLast(e); return true; } //生成新节点 并插入到链表尾部,更新last/first 节点。 void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null);//以原尾部节点为新节点的前置节点 last = newNode;//更新尾部节点 if (l == null)//若原链表为空链表,需要额外更新头结点 first = newNode; else l.next = newNode; size++; modCount++;//修改modCount } //在指定下标,index处,插入一个节点 public void add(int index, E element) { checkPositionIndex(index); if (index == size) linkLast(element); else linkBefore(element, node(index)); } //在succ节点前,插入一个新节点e void linkBefore(E e, Node<E> succ) { final Node<E> pred = succ.prev; //以前置和后置节点和元素值e 构建一个新节点 final Node<E> newNode = new Node<>(pred, e, succ); succ.prev = newNode; if (pred == null)//如果之前的前置节点是空,说明succ是原头结点。所以新节点是现在的头结点 first = newNode; else pred.next = newNode; size++; modCount++;//修改modCount }
增加操作一定会更改modCount,这里面涉及到了fail-fast机制。可以翻看我之前的文章。
(4)删除操作
//remove目标节点 public E remove(int index) { checkElementIndex(index);//这里未给出,主要是检查下表是否越界 return unlink(node(index));//从链表上删除某节点 } //从链表上删除x节点 E unlink(Node<E> x) { final E element = x.item; //当前节点的元素值 final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; //修改modCount return element; //返回取出的元素值 }
(5)更改操作
public E set(int index, E element) { checkElementIndex(index); //检查越界[0,size) Node<E> x = node(index);//取出对应的Node E oldVal = x.item;//保存旧值 供返回 x.item = element;//用新值覆盖旧值 return oldVal;//返回旧值 }
(6)查操作
public E get(int index) { checkElementIndex(index);//判断是否越界 [0,size) return node(index).item; //调用node()方法 取出 Node节点, }
(7)其他操作
public Object[] toArray() { //new 一个新数组 然后遍历链表,将每个元素存在数组里,返回 Object[] result = new Object[size]; int i = 0; for (Node<E> x = first; x != null; x = x.next) result[i++] = x.item; return result; }
2、遍历LinkedList
(1)一般的for循环(随机访问)
int size = list.size(); for (int i=0; i<size; i++) { list.get(i); }
(2)for--each循环
for (Integer integ:list)
(3)迭代器iterator
for(Iterator iter = list.iterator(); iter.hasNext();)
iter.next();
(4)用pollFirst()来遍历LinkedList
while(list.pollFirst() != null)
(5)用pollLast()来遍历LinkedList
while(list.pollLast() != null)
(6)用removeFirst()来遍历LinkedList
try { while(list.removeFirst() != null) } catch (NoSuchElementException e) { }
(7)用removeLast()来遍历LinkedList
try { while(list.removeLast() != null) } catch (NoSuchElementException e) { }
注意:在链表结构实现的数据集合中,最好采用Iterator或者foreach的方式遍历,效率最高。
小结:
(1)底层实现:LinkedList的实现是基于双向链表的,且头结点中不存放数据。
(2)构造方法:无参构造方法直接建立一个仅包含head节点的空链表;包含Collection的构造方法,先调用无参构造方法建立一个空链表,而后将Collection中的数据加入到链表的尾部后面。
(3)查找删除:源码中都划分为该元素为null和不为null两种情况来处理,LinkedList中允许元素为null。
(4)LinkedList是基于链表实现的,因此不存在容量不足的问题,所以这里没有扩容的方法。
(5)LinkedList是基于链表实现的,因此插入删除效率高,查找效率低(虽然有一个加速动作)。
(6)注意源码中还实现了栈和队列的操作方法,因此也可以作为栈、队列和双端队列来使用。

三、linkedList与ArrayList对比分析
下面将对ArrayList与LinkedList进行对比,主要从以下方面进行
相同点
1.接口实现:都实现了List接口,都是线性列表的实现
2.线程安全:都是线程不安全的,都是基于fail-fast机制
不同点
1.底层:ArrayList内部是数组实现,而LinkedList内部实现是双向链表结构
2.接口:ArrayList实现了RandomAccess可以支持随机元素访问,而LinkedList实现了Deque可以当做队列使用
3.性能:新增、删除元素时ArrayList需要使用到拷贝原数组,而LinkedList只需移动指针,查找元素 ArrayList支持随机元素访问,而LinkedList只能一个节点的去遍历