Day1
今天继续摸网页结构,我才发现关于那个获取信息的url的所有信息全在chrome F12里面有解释QAQ。
这是需要的header,似乎需要修改的只有cookies和path。path的内容下面有具体解释。
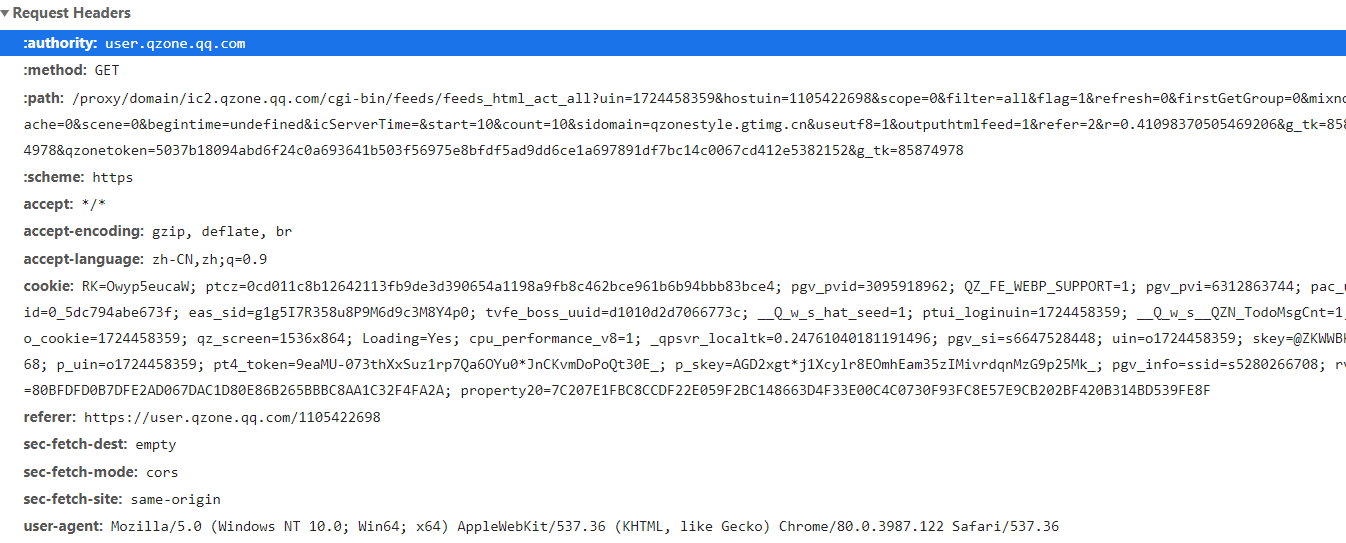
然后就是request的结构。
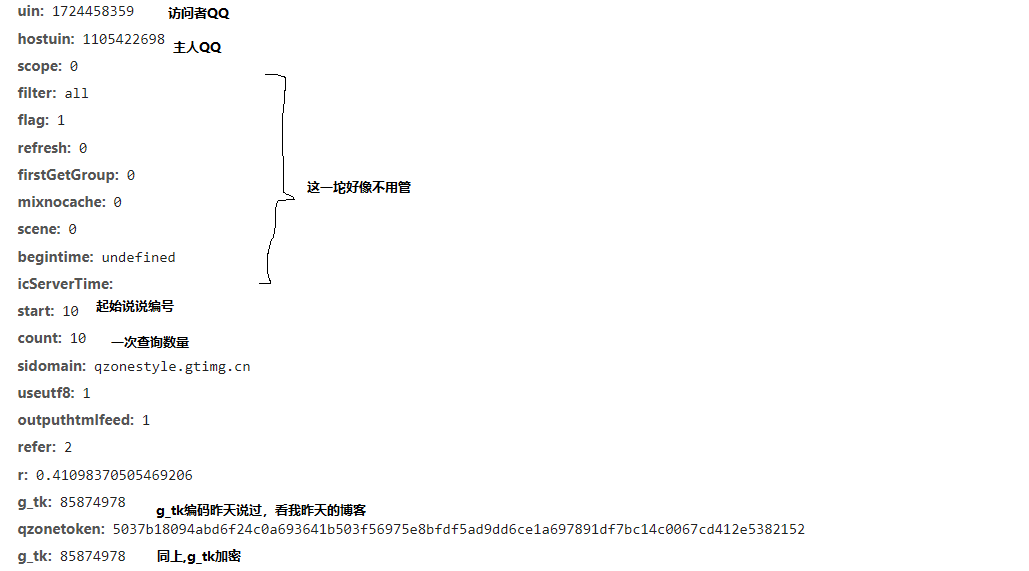
网页结构摸清楚后,就是构造session然后获得数据。
数据爬下来有点恶心,不规范的jsonp。把我搞了好久。它不仅有jsonp的头,还"key":"val"的key不加引号,解析全报错。最后问了万能群友,用了demjson解析,效率低下,但是可以用了
去头代码如下:
def loads_jsonp(_jsonp):
try:
return demjson.decode(re.match(".*?({.*}).*", _jsonp, re.S).group(1))
except:
raise ValueError('Invalid Input')总算解析出字典了QAQ。今天就差不多这些了,明天就正式开始写HTML解析和数据统计了