关于linux操作系统中进程相关问题的学习笔记
1.摘要
进程的经典定义是一个执行中程序的实例。系统中的每个程序都运行在某个进程的上下文中(contest)中。上下文是由程序运行正确运行所需的状态组成的。这个状态包括存放在内存中的程序的代码和数据,它的栈、通用目的寄存器的内容、程序计数器、环境变量以及打开文件描述符合的集合。在本次学习笔记中,我是以linux为例,学习了以下三个方面的知识:操作系统如何组织进程、进程状态如何转换以及进程是如何调度的。在最后我还谈了下自己对操作系统进程模型的一些学习心得。
2.操作系统如何组织进程
进程是由程序、数据和进程快PCB(Process Control Block)组成。进程控制块PCB是进程存在唯一标识,系统通过PCB的存在而感知进程的存在.当创建一个进程时,实际上是建立一个PCB。当进程消失时,实际上是撤销PCB。在linux中,每个进程中的PCB用一个名为task struct的结构体来表示,定义在include/linux/sched.h中。
1 struct task_struct { 2 pid_t pid; 3 pid_t tgid; 4 5 /* PID/PID hash table linkage. */ 6 struct pid_link pids[PIDTYPE_MAX]; <span style="color:#ff0000;"> </span>//一个进程ID可能是多种身份,比如Session ID,进程组ID, 进程ID,所以指向多个pid节点 7 struct list_head thread_group; 8 }
linux可以运行的进程数量可达到成千上万个(用ps 命令可查看当前进程),而这些进程又可能处于不同的状态,因此需要操作系统来管理组织它们。linux采用了以下几种方式来组织进程:
2.1哈希表
哈希表是进行快速查找的一种有效的组织方式。 L inux 在进程中引入的哈希表叫做pidhash,在include/linux/sched.h中,定义如下:
stru ct task stru ct*p idhash[ PIDHASH_SZ] ;
PIDHASH SZ 在inc lude /linux /sched. h 中定义, 其值为1024.
系统根据进程的进程号求得hash值, 加到hash表中:
#define p id hash fn(x)((((x) >>8)∧ (x))&(PIDHASH_SZ -1))
其中, PIDHASH_SZ 是表中元素的个数, 表中的元素是指向task_struct结构体的指针。pid_hashfn为哈希函数,将进程的pid转换为表的索引,通过该函数,可以将进程的pid均匀地散列在它们的域中。
函数代码如下:
#define pid_hashfn(nr, ns) \ hash_long((unsigned long)nr + (unsigned long)ns, pidhash_shift) static struct hlist_head *pid_hash; static unsigned int pidhash_shift = 4; struct pid *find_pid_ns(int nr, struct pid_namespace *ns) { struct upid *pnr; hlist_for_each_entry_rcu(pnr, &pid_hash[pid_hashfn(nr, ns)], pid_chain) if (pnr->nr == nr && pnr->ns == ns) return container_of(pnr, struct pid, numbers[ns->level]); return NULL; }
如果知道进程号, 可以通过hash表很快地找到该进程,,查找函数如下:
struct task_struct *pid_task(struct pid *pid, enum pid_type type) { struct task_struct *result = NULL; if (pid) { struct hlist_node *first; first = rcu_dereference_check(hlist_first_rcu(&pid->tasks[type]), lockdep_tasklist_lock_is_held()); if (first) //pid中的task[type] 与task_struct.pid[type].node 指向的是同一个节点 result = hlist_entry(first, struct task_struct, pids[(type)].node); <span style="color:#ff0000;"> </span>//node实体在task_struct结构中,所以可以利用first指针得到task_struct结构体指针 } return result; }
2.2双向循环链表
哈希表的主要作用是根据进程的pid可以快速找到对应的进程,但它没有反映创建的顺序,也无法反映进程之间的亲属关系,而双向循环链表可以弥补这一弱势。
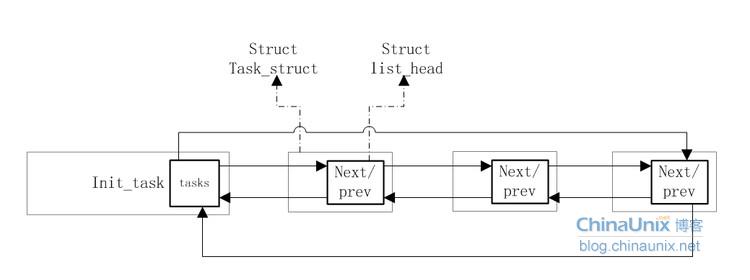
(图1,图片来源:http://blog.chinaunix.net/uid-27033491-id-3233511.html)
其对应的结构体是:
struct task_struct { ...; struct list_head tasks; ...; }; struct list_head { struct list_head *next,*prev; };
2.3运行队列
当内核要寻找一个新的进程在CPU运行时,一般只考虑那些处于可运行状态的进程,因为查找整个进程链表效率是很低的, 所以引入了可运行状态进程的双向循环链表, 也叫运行队列。运行队列容纳了系统中所有可以运行的进程, 它是一个双向循环队列, 该队列通过task _truc t结构中的两个指针run_list链表来维护。 队列的标志有两个:一个是“空进程” id le_task,一个是队列的长度。空进程是一个比较特殊的进程, 只有系统中没有进程可运行时它才会被执行, L inux 将它看作运行队列的头, 当调度程序遍历运行队列时, 是从idle_task开始、到idle_task结束的。
2.4等待队列
运行队列链表将所有状态为TASK_RUNNING 的进程组织在一起.在一起。 将所有状态为TASK _INTERRUPT IBLE和TASK_UNINTERRUPTIBLE的进程组织在一起而形成的远程链表称为等待队列。进程必须经常等待某些事件的发生, 等待队列实现在事件上的条件等待, 希望等待特定事件的进程将自己放进合适的等待队列, 并放弃控制权。 等待队列表示一组睡眠的进程, 当条件满足时, 由内核将它们唤醒。
等待队列由循环链表实现:
struct __wait_queue { unsigned int flags; #define WQ_FLAG_EXCLUSIVE 0x01 void *private; wait_queue_func_t func; struct list_head task_list; };
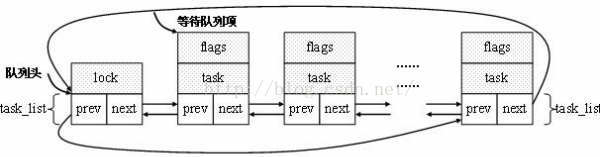
(图2,图片来源:https://blog.csdn.net/silent123go/article/details/52599210)
3.进程状态如何转换
Linux 系统中的进程有几种关键的状态,他们分别是可执行状态(TASK_RUNNING),可中断的睡眠状态(TASK_INTERRUPTIBLE),不可中断的睡眠状态(TASK_UNINTERRUPTIBLE),暂停(TASK_STOPPED),跟踪状态(TASK_TRACED),僵死状态(EXIT_ZOMBIE)和退出状态(TASK_DEAD)等。各种状态之间的关系如图3所示。这些状态主要是依据进程与CPU 之间的关系来划分的,为的是操作系统内核能对CPU 和进程进行有效地管理。
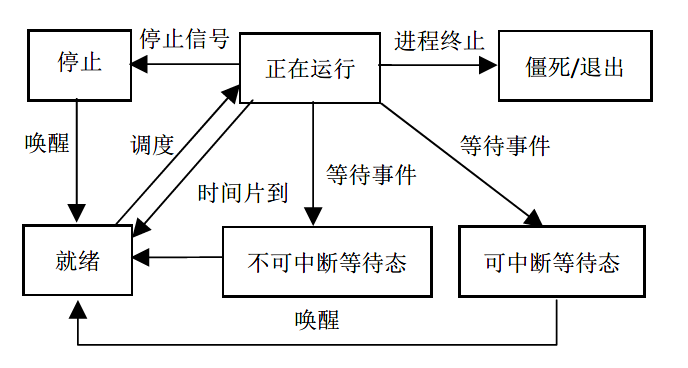
(图3,图片来源:杨兴强,刘翔鹏,刘毅.Linux进程状态演化过程的图形学表示[J].系统仿真学报,2013,25(10):2444-2448)
状态切换实在contest_switch中实现的,其函数代码如下:
static inline void context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next) { struct mm_struct *mm, *oldmm; prepare_task_switch(rq, prev, next); mm = next->mm; oldmm = prev->active_mm; /* * For paravirt, this is coupled with an exit in switch_to to * combine the page table reload and the switch backend into * one hypercall. */ arch_enter_lazy_cpu_mode(); //task->mm 为空.则是一个内核线程 if (unlikely(!mm)) { //内核线程共享上一个运行进程的mm next->active_mm = oldmm; //增加引用计数 atomic_inc(&oldmm->mm_count); enter_lazy_tlb(oldmm, next); } else //如果是用户进程,则切换运行空间 switch_mm(oldmm, mm, next); //如果上一个运行进程是内核线程 if (unlikely(!prev->mm)) { //赋active_mm为空. prev->active_mm = NULL; //更新运行队列的prev_mm成员 rq->prev_mm = oldmm; } /* * Since the runqueue lock will be released by the next * task (which is an invalid locking op but in the case * of the scheduler it's an obvious special-case), so we * do an early lockdep release here: */ #ifndef __ARCH_WANT_UNLOCKED_CTXSW spin_release(&rq->lock.dep_map, 1, _THIS_IP_); #endif /* Here we just switch the register state and the stack. */ //切换进程的执行环境 switch_to(prev, next, prev); barrier(); /* * this_rq must be evaluated again because prev may have moved * CPUs since it called schedule(), thus the 'rq' on its stack * frame will be invalid. */ //进程切换之后的处理工作 finish_task_switch(this_rq(), prev); }
4.进程如何调度
Linux系统的线程是内核线程,所以Linux系统的调度是基于线程的,而不是基于进程的。
为了实行调度,LInux系统将线程区分为三类:
(1)实时先入先出。
(2)实时轮转。
(3)分时。
实时先入先出线程具有最高优先级,它不会被其它进程抢占。实时轮转线程与实时先入先出进程基本相同,只是每个实时轮转线程都有一个时间量,时间到了之后就可以被抢占。在系统内部,实时线程的优先级从0~99,0是实时线程的最高优先级,99是实时线程的最低优先级。传统的非实时线程形成的单独的类并由单独的算法进行调度,这样可以使非实时线程不与实时线程竞争资源。在系统内部,这些线程的优先级从100-139.也就是说,Linux系统包含140个不同优先级(包括实时和非实时任务)。就像实时轮转线程一样,Linux系统根据非实时线程的要求以及它们的优先级分配CPU时间片。
这里主要学习两个调度算法:Linux O(1)调度器(O(1) scheduler)和完全公平调度器(Compleetely Fair Scheduler,CFS).
4.2 Linux O(1)调度器
schedule()是实现进程调度的主要函数,并负责完成进程切换工作.其用于确定最高优先级进程的代码非常快捷高效,它在/kernel/sched.c中的定义如下
1 task_t*prev,*next; 2 runqueue_t*rq; 3 prio_array_t*array; 4 intidx;preempt_disable(); 5 prev=current;//Linux2.6内核支持抢占,所以在对队列操作时需要设置为不可抢占rq=this_rq(); 6 array=rq->active; 7 if(unlikely(!array->nr_active)) 8 {rq->active=rq->expired; 9 rq->expired=array; 10 array=rq->active;}.
这段代码的作用是执行两个数组(活动数组rq->active和过期数组rq->expired)的切换.判断活动数组中如果没有进程了,则通过指针操作来切换两个数组.之前在过期数组中的进程时间片已经被计算好了.所以在两个数组切换后,过期数组中的进程都变为活动进程,交换数组的时间就是交换指针的时间.这种交换就是O(1)调度算法的核心.O(1)调度算法不需要从头到尾一个一个地对进程进行时间片的计算,而是通过很简单的数组切换实现进程的切换,解决了之前算法中效率低下的弊端.该过程可用图4表示.
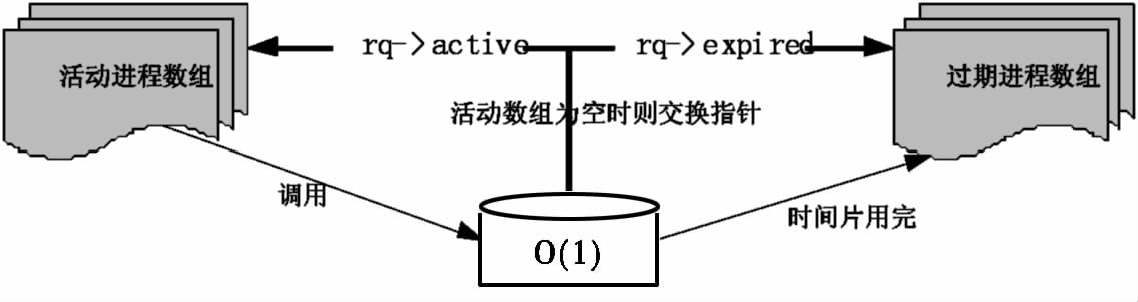
(图4,图片来源:张永选,姚远耀.Linux2.6内核O(1)调度算法剖析[J].韶关学院学报,2009,30(06):5-9.)
有了活动数组,并且各个进程都按优先级排好队等待被调度,继而就要选择候选进程了:
1 idx=sched_find_first_bit(array->bitmap); 2 queue=array->queue+idx; 3 next=list_entry(queue->next,task_t,run_list); 4 if(unlikely(next->prio!=new_prio)){dequeue_task(next,array); 5 next->prio=new_prio;enqueue_task(next,array);} 6 elserequeue_task(next,array);
首先,要在活动数组中的索引位图里找到第一个被设置的优先级位,这里通过sched_find_first_bit函数来实现.如前所述,该函数通过汇编指令从进程优先级由高到低的方向找到第一个为1的位置idx.因为优先级的个数是个定值,所以查找时间恒定,并不受系统到底有多少可执行进程的影响.这是Linux2.6内核实现O(1)调度算法的关键之一.此外,Linux对它支持的每一种体系结构都提供了对应的快速查找算法,以保证对位图的快速查找.很多体系结构提供了find-first-set指令,这条指令对指定的字操作(在Intelx86体系结构上,这条指令叫做bsfl.在IBMPPC上,cntlzw用于此目的).在这些系统上,找到第一个要设置的位所花的时间至多是执行这条指令的两倍,这也在很大程度上提高了调度算法的效率.sched_find_first_bit函数找到第一个被设置的优先级位后,再找到该优先级对应的可运行进程队列,接着找到该队列中的第一个进程,最后把找到的进程插入运行队列中.整个过程如下图5所示.图5中的网格为140位索引位图,queue[7]为优先级为7的就绪进程链表..
1 if(likely(prev!=next)){prev=context_switch(rq,prev,next);} 2 elsespin_unlock_irq(&rq->lock);
如果候选进程不是当前运行进程,则需要进行进程切换.反之,仅仅释放之前对运行队列所加的锁.
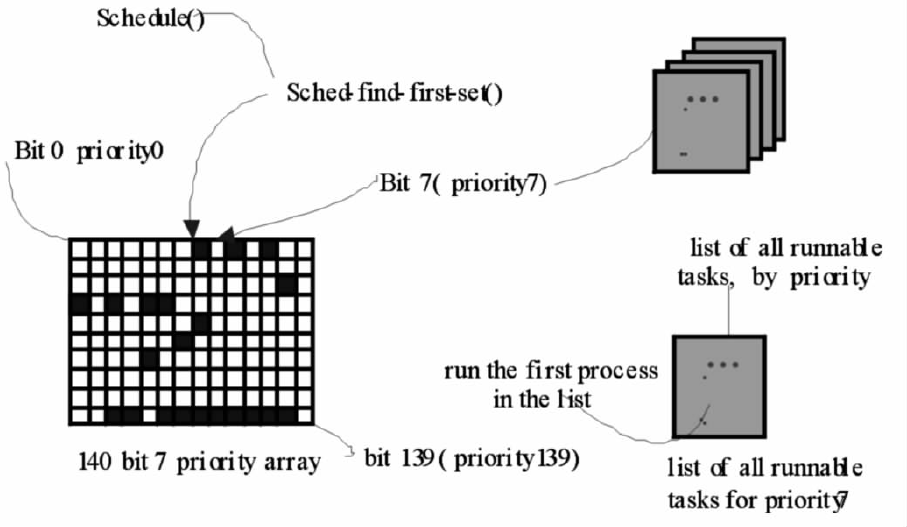
(图5,图片来源:张永选,姚远耀.Linux2.6内核O(1)调度算法剖析[J].韶关学院学报,2009,30(06):5-9.)
4.2 CFS算法
CFS的主要思想是使用一颗红黑树作为调度队列的数据结构。
第一个是调度实体sched_entity,它代表一个调度单位,在组调度关闭的时候可以把他等同为进程。每一个task_struct中都有一个sched_entity,进程的vruntime和权重都保存在这个结构中。那么所有的sched_entity怎么组织在一起呢?红黑树。所有的sched_entity以vruntime为key(实际上是以vruntime-min_vruntime为key,是为了防止溢出,反正结果是一样的)插入到红黑树中,同时缓存树的最左侧节点,也就是vruntime最小的节点,这样可以迅速选中vruntime最小的进程。注意只有等待CPU的就绪态进程在这棵树上,睡眠进程和正在运行的进程都不在树上。
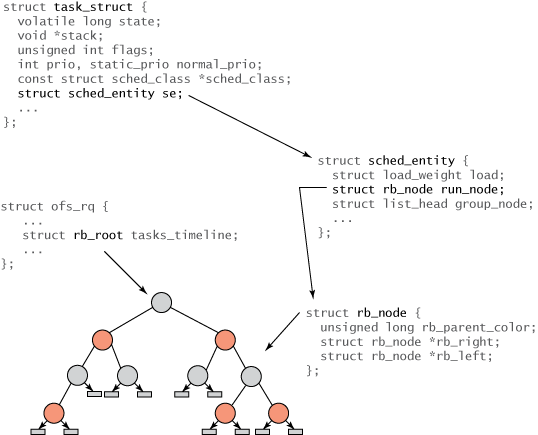
(图6:红黑树,图片来源:https://www.cnblogs.com/tianguiyu/articles/6091378.html)
CFS调度算法可以总结如下:该算法总是优先调度那些使用CPU时间最少的任务,通常是在树中最左边节点上的任务。CFS会周期性地根据任务已经停止运行的时间,递增它的虚拟运行时间值,并将这个值与最左边的值进行比较,如果正在运行的任务仍具有较小的虚拟运行时间值,那么它将继续运行,否则,它将插入到红黑树的适当位置,并且CPU将执行新的最左边节点上的任务。
代码如下(函数):
1 struct sched_class { /* Defined in 2.6.23:/usr/include/linux/sched.h */ struct sched_class *next; 2 void (*enqueue_task) (struct rq *rq, struct task_struct *p, int wakeup); 3 void (*dequeue_task) (struct rq *rq, struct task_struct *p, int sleep); 4 void (*yield_task) (struct rq *rq, struct task_struct *p); 5 void (*check_preempt_curr) (struct rq *rq, struct task_struct *p); 6 struct task_struct * (*pick_next_task) (struct rq *rq); 7 void (*put_prev_task) (struct rq *rq, struct task_struct *p); 8 unsigned long (*load_balance) (struct rq *this_rq, int this_cpu, struct rq *busiest, unsigned long max_nr_move, unsigned long max_load_move, struct sched_domain *sd, enum cpu_idle_type idle, int *all_pinned, int *this_best_prio);
void (*set_curr_task) (struct rq *rq); 9 void (*task_tick) (struct rq *rq, struct task_struct *p);
void (*task_new) (struct rq *rq, struct task_struct *p); };
函数描述
enqueue_task:当某个任务进入可运行状态时,该函数将得到调用。它将调度实体(进程)放入红 黑树中,并对 nr_running 变量加 1。
dequeue_task:当某个任务退出可运行状态时调用该函数,它将从红黑树中去掉对应的调度实体, 并从 nr_running 变量中减 1。
yield_task:在 compat_yield sysctl 关闭的情况下,该函数实际上执行先出队后入队;在这种情况 下,它将调度实体放在红黑树的最右端。
check_preempt_curr:该函数将检查当前运行的任务是否被抢占。在实际抢占正在运行的任务之 前,CFS 调度程序模块将执行公平性测试。这将驱动唤醒式(wakeup)抢占。
pick_next_task:该函数选择接下来要运行的最合适的进程。
load_balance:每个调度程序模块实现两个函数,load_balance_start() 和 load_balance_next(), 使用这两个函数实现一个迭代器,在模块的 load_balance 例程中调用。内核调度程序使用这种方 法实现由调度模块管理的进程的负载平衡。
set_curr_task:当任务修改其调度类或修改其任务组时,将调用这个函数。
task_tick:该函数通常调用自 time tick 函数;它可能引起进程切换。这将驱动运行时(running) 抢占。
task_new:内核调度程序为调度模块提供了管理新任务启动的机会。CFS 调度模块使用它进行组调 度,而用于实时任务的调度模块则不会使用这个函数。
5.我的一点学习心得
1.linux的线程调度是基于线程的,线程切换不必调用系统核心;因此调度过程是基于用户程序的,就可以针对用户程序业务逻辑选择更好的调度算法;
2.不同的算法对系统性能的影响也是不一样的,Linux的发展伴随着算法的逐渐优化;
3.进程调度是Linux操作系统的核心功能,了解进程的代码可更好去学习linux操作系统;同时进程的管理是一种复杂的并发程序设计,需要考虑到很多因素,并且它还是一个开源的操作系统,这些给我们学习带来了非常大的价值性和便利性。
6.参考资料
注:题目中已经给出的引用地址此处不再重复列出。
[1]殷联甫,沈士根,郭步.Linux进程结构及组织方式研究[J].计算机应用与软件,2005(11):61-63+143
[2]https://blog.csdn.net/bysun2013/article/details/14053937
[3]https://blog.csdn.net/lizuobin2/article/details/51785812
[4]杨兴强,刘翔鹏,刘毅.Linux进程状态演化过程的图形学表示[J].系统仿真学报,2013,25(10):2444-2448.
[5](荷)安德鲁 S。塔嫩鲍姆(Andrew S. Tanenbaum),(荷)赫伯特.博斯(Herbert Bos)著:陈向群等译,现代操作系统(原书第四版),机械工业出版社,2017
[6]张永选,姚远耀.Linux2.6内核O(1)调度算法剖析[J].韶关学院学报,2009,30(06):5-9.
[7]https://www.cnblogs.com/tianguiyu/articles/6091378.html
[8]http://www.360doc.com/content/15/0922/01/12144668_500602693.shtml