MR执行流程:
(1).客户端提交一个mr的jar包给JobClient(提交方式:hadoop jar ...)
(2).JobClient通过RPC和ResourceManager进行通信,返回一个存放jar包的地址(HDFS)和jobId
(3).client将jar包写入到HDFS当中(path = hdfs上的地址 + jobId)
(4).开始提交任务(任务的描述信息,不是jar, 包括jobid,jar存放的位置,配置信息等等)
(5).ResourceManager进行初始化任务
(6).读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个MapperTask
(7).NodeManager通过心跳机制领取任务(任务的描述信息)
(8).下载所需的jar,配置文件等
(9).NodeManager启动一个java child子进程,用来执行具体的任务(MapperTask或ReducerTask)
(10).将结果写入到HDFS当中

Hadoop中的数据使用RPC协议在网络中传播时,需要实现序列化。而Hadoop并没有使用JDK默认的序列化机制(JDK原生的序列化机制效率较低),而是使用了自己的序列化机制。因此我们在传递参数时,有时候需要手动实现序列化。这是一个要注意的地方。
在Linux下使用maven进行开发:
maven的jar包会下载大用户主目录的.m2的文件下。
maven工程的pom.xml文件对maven进行一些配置
<!--可以使maven从网络上下载所需的包-->
<dependency>
<groupId>org.apache.maven.plugins</groupId><artifactId>maven-resources-plugin</artifactId>
<version>2.4.3</version>
</dependency>
一些common包:
<dependency>
<groupID>org.apache.hadoop</groupID>
<artifactID>hadoop-commen</artifactID>
<version>2.2.0</version>
</dependency>
还需要引入hdfs的依赖包
<dependency>
<groupID>ort.apache.hadoop</groupID>
<artifactID><hadoop-hdfs</artifactID>
<version>2.2.0</version>
</dependency>
需要引入MapReduce依赖:
<dependency>
<groupID>org.apache.hadoop</groupID>
<artifactID>hadoop-mapreduce-client-core</artifactID>
<version>2.2.0</version>
</dependency>
对于main方法,里面要设置job,mapper和reducer的部分信息:
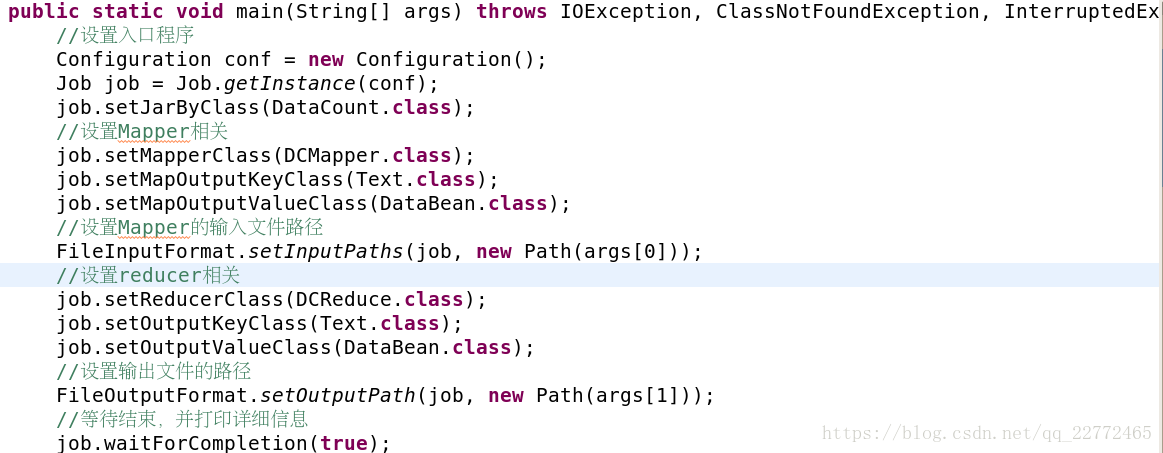
mapper和reducer我们以内部类的形式完成。
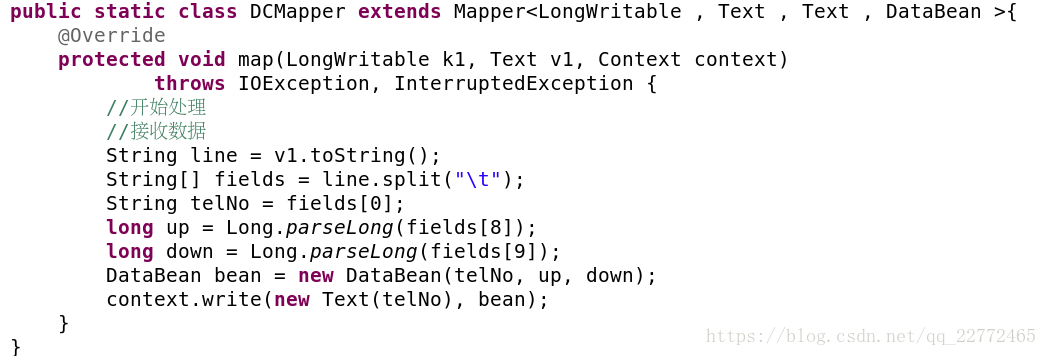
mapper:
reducer:
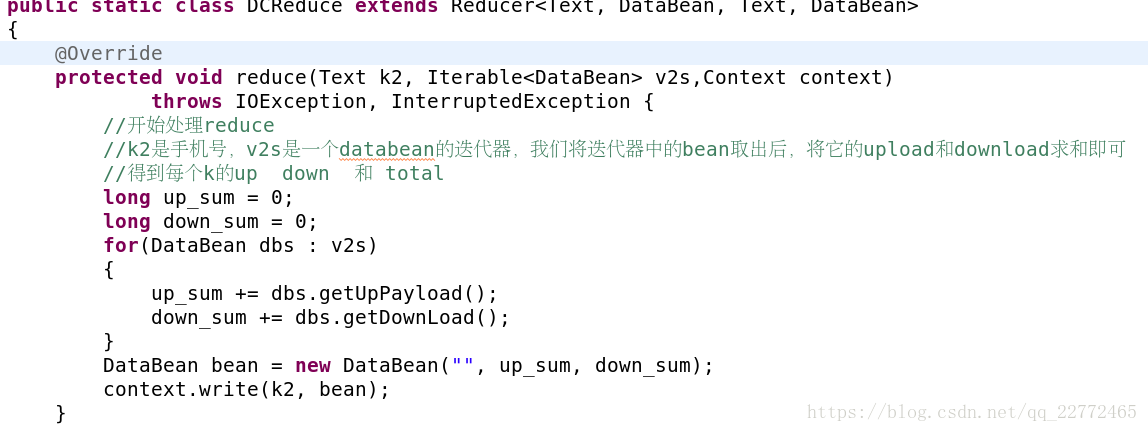
需要注意的是数据的形式,因为value并不是一个值,因此我们将它封装到bean中,而bean有些需要注意的地方:

主要就是序列化和反序列化的部分。因为hadoop不使用jdk的默认序列化机制(效率太低),因此我们自己要实现序列化。DataBean应该事先writable接口,并实现readFiles和write方法,并且写出和读入的顺序必须一一对应。