一、背景及概览
阿里内部版本Blink首次合并入Flink,并于2019年8月22日,正式发布Apache Flink 1.9.0 版本。
Flink1.9版本变化官方文档
- 更新概述:
- 架构升级
- 新功能和改进
- 细粒度批作业恢复 (FLIP-1)
- State Processor API (FLIP-43)
- Stop-with-Savepoint (FLIP-34)
- 新 Blink SQL 查询处理器预览
- Table API / SQL 的改进
- 重构 Flink WebUI
- Hive 集成预览 (FLINK-10556)
- 新 Python Table API 预览 (FLIP-38)
- 重要变化
- Flink 发行版默认配置Table API 和 SQL
- 移除机器学习类库(flink-ml)
- 删除旧的DataSet 和 DataStream python API
- 支持java9(外部系统进行交互的部分组件(connectors,文件系统,reporters)暂不支持java9)
二、架构升级
新版Flink1.9在流批融合的方向上迈进了一大步。
旧版架构:
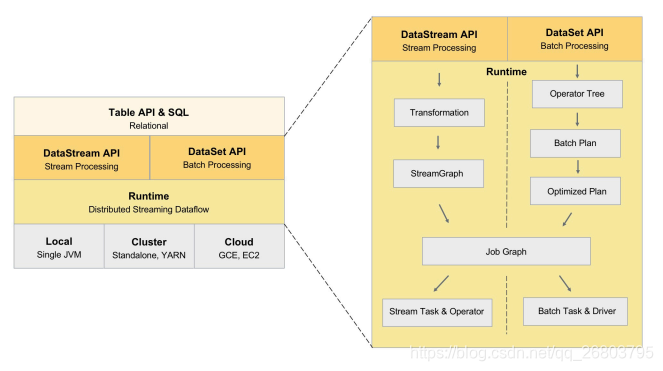
- 旧版处理方式:旧版Flink在其分布式流式执行引擎之上,有两套相对独立的DataStream 和 DataSet API,分别来描述流计算和批处理的作业。在这两个API之上,则提供了一个流批统一的API,即 Table API 和 SQL。用户可以使用相同的Table API 程序或者 SQL 来描述流批作业(在运行时需要告诉Flink引擎希望以流的形式运行还是以批的形式运行),此时 Table 层的优化器就会将程序优化成 DataStream 作业或者DataSet 作业。上图右半部分是DataStream 和 DataSet 底层的实现细节,其实两者共享的模块很少,它们有各自独立的翻译和优化的流程,而且在真正运行的时候,两者也使用了完全不同的Task。这样的不一致对用户和开发者来讲可能存在问题。
- 旧版存在的问题:由于DataStream和DataSet这两个API不仅语义不同,同时支持的 connector 种类也不同,在开发者编写作业的时候当需要在两套 API 之间进行选择时,会造成一些困扰,难以做到代码的复用(我们在开发一些新功能的时候,往往需要将类似的功能开发两次,并且每种 API 的开发路径都比较长,基本都属于端到端的修改,这大大降低了我们的开发效率)。Table 尽管在 API 上已经进行了统一,但因为底层实现还是基于 DataStream 和 DataSet,也会受到刚才不一致的问题的影响。
新版架构:
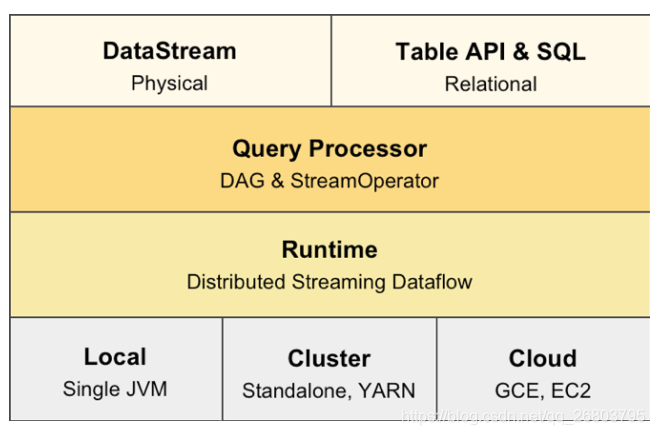
在新版架构中,Flink将舍弃DataSet API,用户的API主要会分为偏描述物理执行计划
的 DataStream API 以及偏描述关系型计划的 Table & SQL。
- DataStream API:用户自行描述和编排算子的关系,引擎不会做过多的干涉和优化。
- Table API & SQL:继续保旧版本在的风格,提供关系表达式API,引擎会根据用户的意图来进行优化,并选择最优的执行计划。
- 流批一体:以后这两个 API 都会各自同时提供流计算和批处理的功能。这两个用户API之下,在实现层它们都会共享相同的技术栈,比如会用统一的 DAG 数据结构来描述作业,使用统一的StreamOperator来编写算子逻辑,包括使用统一的流式分布式执行引擎。
三、新功能和改进
1. 细粒度批作业恢复 (FLIP-1)
- 上图:
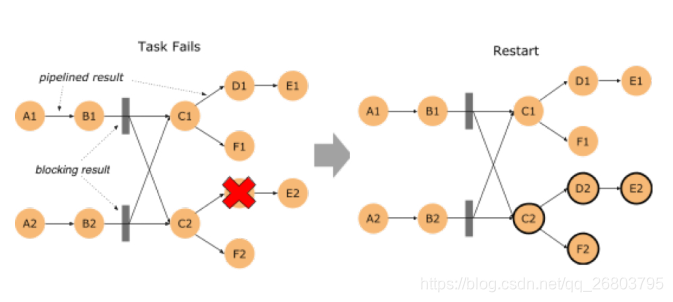
- 批作业恢复是什么: 当批作业(DataSet、Table API 和SQL)中的某个task失败后,需要对其进行恢复的故障策略。
- 旧版本处理方式:在Flink1.9之前是通过取消所有task并重新启动整个作业来恢复,也就之前已运行是所有的进度都会废弃。
- 新版本处理方式:在1.9版本中Flink会将中间结果保留在网络shuffle的边缘,然后使用这些数据来恢复失败的tasks(处在同一个 failover region (故障区)的 tasks)。故障区:指通过pipelined 数据交换方式(Flink在网络传输层上的一种传输方式,即一条数据处理完立刻传输给下一个节点处理)连接的 tasks 集合,因此作业中 batch-shuffle 的连接定义了故障区的边界。
- 怎么使用:首先需要确保flink-conf.yaml 中有jobmanager.execution.failoverstrategy: region 的配置(Flink1.9 发布包默认已经包含,当从低版本升级过来时,需要手动加上该配置);其次还需要在 ExecutionConfig 中,将 ExecutionMode 设置成 BATCH,这样批作业才能有多个故障区。
- “Region” 的故障策略也能同时提升 “embarrassingly parallel” 类型的流作业恢复速度,也就
是不包含任何像 keyBy、rebalance 等 shuffle 的作业。当这种作业在恢复时,只有受影响的故障
区 task 需要重启。对于其他类型的流作业,故障恢复行为与之前的版本一样。
2. State Processor API (FLIP-43)
- 为什么引入状态处理API:旧版本当我们从外部访问作业的状态时仅局限于:Queryable State(可查询状态)实验性功能,1.9新版本中引入了State Processor API这一种强大类库,基于 DataSet 支持读取、写入、和修改状态快照(支持所有类型的快照:savepoint,full checkpoint 和 incremental checkpoint)。
- 在实践中有什么用:
- Flink作业的状态可以自主构建,通过读取外部系统的数据(例如外部数据库),转换成savepoint。
- 在进行应用程序审核或故障排查时可以使用任意的 Flink 批处理 API 查询(DataSet、Table、SQL)Savepoint 中的状态。
- 支持离线迁移Savepoint 中的状态 schema(旧版本只能在访问状态时进行,属于在线迁移)。
- 可以识别并纠正Savepoint 中的无效数据。
3. Stop-with-Savepoint (FLIP-34)
- 为什么引入Stop-with-Savepoint:在1.9版本之前已经有了"Cancel-with-savepoint",是停止、重启、fork、或升级 Flink 作业的一个常用操作。但是这个cancel的实现没有保证输出到exactly-once sink 的外部存储的数据持久化,为了改进当停止作业时的端到端语义,Flink 1.9 引入了一种新的 SUSPEND 模式,可以带 savepoint 停止作业,保证了输出
数据的一致性。使用 Flink CLI 来 suspend 一个作业 bin/flink stop -p [:targetSavepointDirectory] :jobId
4. 新 Blink SQL 查询处理器预览
- 上图:

- 产生背景:由于Blink的Table模块已经使用了Flink的新版架构,为了尽量不影响之前版本用户的体验,需要找到一个方法让两种架构能够并存。
- 如何实现:首先将 flink-table 单模块重构成了多个小模块(对于 Java
和 Scala API 模块、优化器、以及 runtime 模块来说,有了一个更清晰的分层和定义明确的接口);然后提出了 Planner 接口以支持多种不同的Planner实现(扩展了 Blink 的planner以实现新的优化器接口,所以现在有两个插件化的查询处理器来执行 Table API 和 SQL),Planner将负责具体的优化和将Table作业翻译成执行图的工作,我们可以将旧版本的实现全部挪至 Flink Planner中,然后把对接新架构的代码放在 Blink Planner 里。 - 支持情况:1.9 以前的 Flink 处理器和新的基于 Blink 的处理器。基于 Blink
的查询处理器提供了更好地 SQL 覆盖率(1.9 完整支持 TPC-H,TPC-DS 的支持计划在下一个版本实现)并通过更广泛的查询优化(基于成本的执行计划选择和更多的优化规则)、改进的代码生成机制、和调优过的算子实现来提升批处理查询的性能。 - 还支持更强大的流处理能力:新功能(如维表Join,TopN,去重)和聚合场景缓解数据倾斜的优化,以及内置更多常用的函数。
- Blink Query Processor:

- 注意:Blink 的查询处理器尚未完全集成。因此,1.9 之前的 Flink处理器仍然是 1.9版本的默认处理器,建议用于生产设置。可以在创建TableEnvironment时通过EnvironmentSettings配置启用Blink处理器。被选择的处理器必须要在正在执行的 Java进程的类路径中。对于集群设置,默认两个查询处理器都会自动地加载到类路径中。当从 IDE中运行一个查询时,需要在项目中显式地 增加一个处理器的依赖。
5. Table API / SQL 的其它改进
- 为 Table API / SQL 的 Java 用户去除 Scala 依赖 (FLIP-32)
由于新版本对flink-table模块进行了重构和拆分,因此Flink1.9为Java和Scala创建了两个单独的API模块。在使用Table API 和 SQL时,java用户不需要再额外引用一堆Scala依赖了。 - 重构 Table API / SQL 的类型系统(FLIP-37)
为了从 Table API 中移除对 Flink TypeInformation 的依赖,并提高其对SQL标准的遵从性,Flink 1.9 实现了一个新的数据类型系统。不过这个新的数据系统还在还在实现中,预计将在下一版本完工,并且在 Flink 1.9中,UDF 尚未移植到新的类型系统上。 - Table API 的多行多列转换(FLIP-29)
Table API 扩展了一组能够支持多行和多列、输入和输出的转换功能。极大的简化了处理逻辑的实现,同样的逻辑如果使用旧版本的关系运算符来实现就会相对麻烦。 - 新的统一的 Catalog API
为了Hive集成,Flink开发出了崭新的 Catalog 接口以统一处理内外部的 catalog 及元数据。在集成了Hive的同时也全面提升了Flink在管理catalog元数据的整体便利性,比如在旧版本中通过 Table API 或 SQL 定义的表都无法持久化保存,而在Flink1.9新版本中,这些表的元数据可以被持久化到 catalog 中。这意味着用户可以在 Hive Metastore Catalog 中创建 Kafka
表,并在 query 中直接引用该表。 - SQL API 中的 DDL 支持 (FLINK-10232)
在旧版本中Flink SQL 已经支持 DML 语句(如 SELECT,INSERT)。但是外部表(table source 和 table sink)必须通过 Java/Scala 代码或配置文件的方式注册。1.9 版本中,支持 SQL DDL 语句的方式注册和删除表(CREATE TABLE,DROP TABLE)。不过目前还没有增加流特定的语法扩展来定义时间戳抽取和 watermark 生成策略等。流式的需求也将会在下一版本中完整支持。
6. 重构 Flink WebUI
新版Flink的WebUI基于Angular 的最新稳定版进行了重构,旧版本到新版本分别从 Angular 1.x 跃升到了 7.x。在新版依然保留旧版的UI,但未来会完全移除旧版WebUI
7. Hive 集成预览 (FLINK-10556)
- Hive Metastore : Hive作为hadoop生态圈里广泛用于存储和查询海量结构化数据的系统,除了作为查询处理器外,还提供了一个叫做Metastore 的 catalog来管理和组织大数据集。当与 Hive 的 Metastore 集成后,便能够利用 Hive 管理的数据。
- 新版本为 Flink Table API 和 SQL 实现一个连接到 Hive Metastore 的外部 catalog,在Flink 1.9 中,用户能够查询和处理存储在 Hive 中多种格式的数据,并且还可以使用Hive的UDF。
- 旧版本里的Table API / SQL 中定义的表一直是临时的,在新版本中,新的 catalog 连接器允许在 Metastore 中持久化存储那些使用 SQL DDL 语句创建的表。因此,可以直接连接到 Metastore并注册一个表,例如,Kafka topic 的表。从现在开始,只要 catalog 连接到 Metastore,就可以查询该表。
- 注意:新版本提供的Hive支持还处于实验性质,在下个版本中会稳定这些功能。
8. 新 Python Table API 预览 (FLIP-38)
- 怎么实现的:Flink将持续完善对Python的支持作为自己的目标,在Flink1.9版本引入了 Python Table API 的首个版本,该版本围绕着 Table API 设计了很薄的一层 Python API包装器,基本上将 Python Table API方法的调用都转换为 Java Table API 调用。
- 支持情况:Python Table API 尚不支持 UDF,只是标准的关系操作,后续会进行规划。
- 如何使用:需要手动安装PyFlink,然后才能使用。
四、重要变化
- Table API 和 SQL 现在是 Flink 发行版的默认配置的一部分。以前,必须通过将相应的 JAR 文件从 ./opt 移动到 ./lib 来启用 Table API 和 SQL。
- 为了准备 FLIP-39,机器学习类库(flink-ml)已经被移除了。
- 旧的 DataSet 和 DataStream Python API 已被删除,建议使用 FLIP-38 中引入的新 Python API。
- Flink1.9 支持java9进行编译和运行。请注意,与外部系统(connectors,文件系统,reporters)交互的某些组件可能无法工作,目前相应的项目可能不支持 Java 9。
