业务场景:
某银行生产环境下,hdfs集群中一个datanode节点,总共有12块数据盘,分别存储data1–data12,其中由于某些原因/data8没有挂载数据盘,导致集群数据存在了系统盘,系统盘大小500G,今天发现磁盘空间占满,对此解决方案如下:
1、登录ambari管理界面,进入hdfs和yarn,选择指定节点,停止datanode、nodemanager服务运行
2、格式化磁盘
mkfs.ext4 /dev/vdx(x为磁盘编号,比如vdb、vdc)
3、备份数据
看下其他盘空间是否够大,通过mv命令将目录移到其他路径,要进入数据目录后mv
4:挂载data8
mount /dev/vdx /data8
5:修改fstabe
/dev/vdx /data8 ext4 default 0 0
6:启动datanode,nodemanager
ambari管理界面启动
7:确认后删掉备份数据
rm -r
8、观察datanode、nodemanager日志,无报错,启动正常
9、对于新加入的磁盘进行balance,步骤如下:
切换hdfs用户
su - hdfs
hdfs客户端从namenode上读取指定datanode的必要信息以生成执行计划
hdfs diskbalancer -plan slave11
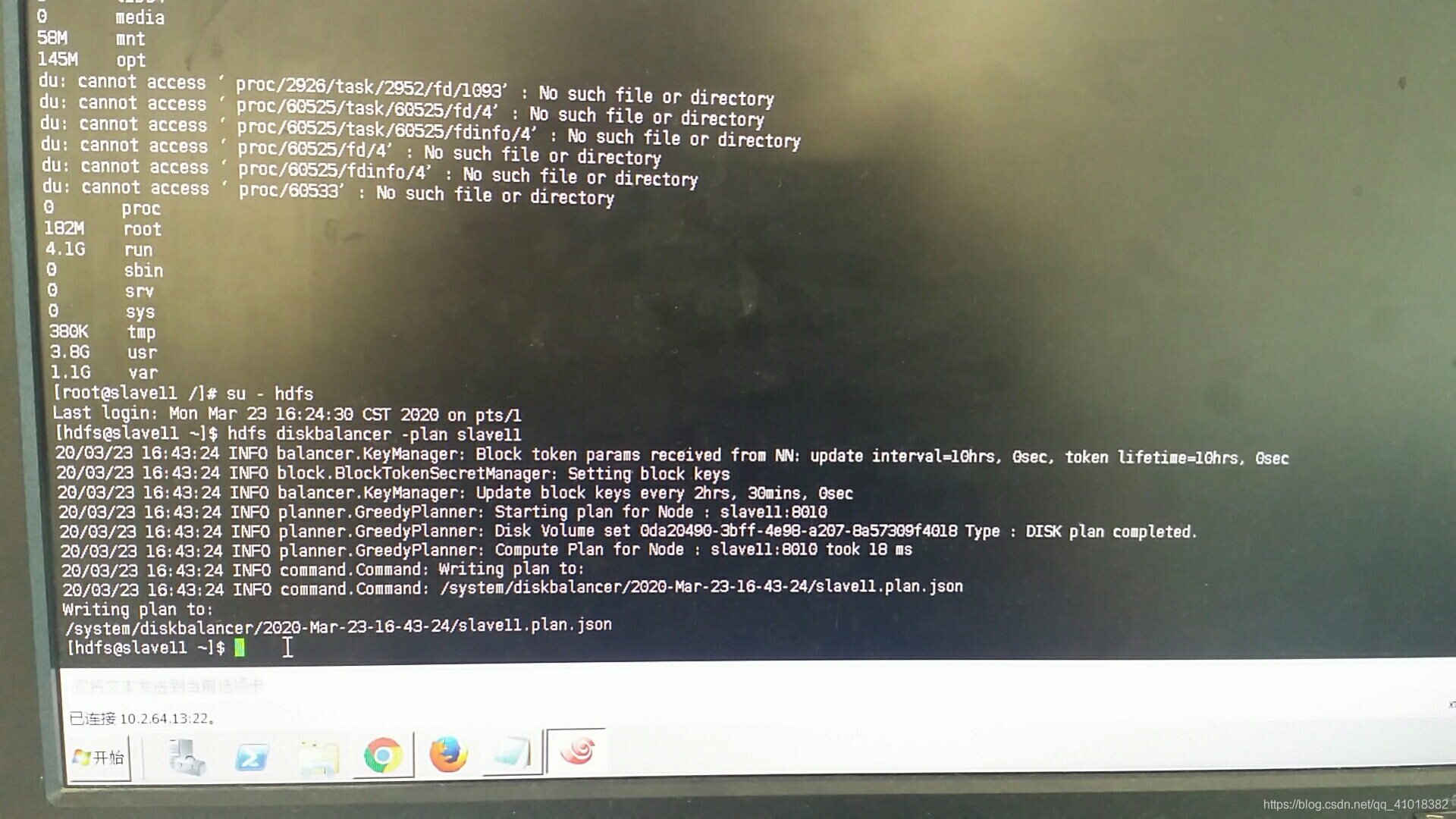
磁盘平衡执行计划生成的文件内容格式是Json的,并且存储在HDFS之上。在默认情况下,这些文件是存储在 /system/diskbalancer 目录下面
hadoop fs -ls /system/diskbalancer/2020-Mar-23-16-43-24/slave11-plan.json
文件内容如下
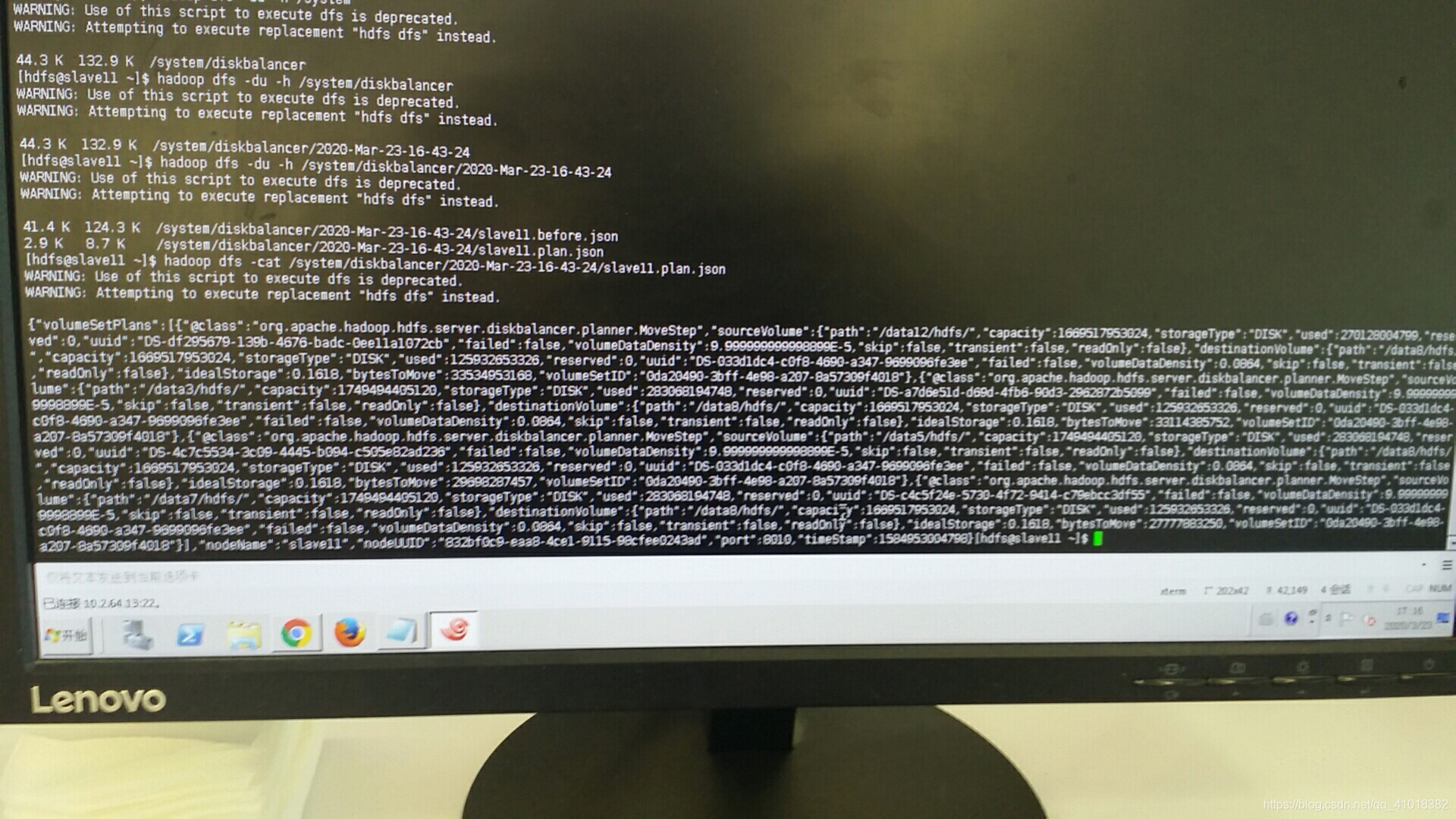
执行json文件
hdfs diskbalancer -execute /system/diskbalancer/2020-Mar-23-16-43-24/slave11-plan.json
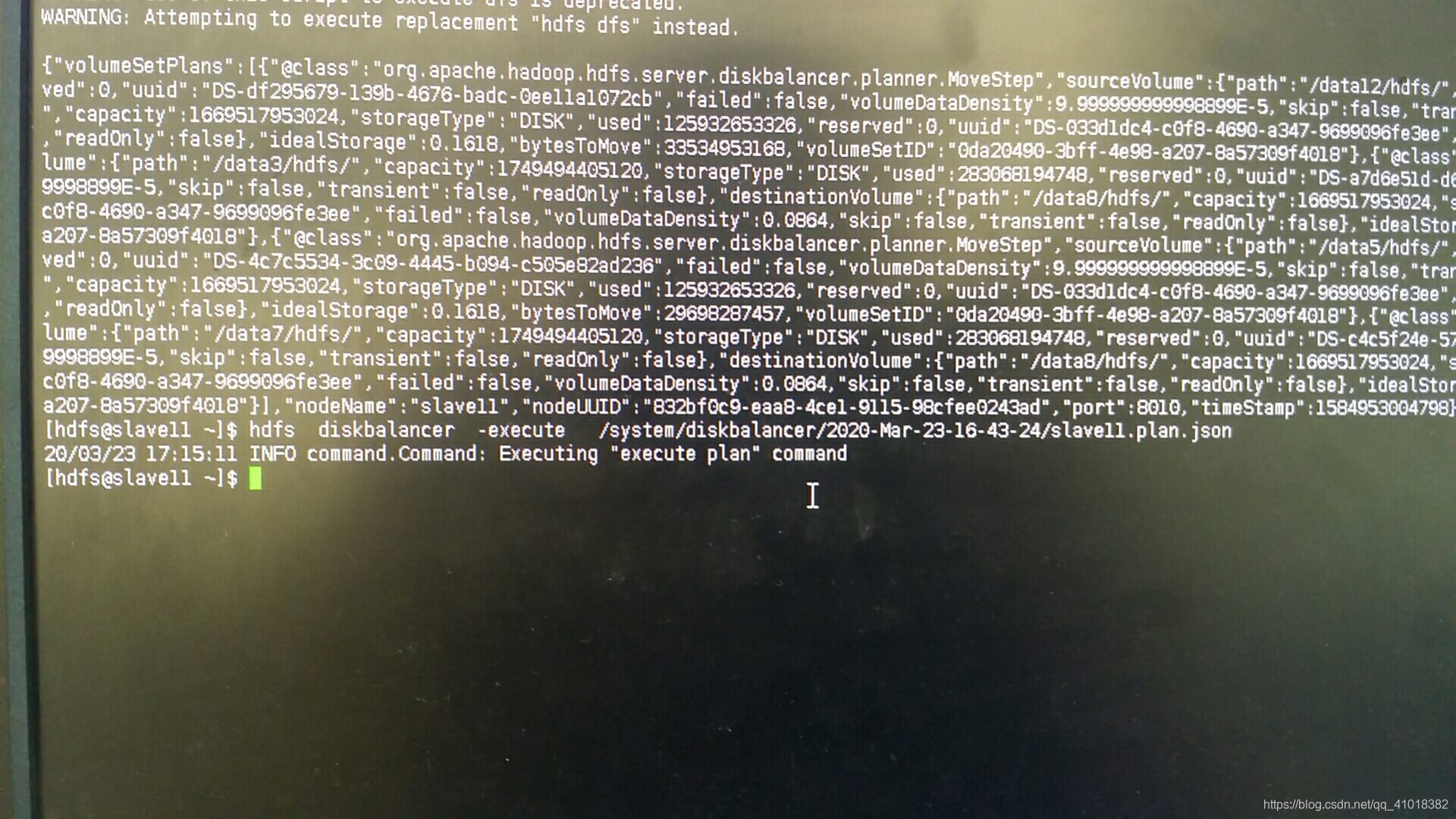
从以上json文件可以看出,sourceVolume:/data12、/data3、/data5、/data7 to /data8
查询执行状态和结果
hdfs diskbalancer -query slave11:8010
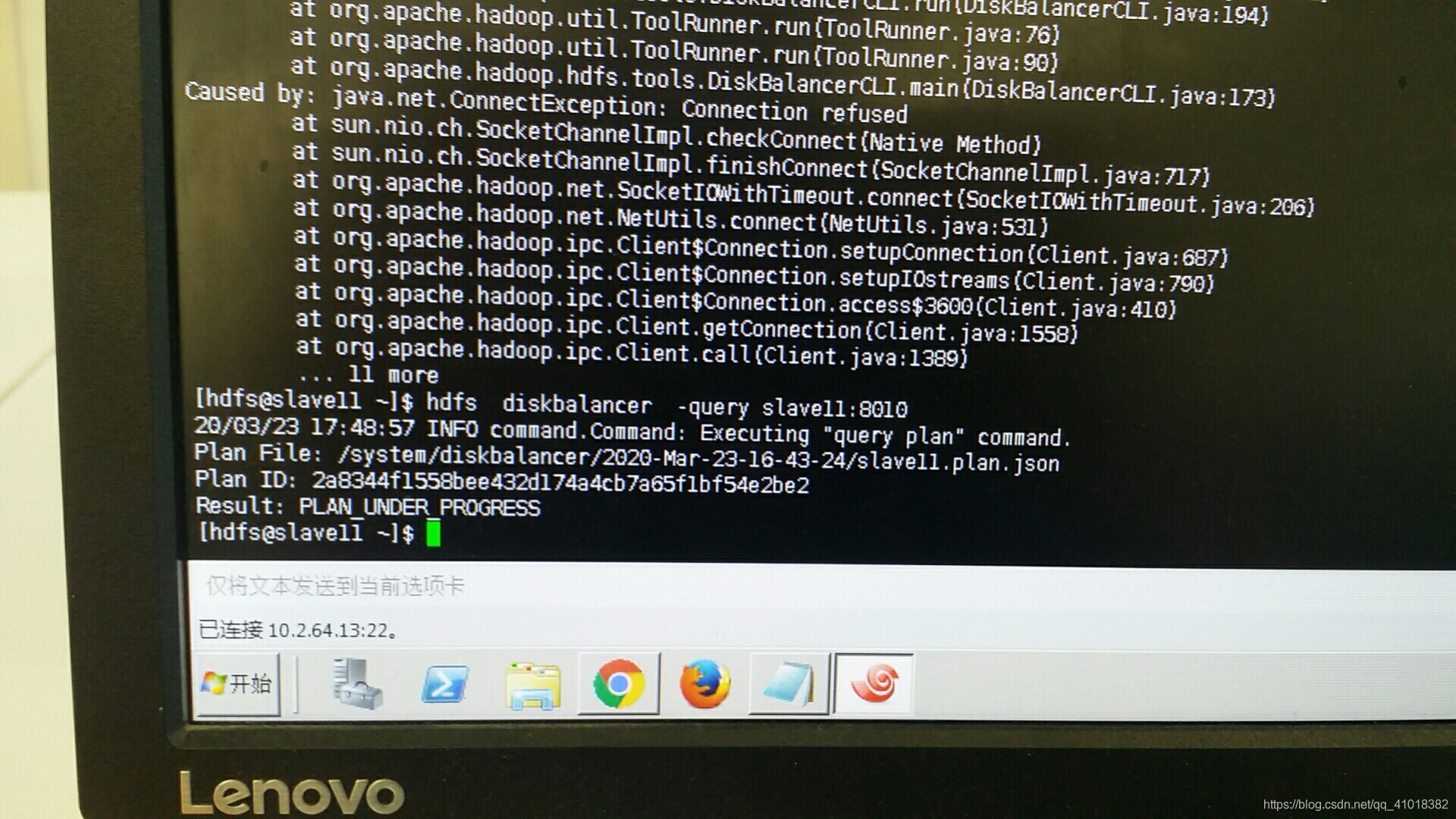
以上查询结果只要更新为:PLAN_DONE说明balance完成
