1.激活函数
- 参考文献
- Rectified Linear Unit(ReLU) - 用于隐层神经元输出
- Sigmoid - 用于隐层神经元输出
- tanh-用于隐层神经元输出
- Softmax - 用于多分类神经网络输出
- Linear - 用于回归神经网络输出(或二分类问题)
ReLU函数计算如下:
Sigmoid函数计算如下:
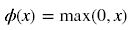
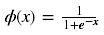
tanh函数计算如下:
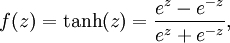
Softmax函数计算如下:
Softmax激活函数只用于多于一个输出的神经元,它保证所以的输出神经元之和为1.0,所以一般输出的是小于1的概率值,可以很直观地比较各输出值。
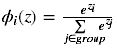
2.损失函数
-
softamx cross entropy loss
softmax 交叉熵损失函数是我们常用的一种损失函数,其公式如下:
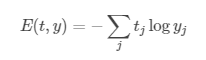
其中,t 和 y 分别表示神经网络的目标标签和输出, yj 表示softmax损失函数: 
需要注意的一点就是这个公式需要输入没有经过缩放变换的logits,还有就是使用本目标损失函数的时候不要在网络的最后一层使用softmax层或者激活函数,会导致结果不正确。
-
Categorical Crossentropy
交叉熵损失函数是也是常用的一种损失函数,它表示预测值y与目标值t之间的距离。主要应用在互相排斥的分类任务中,公式为:
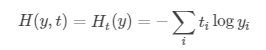
-
Binary Crossentropy
这个损失函数主要是用来计算预测值y与目标值t之间的sigmoid交叉熵,主要用来多分类任务中,但是这个分类任务不是互斥的,和上面的损失函数不同,这个对同一个输入可以输出多个标签。公式为:
![]()
为了防止溢出,我们进行如下变换:
-
Weighted Crossentropy
主要用来计算神经元之间的权值的交叉熵损失函数,t表示目标标签,y表示输入的预测值。该损失函数和上一个损失函数很像,唯一一点不同的就是:
该损失函数允许对负误差或者正误差加权 来调整precision 和recall
一般的交叉损失函数为: ![]()
当我们乘上 pos_weight 之后的公式就变成: ![]()
为了避免溢出,我们将公式变为:![]()
其中,l 表示:
-
Mean Square Loss
这个损失函数就很常见了,t 表示目标值,y 表示预测值输出。公式为:
-
Hinge Loss
这个也是很常见的一个loss函数, t 表示目标值,y 表示预测值输出。公式为: ![]()
