DL_本文多数来自网络参考
深度学习有着很好的处理线性补不可分的能力
1.聚类:
是一种典型的将无监督学习,是把物理对象或抽象对象的集合分组为由彼此类似的对象组成的多个类的分析过程
基本思路:都是利用每个向量之间的”距离”–欧几里得距离或曼哈顿距离
2.回归
线性回归:
y=wx+by=wx+b
逻辑回归:
y=11+e−z,z=wx+by=11+e−z,z=wx+b
3.召回率&精确率:

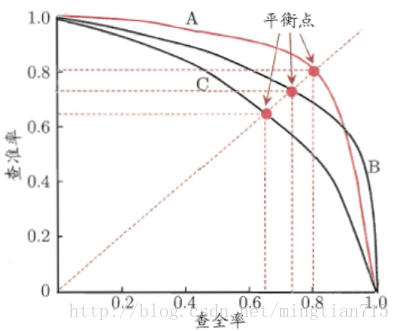
mPA:查准率Precision、查全率Recall。对于object detection任务,每一个object都可以计算出其Precision和Recall,多次计算/试验,每个类都 可以得到一条P-R曲线,曲线下的面积就是AP的值,这个mean的意思是对每个类的AP再求平均,得到的就是mPA的值,mPA的大小一定在[0,1]区间。
4.end to end
直接输入原始数据(或者很少的一些归一化,白化登处理,通常不需要人来做特征提取),直接输出最终目标的一种思想。
5.神经元组成

两部分:线性模型和激励函数
线性模型:y=wx+b
激励函数:跟在y=wx+b,用来加入一些非线性因素
6.神经网络组成
输入层(不对数据进行任何处理,通常不计入层数),隐藏层,输出层
7.残差
拟合和真实观测的差异之和,即:Loss=∑ni=1|wxi+b−yi|拟合和真实观测的差异之和,即:Loss=∑i=1n|wxi+b−yi|
8.前馈神经网络
各神经元从输入层开始,接收前一级输入,并输入到下一级,直至输出层,整个网络中无反馈
组成:反向传播网络(BP网络) 和 径向基函数网络(RBF Network)
9.牛顿法

10.梯度下降
Loss=∑ni=1|wxi+b−yi|Loss=∑i=1n|wxi+b−yi|
单维:wn+1=wn−ηdLossdw单维:wn+1=wn−ηdLossdw
二维:wn+1=wn−η∂Loss∂w;bn+1=bn−η∂Loss∂b二维:wn+1=wn−η∂Loss∂w;bn+1=bn−η∂Loss∂b
多维度:▽=(∂w∂w1,∂w∂w2,…,∂w∂w1000)多维度:▽=(∂w∂w1,∂w∂w2,…,∂w∂w1000)
11.全连接网络
神经元彼此之间连接的方式有一个特点,那就是每一个神经元节点的输入都来自于上一层的每一个神经元的输出
缺点:由于整个网络都是全连接方式,所以w和b格外多,这就使得训练过程中所要更新的权重非常多,整个网络的收敛也会非常慢
12.卷积神经网络
是一种前馈神经网络,它的神经元可以响应一部分覆盖范围内的周围单元,对于大规模的模式识别都有着非常好的性能表现
特征:
- 卷积网络至少有一个卷积层,用来提取特征
- 卷积网络的卷积层通过权值共享的方式进行工作,大大减少权值w的数量,使得在训练中同样识别率的情况下的收敛速度明显快于全连接BP网络
13.卷积的定义
我们称 (f*g)(n) 为 f,g 的卷积
其连续的定义为:(f∗g)(n)=∫∞−∞f(τ)g(n−τ)dτ其离散的定义为:(f∗g)(n)=∑τ=−∞∞f(τ)g(n−τ) 其连续的定义为:(f∗g)(n)=∫−∞∞f(τ)g(n−τ)dτ其离散的定义为:(f∗g)(n)=∑τ=−∞∞f(τ)g(n−τ)
图像卷积,特征提取,降采样
卷积核:f(x)=wx+b,w,b由训练得到,在卷积和的f(x)=wx+b输出后还可能会跟着一个激励函数,一般喜欢用ReLu卷积核:f(x)=wx+b,w,b由训练得到,在卷积和的f(x)=wx+b输出后还可能会跟着一个激励函数,一般喜欢用ReLu
多核卷积:
如权值共享的部分所说我们用一个卷积核操作只能得到一部分特征可能获取不到全部特征,这么一来我们就引入了多核卷积。用每个卷积核来学习不同的特征(每个卷积核学习到不同的权重)来提取原图特征。
Pading的用途:
1.保持边界信息.因为如果不加Pading的话,最边缘的像素点信息其实仅仅被卷积核扫描了一遍,而图像中间的像素点会被扫描多遍
2.如果输入的图片尺寸有差异,可以通过Pading来进行补齐,使得输入的尺寸一致,以免频繁的调整卷积核和其它层的工作模式
Stride:每次滑动的单位,一般取1的多,取的太大,会导致跳过的像素列的信息明显扫描次数低了
14.池化层(General Pooling)
池化作用于图像中不重合的区域(这与卷积操作不同),过程如下图。

我们定义池化窗口的大小为sizeX,即下图中红色正方形的边长,定义两个相邻池化窗口的水平位移/竖直位移为stride。一般池化由于每一池化窗口都是不重复的,所以sizeX=stride。
最常见的池化操作为平均池化mean pooling和最大池化max pooling:
平均池化:计算图像区域的平均值作为该区域池化后的值。
最大池化:选图像区域的最大值作为该区域池化后的值。
作用:
1.又进行了一次特征提取,可减少下一层数据的处理量
2.由于这个特征的提取,能够有更大可能性进一步获取更为抽象的信息,从而防止过拟合,或者说提高一定的泛化性
3.由于这种抽象性,所以能够对输入的微小变化产生更大的容忍,也就是保存其不变性,容忍包括少量平移,旋转和缩放等变化
池化层在CNN不是必须组件
15.输出层激励函数--softMax
softmax直白来说就是将原来输出是3,1,-3通过softmax函数一作用,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标(!

信息熵公式的由来:
H(x)=−∑x∈Xp(x)logp(x)H(x)=−∑x∈Xp(x)logp(x)
信息论之父克劳德·香农,总结出了信息熵的三条性质:
- 单调性,即发生概率越高的事件,其所携带的信息熵越低。极端案例就是“太阳从东方升起”,因为为确定事件,所以不携带任何信息量。从信息论的角度,认为这句话没有消除任何不确定性。
- 非负性,即信息熵不能为负。这个很好理解,因为负的信息,即你得知了某个信息后,却增加了不确定性是不合逻辑的。
- 累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和。写成公式就是:
事件X=A,Y=B同时发生,两个事件相互独立p(X=A,Y=B)=p(X=A)⋅p(Y=B)p(X=A,Y=B)=p(X=A)·p(Y=B) ,那么信息熵H(A,B)=H(A)+H(B)H(A,B)=H(A)+H(B)
香农从数学上,严格证明了满足上述三个条件的随机变量不确定性度量函数具有唯一形式:其中的 为常数,我们将其归一化为 即得到了信息熵公式。
二次代价函数的缺陷
理想情况下,我们都希望和期待神经网络可以从错误中快速地学习,
但是在实践过程中并不是很理想。在使用函数C=(y−σ(z))22C=(y−σ(z))22表示的二次代价函数,假设a是神经元的输入,训练输入为x = 1, y = 0为目标输出。使用权重和偏置来表达这个,其中z=wx+bz=wx+b。使用链式法则来求权重和偏置的偏导数得:
∂C∂w=(σ(z)−y)σ′(z)x=σ(z)σ′(z)(1)(1)∂C∂w=(σ(z)−y)σ′(z)x=σ(z)σ′(z)
∂C∂b=(y−σ(z))σ′(z)=σ(z)σ′(z)(2)(2)∂C∂b=(y−σ(z))σ′(z)=σ(z)σ′(z)
其中已经将x = 1和y = 0代入。最后权重和偏置的偏导数只与σ′(z)函数相关,下面观察σ(z)函数,如下图:

从图可以观察的出,sigmoid函数的曲线趋于水平,也就是说在σ(z)的值等于1或0的时候σ′(z)的值会很小很小。从而也就导致了∂C∂w和∂C∂b会非常小。这也就是学习缓慢的原因所在。∂C∂w和∂C∂b会非常小。这也就是学习缓慢的原因所在。
交叉熵来源
假设在使用二次代价函数实践时发现学习速度下降,并且解释了其原因是由于σ′(z)项,那么将(1),(2)中σ′(z)去掉,消除其影响,那么对于训练样本x,其代价函数能够满足:
∂C∂wj=xj(σ(z)−y)(3)(3)∂C∂wj=xj(σ(z)−y)
∂C∂b=(σ(z)−y)(4)(4)∂C∂b=(σ(z)−y)
利用(3),(4),那么他们就能够以简单的方式呈现出一下特性:初始误差越大,神经元学习得越快。这样就可以解决学习速度下降的问题。再根据链式法则,推导:
∂C∂b=∂C∂σσ′(z)∂C∂b=∂C∂σσ′(z)
由σ'(z)=σ(z)(1−σ(z)),可以将上式转换成由σ′(z)=σ(z)(1−σ(z)),可以将上式转换成
∂C∂b=∂C∂σσ⋅(1−σ)∂C∂b=∂C∂σσ·(1−σ)
对比(4),有:
∂C∂σ=σ−yσ(1−σ)∂C∂σ=σ−yσ(1−σ)
对方程进行关于a的积分,可得:
C=−[ylnσ+(1−y)ln(1−σ)]+constantC=−[ylnσ+(1−y)ln(1−σ)]+constant
这是单个样本的代价函数,所以总代价函数为:
C=−1n∑x([ylnσ+(1−y)ln(1−σ)]+constant)C=−1n∑x([ylnσ+(1−y)ln(1−σ)]+constant)
交叉熵主观解释:
当前模型分类所产生的信息熵和样本真实的信息熵的差距
16.独热编码(One-Hot Encoding)
如:成绩这个特征有好,中,差变成one-hot就是
17.VC维
一种对空间划分能力的表示,网上有个例子:
假设咱只有两组数据(就是说咱们的坐标系里只有两个点)。这两组数据随机组合,一共有3种情况。
第一种情况:咱们有两个美人的数据
第二种情况:咱们有两个丑人的数据
第三种情况:咱们有一美一丑的数据
无论是哪一种情况,咱们都可以通过一条线把美人和丑人分开。这说明:线性的模型是完全可以shatter两组数据的。但假如说咱们有四组数据(坐标系里有四个点)。咱们就无法保证线性模型可以完全解释所有数据的可能性了。例如咱们的数据是(180cm, 50kg)=美,(10cm, 10kg)=美,(180cm, 10kg)= 丑还有(10cm, 50kg)=丑。对于这组数据,咱无论怎么画直线,都没有办法把美和丑分开在直线两侧。这说明:线性的模型是没有办法Shatter 4组数据的。假如说咱们有三组数据,还是总可以通过画线的方式把美/丑分开的。(大家仔细想一想)。所以,线性模型在这种二维数据的情况下的VC dimension 是3。(因为线性模型最多能Shatter3组数据)
18.梯度消失和梯度爆炸
设损失函数为:Loss=(y−f(xn))22,其中xn=f(xn−1),f(x)=σ(z),z=wx+b则对损失函数求导:∂Loss∂w1=(f(xn)−y)∂f(xn)∂w1由于其值主要和∂f(xn)∂w1有关,所以只关注以下:∂f(xn)∂w1=∂f(xn)∂zn.∂zn∂xn.∂f(xn−1)∂w1.∂zn−1∂xn−1…∂f(x1)∂z1.∂z1∂x1设损失函数为:Loss=(y−f(xn))22,其中xn=f(xn−1),f(x)=σ(z),z=wx+b则对损失函数求导:∂Loss∂w1=(f(xn)−y)∂f(xn)∂w1由于其值主要和∂f(xn)∂w1有关,所以只关注以下:∂f(xn)∂w1=∂f(xn)∂zn.∂zn∂xn.∂f(xn−1)∂w1.∂zn−1∂xn−1…∂f(x1)∂z1.∂z1∂x1
可见当其中有很多项∂z∂w很小时,便会出现∂Loss∂w1接近0,导致对w1梯度下降更新缓慢,即梯度下降;反之即梯度爆炸可见当其中有很多项∂z∂w很小时,便会出现∂Loss∂w1接近0,导致对w1梯度下降更新缓慢,即梯度下降;反之即梯度爆炸
解决办法:选取合适的激励函数
一般选取ReLU(修正线性单元,或者斜坡函数): f(x)=max(0,x) f(x)=max(0,x)

优点:
- 在第一象限中不会出现明显的梯度消失的问题,因为导数恒为1
- 由于导数为1,所以求解其导数要比Sigmoid函数的导数的时间代价要小些
- 由与x<0时为0,x>0时,为y=x,因而加入了非线性成分
19.批归一化(Batch Normalization)
它的好处:
最主要的减少梯度消失,加快收敛速度。
然后允许更大的学习率、不需要dropout、减少L2正则、减少扭转图像(其实都是第一个好处带来的)。
阅读后难理解的点在两个:
1、为什么通过每层的归一化,减少内部协变量转移(Internal Covariate Shift)就可以加速训练
2、归一化后又引入两个参数,而这两个参数的极端情况是又会将分布拉回原先状态。这是什么道理?
对于第一点,大牛们发现内部协变量转移(激活值的分布随着网络训练时参数的变化而变化)会导致激活值的分布趋于非线性饱和区,就是sigmod函数两头梯度几乎为0的趋于,这就会导致梯度消失。LeCun在文章Gradientbased learning applied to document recognition中提出过如果输入数据白化可加速网络训练。所以BN的提出者就想能否将每层的激活值都进行归一化,将它们拉到均值为0方差为1的区域,这样大部分数据都从梯度趋于0的区域变换至激活函数中间梯度较大的区域,从而解决了梯度消失的问题。这样梯度变大了,网络更新快,训练变快了。具体表现就是达到相同的正确率迭代次数更少,迭代相同次数时正确率会高(论文中使用MNIST做的实验)。
对于第二点,论文中提出进行归一化以后会改变原始数据的分布,这样的话网络每层的输出会不能得到很好的表达,因此引入两个参数进行调整,而且这两个参数是网络自己训练学习。读了两篇博客(有转载),觉得有一种解释比较易接受。就是在归一化后大部分数据被拉直激活函数中间的线性区域,但对于深层网络来说多层线性激活等价于一层没有意义,所以我们并不希望激活是线性的。所以我们需要在非线性和梯度较大这两点之间做个权衡,认为去设定可能不好,所以出现了两个训练学习的参数,让网络自己权衡利弊,自己去找准激活值的位置。
20.参数初始化
1.以0为均值μ,1为方差σμ,1为方差σ的分布来随机初始化
2.以0为均值μ,1为方差σμ,1为方差σ的分布生成后除以当前层的神经元个数的算数平方根来获得初始化(较多)
中心极限定理:任何独立随机变量和的极限分布为正态分布
21.正则化
正则化的目的角度:正则化是为了防止过拟合
直观的详解为什么要选择二次正则项。首先,需要从一般推特例,然后分析特例情况的互相优劣条件,可洞若观火。一般正则项是以下公式的形式
12∑Nn=1(wxi+b−yi)2+λ2∑Mj=1|wj|q 设C0=12∑Nn=1(wxi+b−yi)2C1=∑Mj=1|wj|q12∑n=1N(wxi+b−yi)2+λ2∑j=1M|wj|q 设C0=12∑n=1N(wxi+b−yi)2C1=∑j=1M|wj|q
在C1C1中M是模型的阶次(表现形式是数据的维度),比如M=2,就是一个平面(二维)内的点
若q=2就是二次正则项。高维度没有图像表征非常难以理解,那就使用二维作为特例来理解。这里令M=2,即 x={x1,x2}w={w1,w2},令q=0.5;q=1;q=2;q=4有:x={x1,x2}w={w1,w2},令q=0.5;q=1;q=2;q=4有:

横坐标是w1纵坐标是w2绿线是等高线的其中一条,换言之是一个俯视图,而z轴代表的是λ2∑Mj=1|wj|q的值横坐标是w1纵坐标是w2绿线是等高线的其中一条,换言之是一个俯视图,而z轴代表的是λ2∑j=1M|wj|q的值
可以由他们的三维图像想象(与绿线图一一对应)

q=2是一个圆非常好理解,考虑z=w21+w22z=w12+w22 就是抛物面,俯视图是一个圆。其他几项同理(必须强调俯视图和等高线的概念,z轴表示的是正则项的值)

蓝色的圆圈表示没有经过限制的损失函数在寻找最小值过程中, ww 的不断迭代(随最小二乘法,最终目的还是使损失函数最小)变化情况,表示的方法是等高线,z轴的值就是 E()E()
蓝线和红线交点 w∗w∗是最小值取到的点
可以直观的理解为(帮助理解正则化),我们的目标函数(误差函数)就是求蓝圈+红圈的和的最小值(回想等高线的概念并参照3式),而这个值通在很多情况下是两个曲面相交的地方
可以看到二次正则项的优势,处处可导,方便计算,限制模型的复杂度,w的值越多,越大,整个因子的值就越大,也就越不简洁,当加大λλ,便会迫使整个损失函数向着权值w减小的方向快速移动
不知道有没有人发现一次正则项的优势,w∗w∗ 的位置恰好是 w1=0w1=0的位置,意味着从另一种角度来说,使用一次正则项可以降低维度(降低模型复杂度,防止过拟合)二次正则项也做到了这一点,但是一次正则项做的更加彻底,更稀疏。不幸的是,正如这里的w1w1=0,在w1w1处不可微,所以一次正则项有拐点,不是处处可微,给计算带来了难度,很多厉害的论文都是巧妙的使用了一次正则项写出来的,效果十分强大
在一次模型搭建的过程中,通常不先加入正则化项,先只用带有C0C0项的损失函数来训练模型,当模型训练结束后,再尝试加入正则化项来改进.可以设置λλ为1,5,10,15,20…往下试,观测加入的λλ值是不是有效地提高了准确率
22.超参数和模型的不唯一
- 超参数: 是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据,如学习速率
- 模型不唯一: 最终的权重结果由偏差,因为训练过程中随机性几乎遍布整个训练过程,如模型的随机初始化,Mini Batch的选取
23.DropOut
假设我们要训练这样一个神经网络

输入是x输出是y,正常的流程是:我们首先把x通过网络前向传播然后后把误差反向传播以决定 如何更新参数让网络进行学习。使用dropout之后过程变成:
首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(下图中虚线为部分临时被删除的神经元)
然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后就按照随机梯度下降法更新(没有被删除的神经元)对应的参数(w,b)。
- 然后继续重复这一过程:
恢复被删掉的神经元(此时 被删除的神经元 保持原样,而没有被删除的神经元已经有所更新)
从隐藏神经元中随机选择一个一半大小的子集 临时删除掉(备份被删除神经元的参数)。
对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)
不断重复这一过程。

dropout 的过程好像很奇怪,为什么说它可以解决过拟合呢?(正则化)
取平均的作用: 先回到正常的模型(没有dropout),我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。(例如 3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果)。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络(随机删掉一半隐藏神经元导致网络结构已经不同),整个dropout过程就相当于 对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。(这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况)。 迫使网络去学习更加鲁棒的特征 (这些特征在其它的神经元的随机子集中也存在)。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的模式(鲁棒性)。(这个角度看 dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高)
24.循环神经网络(RNN)
隐马尔可夫(HMM)
还是用最经典的例子,掷骰子。假设我手里有三个不同的骰子。第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。

假设我们开始掷骰子,我们先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。然后我们掷骰子,得到一个数字,1,2,3,4,5,6,7,8中的一个。不停的重复上述过程,我们会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。例如我们可能得到这么一串数字(掷骰子10次):1 6 3 5 2 7 3 5 2 4这串数字叫做可见状态链。但是在隐马尔可夫模型中,我们不仅仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列。比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率(transition probability)。在我们这个例子里,D6的下一个状态是D4,D6,D8的概率都是1/3。D4,D8的下一个状态是D4,D6,D8的转换概率也都一样是1/3。这样设定是为了最开始容易说清楚,但是我们其实是可以随意设定转换概率的。比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是0.9,是D8的概率是0.1。这样就是一个新的HMM。同样的,尽管可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率(emission probability)。就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。产生2,3,4,5,6的概率也都是1/6。我们同样可以对输出概率进行其他定义。比如,我有一个被赌场动过手脚的六面骰子,掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。


其实对于HMM来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。但是应用HMM模型时候呢,往往是缺失了一部分信息的,有时候你知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;有时候你只是看到了很多次掷骰子的结果,剩下的什么都不知道。如果应用算法去估计这些缺失的信息,就成了一个很重要的问题。这些算法我会在下面详细讲。
从整个过程来看,HMM从给予训练样本序列到最后训练出来的两个矩阵,应该是经历了一个非监督学习过程.一旦这样的关系得到了,就可以进行一系列预测工作,例如在知道一次XiXi后判断Xi+1和Oi+1Xi+1和Oi+1的最大可能性,当然反推Xi−1和Oi−1Xi−1和Oi−1也没问题