13.信息正交性
找到不同信息之间的联系,加以利用
如何利用和组合信息,提高自己的决策水平
看似来源不同的信息,在消除不确定性时,作用有可能重叠。只有当信息是垂直的时候/(正交的时候),信息不会重叠。
在力学上,用力要在一个方向效果才好,在使用信息熵,要选用彼此垂直的正交信息。
eg one:
语音识别——N选1的问题
要消除不确定性,用到最有效的信息两类:

任何一种信息都可以找到对应到某个空间中的一个矢量,在空间中画出来,就会发现他们之间的夹角是90°,即这两种信息是正交的。
如何找到正交的信息?(3个原则 2个做法)
(1)不同的信息要来自不同的信息源
善于选用正交的信息进行交叉验证
(2)避免反复使用相互嵌套或者相互包含的信息
即使它们来自不同的来源,因为那些信息即便不完全相同,但是可能一个覆盖了另一个,或者相似性太高
(3)看问题要可以改变一下观察的角度,从几个不同的角度看

注:不断叠加:选出一个最优的,然后依次筛选剩下的,以最优的为参考,进行叠加搭配
不断删除:逆向过程,从最小的开始为替补,依次类推,重复选
14 互信息
1.衡量两条信息之间相关性的工具,给出了一种量化度量各种不同信息相关性的方法。
其实世界上大多数联系都是相关联系,而非因果联系。相关联系可以强,可以弱,但弱相关其实没有什么意义,我们需要寻找和利用的是强相关性。要知道相关程度的大小,就需要有一个定量衡量它的指标——互信息。
裙摆指数——“牛市与裸露的大腿”
世界上很多事情彼此相关,如果他们之间有确定的因果关系,那样的信息就是等价的。
但是世界上大部分相关的信息未必有因果关系,他们之间只是一种动态的相互关联的关系。
切记:不要把因果关系搞反了(即使A——>B,但B未必可以推出确定A)
2.数据挖掘领域中有个模块叫做:“关联规则”——“购物篮分析”
15条件熵和信息增益
1.信息增益:information gain IG;
IG越大,说明消除的不确定性越大,X和Y越具有相关性。


通常,人们总是率先发现和所要解决问题互信息最大的信息,即增益最大的信息;所以,越往后发现的信息,带来的增益越小。
注:如果有幸找到一个大家遗漏的信号,那么还要确定两件事,再确定是否有用?

2.
一条信息的价值,取决于这条信息对未知系统所带来的信息增益。
两条信息,先出现的,价值更大,第二条价值就小。
但,如果两条信息相互正交,那第二条信息依然像过去那样有价值。
3.标新立异才有可能提供信息增量。
对于每个人,第一个发飙意见,以及能够发表与众不同的意见,对提高自己的影响力至关重要。
16置信度
置信度(confidence level)——可衡量一个信息到底是否可靠
T-测试(T检验)方法:在某种看似有偏差的现象时,有多大的可能性可以判断这种偏差是因为随机性造成的,而非真正存在偏差。
如何提高置信度:——增加所统计的样本的数量
大量重复的事情发生背后常常有它固有的规律。但是很多事情并不会重复或者完全重复,他们的发生就有很大的偶然性。几乎每一件历史上的事件,社会学上和经济学上的事情都是如此,甚至很多医学上的奇迹也一样。
对于能够重复的事情,要被检验足够多次之后,置信度才高。对于难以重复检验的事情,要通过其他一些方式验证。
eg:
复盘归纳:关键词——错误
①真正的错误:执行了错误进程
②遗忘性错误:忘记了部分进程
③粗心错误:错误执行了正确进程
发生层次:①技术层面 ②规则层面 ③知识层面
17 交叉熵
代价函数——库尔贝勒交叉熵(K-L divergence KL散度):它可以研究在信息误判时的损失,不至于满盘皆输
围绕着量化度量错误预测所要付出的成本进行的
eg:
X——随机事件
P(X)——发生的各种可能性的概率分布;预测概率
Q(X)——结果,真实概率
代价函数KL:
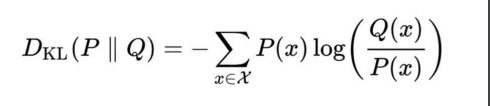
当你预测的概率分布和真实情况完全一致时,损失是0 ;(信息的度量是个对数函数,差出1.实际上就差了2倍出去)
结论:
(1)如果你的猜测和真实情况完全一致,你不损失任何东西,但是只要猜测和真实情况不一致,就会或多或少有损失
(2)你的猜测和真实情况相差越大,损失越大
(3)自大的人非常容易遗漏很多原本应该考虑的事情
(4)过分防范各种情况,患得患失,一样会有损失。
(5)在信息论中,任何硬性的决定(hard decision)都要损失信息
比如强制性的将一些可能设置为0,或者呼吁大家all in一样,这样造成的损失可能是巨大的,而且是无法补救的
未虑胜,先虑败
Always have plan B
在走到最后一步之前,最好多保留一些可能性,哪怕将那些可能性的权重设得非常低,而不要很早就硬性的作决定,因为在硬性决定后失去的信息是永远补不回来的。
古德—图灵估计(Good-Turing Estimate):原则是从所有预见到的事情中拿出很少一些资源,分配给没有预见到的事情。
18 复盘
围绕“如何识别误导人的信息”
(1)刻意要引起你注意的人,常常会用耸人听闻的信息打动你。对于那些看似颠覆了你长期认知的所谓的“新知”,要格外小心。

(2)没有出处,或者只有一个无法验证的出处,几乎所有的和阴谋论相关的信息都有这个特点
信息溯源——同行专业评论
(3)缺乏上下文
第一模块总结


(1)辨识度和冗余度的区别:
这是两个不同的概念。辨识度高必然要以提高冗余度为代价,但是反过来,冗余度高了,辨识度未必高。
(2)压缩和过滤:
压缩:通过优化的信息编码,用更小的编码长度(或者存储空间)表达同样多的信息
过滤:根据自己特定的需求,保留自己认为有用的信息,滤除自己用不到的
无损的压缩是没有过滤的,因为所有的信息都保留下来了。有损压缩是,肯定是过滤掉了一些信息,这个过滤的原则是让信息量尽可能地不减少。但是一般性的信息过滤,原则就是保留自己要用到的,而非信息量。
