
针对延迟渲染,官方给出了一个Demo,分别实现了传统的双Pass延迟渲染和利用Metal的特性实现的单一Pass延迟渲染。单Pass延迟渲染主要依靠iOS和tvOS平台的Tile based特性来实现。这篇文章主要根据官方的延迟渲染Demo来分析两种延迟渲染的原理区别,扩展Programmable blending特性实现延迟渲染和ImageBlock实现延迟渲染进行优化的原理,挖掘总结用到的Metal引擎特性和相关知识点。
官方Metal Demo列表地址:https://developer.apple.com/metal/sample-code/
延迟渲染Demo地址:https://developer.apple.com/documentation/metal/deferred_lighting?language=objc
文章目录
一、 关键词
- Xcode抓帧调试;
- TBDR;
- Programmable blending;
- ImageBlock(Implicit,Explicit);
- Tile Memory;
- Multiple Raster Order Groups
二、延迟渲染原理回顾
延迟渲染相比于前向渲染可以更加高效的渲染大量的光源场景。前向渲染中,对于场景中通过深度测试的每个物体,要依次针对每个光源进行光照计算,当场景复杂、光源数量增多,计算量会急剧增加,效率低下;
而在延迟渲染中,光照计算推迟到第二步,对于每个光源场景在屏幕空间只进行一次光照计算,光源的增加对计算量影响线性的。
延迟渲染的实现方式目前依托不同的硬件结构有两种,像macOS等PC平台由于GPU是IMR(immediate mode rendering)架构,延迟渲染的实现至少需要两个Pass。而iOS等移动平台的GPU支持TBDR架构,利用tile memory可以实现在一个Pass中进行延迟渲染,减少CPU和GPU之间的数据带宽,提高了渲染效率。
2.1 传统延迟渲染
传统的延迟渲染一般分成两个步骤(2个Pass):
- 第一个Pass:渲染G-Buffer。
第一个Pass正常渲染一遍场景,经过顶点着色器模型坐标变换,和片段着色器,计算色彩(difusse)、法线(normal)、高光(specular)、深度(depth)、阴影(shadow)等,并把结果通过MRT缓存到内存中备用。
- 第二个Pass:延迟光照计算以及颜色合成。
第一个Pass缓存的G-buffer贴图会从CPU中传进第二个Pass进行进一步的绘制,第二个Pass中会利用G-buffer贴图中的数据重构每个片段的位置信息进行每个光源的光照计算。最后结果会叠加光照的计算结果和阴影等输出最终的像素颜色。

2.2 单Pass延迟渲染(iOS、tvOS GPUs)
基于TBDR的GPU架构,我们可以实现将渲染出的G-buffer保存在tile memory中,不需要再写入到system memory中,就避免了将G-buffer从GPU写入到CPU然后第二个Pass GPU又从CPU读取G-buffer的步骤,降低了CPU和GPU之间的带宽消耗。
Metal中我们控制GPU是否将tile memory中的贴图数据写入到CPU的system memory的方式是配置我们的renderCommandEncoder的storeAction和texture贴图的storageMode。loadAction是用来配置渲染开始时是否清空我们的RT等动作。storeAction是用来配置渲染结束是否将render pass的结果保存到attachment中等动作。
几种常用storgeMode的含义:
- MTLStorageModeShared:表示资源保存在system memory,且CPU和GPU都可以访问;
- MTLStorageModePrivate:表示资源只有GPU可以访问;
- MTLStorageModeMemoryless:表示资源只有GPU可以访问,且生命周期只是临时存在于一个render pass期间;
- MTLStorageModeManaged:表示CPU和GPU分别会维护一份资源的拷贝,并且资源具有“可见性”,即无论哪边对资源进行了更改,CPU和GPU都可见都会进行更新同步;
如果我们将storeAction设置为MTLStoreActionStore表示RT的结果会从GPU的tile memory写入到CPU的system memory,即在system memory中保存RT的备份。如果渲染后期还需要用到system memory中备份的RT,就需要从system memory中读取备份的RT到GPU的贴图缓存中。所以传统的双Pass延迟渲染中需要在第一个Pass和第二个Pass期间将G-buffer保存到system memory中。
_renderPassDescriptor.colorAttachments[AAPLRenderTargetAlbedo].storeAction = MTLStoreActionStore;
GBufferTextureDesc.storageMode = MTLStorageModePrivate;
_renderPassDescriptor.colorAttachments[AAPLRenderTargetAlbedo].storeAction = MTLStoreActionDontCare;
GBufferTextureDesc.storageMode = MTLStorageModeMemoryless;
注意:
- 这里基于TBDR架构允许GPU的FS片段着色器访问render targets(color[id])进行混合计算的特性就是programmable blending,当然基于TBDR下FS也可以通过ImageBlocks特性访问同样的数据实现同样的功能。programmable blending和Metal2的新特性ImageBlocks都可以实现一些类似的功能,但原理不同,可以重点学习比较各自的特点。
- 在Tile based shading中,G-buffer是被分成tile-size大小来保存的,因此可以将所有物体一次性渲染到tile-sized G-buffer中留在On-Chip memory。要注意并不是仅仅G-buffer不保存到system memory那么简单,实现的前提是Tile based,否则On-Chip memory是无法装得下完整的屏幕大小的G-buffer的。Tile based是由于移动平台计算性能有限应运而生的GPU架构。
2.3 TBDR架构原理
上面提到TBDR架构下可以将RT保存在tile memory降低GPU和CPU之间的带宽,但是并没有讲清楚TBDR实现的原理和底层流程。这里强调一下TBDR架构的原理和Metal中启用TBDR架构的方法。
TBDR原理
IMR架构立即渲染的意思是每次提交一个模型物体就进行单独渲染,最后把所有物体混合。而TBDR架构是考虑到移动平台带宽压力导致手机发热而设计的,与IMR架构不同的是:TBDR是等待场景所有物体都提交之后再统一进行处理,然后将屏幕空间内的所有物体按照设置的tile size大小将屏幕分割成小块单独进行处理,这样所有在同一块tile上的几何图元会同时进行渲染,不在tile内的片段会在光栅化之前被剔除掉。这样一个tile可以在GPU方面快速进行渲染,最后将结果在CPU方面再拼成完整的一张屏幕图像。
举个简单例子,假设场景中有100个物体,TBDR将屏幕分成3x3的9个tile片。IMR架构需要来回提交100次给GPU进行渲染,TBDR则只需要9次。将屏幕分成小块tile的原因是保证tile memory够用,如果全屏规模也就是只有1个大tile全部提交给GPU渲染的话tile memory是不够用的。
Metal使用Tile-based架构
事实上Metal并没有提供显式的方法去启用Tile Based,而是根据某些场景的代码实现和设置提示GPU启用tile memory的。例如有两种启用的情况如下:
- 一个是上面我们提到的Load and Store Action和storgeMode的设置,当我们设置RT不保存到system memory并且只给GPU访问的时候,GPU就会启用Tile Based将RT切成tile size大小保存在tile memory进行快速处理。这就是单pass延迟渲染启用Tile base的方法;
- 另外一种情况就是Tile Based Shading,这种情况其实是有显式的启用方法的,会有一个专门的描述RenderPipelineState的MTLTileRenderPipelineDescriptor,可以指定采样规模和tileFunction等,例如Tile Based Forward+ 中culling阶段使用Tile Shading的描述方式:
MTLTileRenderPipelineDescriptor *tileRenderPipelineDescriptor = [MTLTileRenderPipelineDescriptor new];
tileRenderPipelineDescriptor.label = @"Light Culling";
tileRenderPipelineDescriptor.rasterSampleCount = AAPLNumSamples;
tileRenderPipelineDescriptor.colorAttachments[0].pixelFormat = MTLPixelFormatBGRA8Unorm;
tileRenderPipelineDescriptor.colorAttachments[1].pixelFormat = MTLPixelFormatR32Float;
tileRenderPipelineDescriptor.threadgroupSizeMatchesTileSize = YES;
tileRenderPipelineDescriptor.tileFunction = lightCullingKernel;
三、Metal2新特性:光栅顺序组(ROG,Raster Order Groups)
3.1 Raster Order Groups的作用
ROG是干什么的呢?官方解释:准确的控制并行的fragment shader线程访问同一个像素的顺序。
通俗点说,就是我们在渲染场景物体的时候,有些前后重叠遮挡的物体身上的fragment shader可能会同时访问同一个坐标的那个像素数据,造成竞争,导致结果错误。而ROG就是用来同步这个像素的访问次序,防止竞争的发生。
这样解释可能还是不够直观,这里来看官方给出的一个例子。
假设有下面这种情况,镜头场景中有两个重叠的三角形,开发者代码中绘制的时候对于这种透明物体会按照从后往前的顺序绘制,也就是先调用后面蓝色三角形的draw call,然后再调用前面绿色三角形的draw call,Metal也会按照我们代码的顺序去执行draw call指令,这样看似乎这两次draw call是依次串行执行,但实际上并不是这样,GPU上的运算过程是高度并行的,虽然CPU发出的指令是先绘制蓝三角形,但在GPU上Metal并不能保证蓝三角形的fragment shader会比绿三角形的先执行,Metal只能保证在blend混合的时候是按照draw call的顺序执行的,如下图所示:
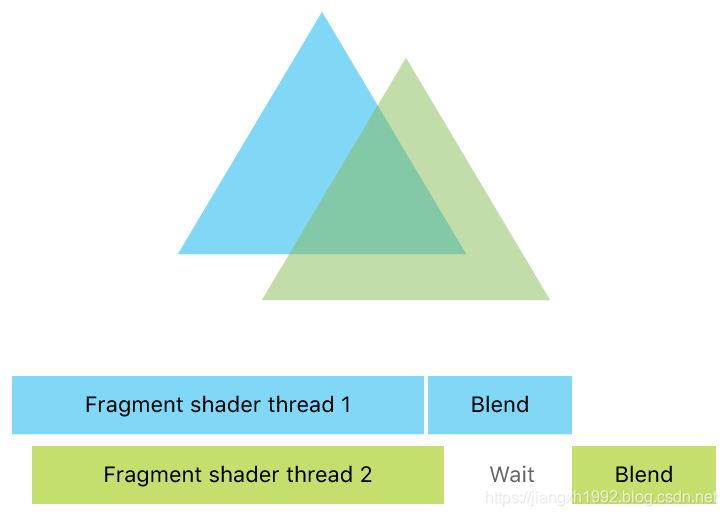
那么问题来了,blend虽然保证串行不重叠了,但是blend之前的读写操作并无法保证串行,蓝三角形fragment shader将blend后的结果写入像素的同时,可能绿三角的fragment shader正在读取该像素的颜色,造成了竞争,如下图所示:
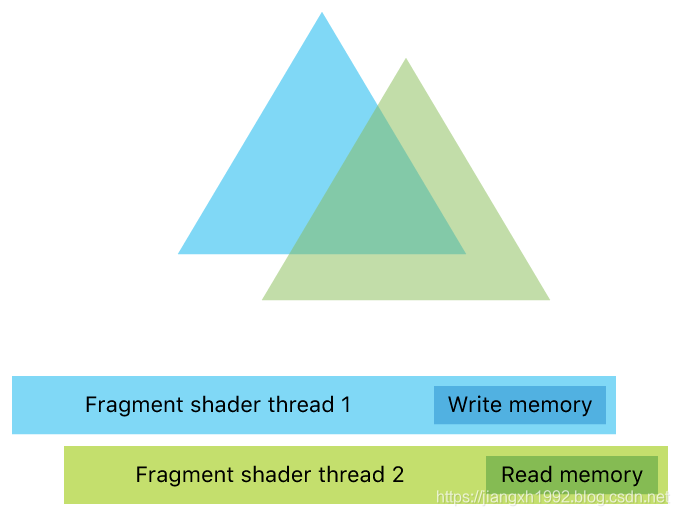
ROG就是解决上面这种数据读写冲突问题的。
3.2 Raster Order Groups解决读写冲突
ROG解决读写冲突的方式为线程同步,即同步同一个像素或者采样点(如果是per-sample着色模式)对应的thread线程。实现上,开发者只要用ROG attribute属性标记数据内存,这样多个线程访问同一个像素数据的时候就会等待当前线程写入数据结束再访问。下图展示了ROG同步两个线程,使得线程2等待线程1写入数据结束后才开始继续读取数据:
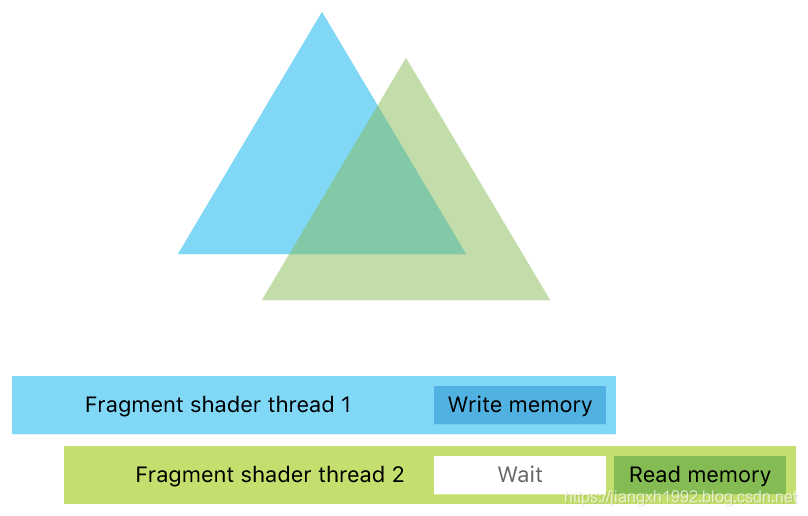
3.3 Metal2 A11新特性:Multiple Raster Order Groups
Metal2 A11开始对Raster Order Groups进行了扩展,除了可以实现同步单通道imageblock和threadgroup memory数据,还开始支持多个ROG的定义使用,开发者可以更加细粒度的控制线程的同步,进一步减少线程的等待时间。
Multiple Raster Order Groups优化渲染的典型例子就是本文主题中提到的:单Pass延迟渲染。
前面说到传统的双Pass延迟渲染,第一个Pass渲出G-buffer保存到system memory,然后第二个Pass读取system memory中的G-buffer进行延迟光照计算。然后A11的tile memory的存在得以实现Tile based shading,使得G-buffer被分成tile-sized大小从而继续保存在GPU imageblock内存中,直接继续进行延迟光照计算,在一个Pass中完成了延迟渲染,降低了数据带宽。
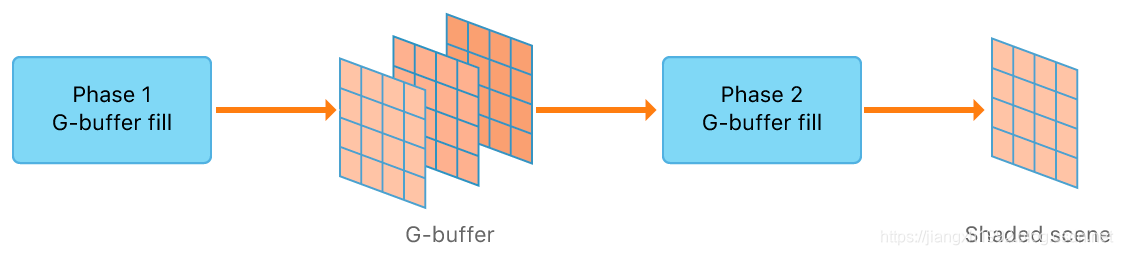
我们知道延迟渲染主要解决多光源场景渲染的效率问题,一般的GPU在进行多线程、多光源延迟光照计算时的过程是像下面这样的:
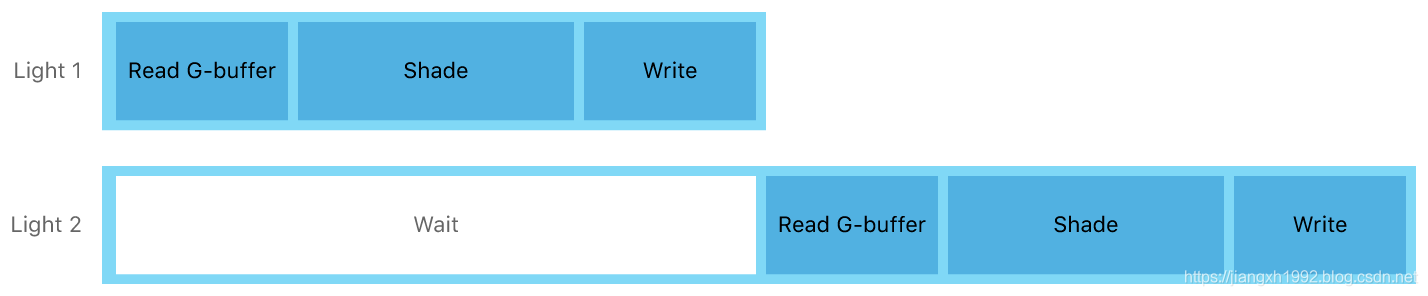
这种情况第二个光源想要读取G-buffer对当前像素进行光照计算时,必须等待第一个光源计算并写入结束才能开始读取G-buffer(光照计算结果和G-buffer放在一起)。
现在我们可以通过定义多个Raster Order Groups来优化这个问题。开发者只要将G-buffer中的贴图资源和光照计算结果分开放到不同的Raster Order Groups即可,例如将Lighting光照计算结果放到第一组,将G-buffer的albedo,normal,depth等放到第二组,这样A11就可以将这两组分开,第二个光源就随时可以读取第二组的G-buffer数据进行光照计算,只在写入第一组的Lighting光照计算结果时进行同步等待即可。优化后流程如下:
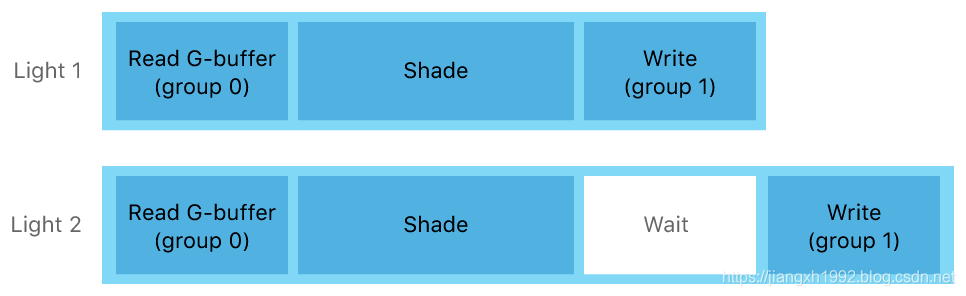
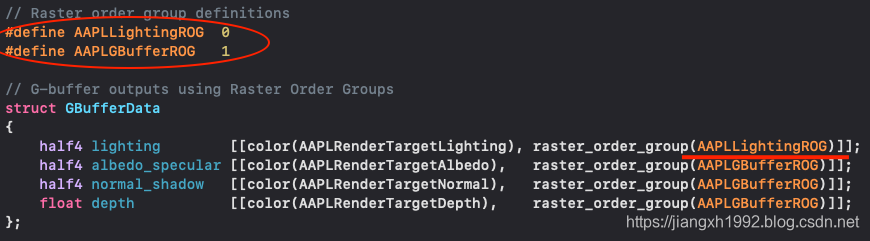
四、Metal2新特性:图像数据块(ImageBlocks)
4.1 ImageBlocks须知
-
ImageBlocks特性是从Metal2开始在ios上开始支持的,不支持macOS;
-
ImageBlocks仅可用于A11上的***fragment函数和kernel函数(被fragment function和kernel function共享)***,ImageBlocks整合到了片段着色阶段和tile shading阶段,也可用于kernel函数计算。fragment函数中只能访问当前fragment片段位置对应的ImageBlocks像素数据,而kernel函数中每个thread都可以访问到所在的threadgroup对应的整个ImageBlocks图像数据块;
-
实际上ImageBlocks在iOS设备上一直是存在的,只是到了Metal2在A11才向开发者开放,开发者可以灵活自定义ImageBlocks的数据结构,可以通过(x,y)坐标和sample index来定位访问ImageBlocks的数据;
4.2 ImageBlocks结构
ImageBlocks是一个n * m的二维数据结构,有宽度和高度,还有 像素深度 。ImageBlocks中的每个像素都可包含多个成员,每个成员保存在各自的切片当中。如下图,表示该ImageBlocks有三个切片,分别是albedo,specular和normal,也就是每个都像素包含这三个成员。
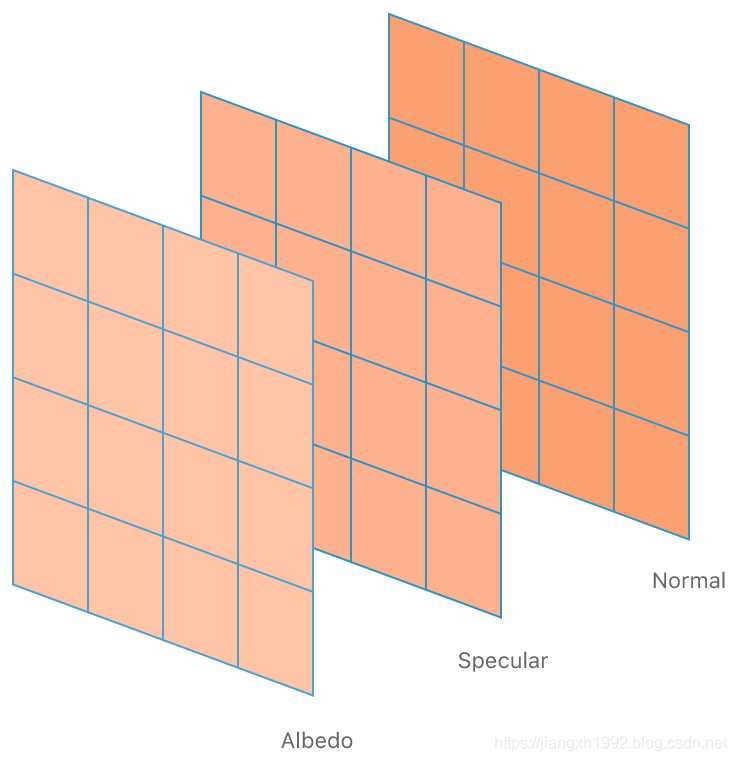
4.3 隐式(implicit)ImageBlocks和显式(explicit)ImageBlocks
隐式ImageBlocks其实就是默认从tile memory接收数据的ImageBlocks,是在使用attachments渲染的时候通过loadAction和storeAction定义绑定的,隐式的ImageBlocks的数据组织跟color attachments的attribute属性一致(实质是Metal自动创建了一个Implicit ImageBlocks来匹配color attachment中的行为),每个成员每个attribute对应一个[[color(id)]]。
显式ImageBlocks则是开发者可以在shader中自定义ImageBlocks的layout结构。关于ImageBlocks在fragment函数和kernel函数中的具体用法另外写文章总结,此处暂时省略。
官方Demo中的Forward Plus Lighting with Tile Shading源码中在culling lights的kernel函数中简单用到了implicit imageblock来访问depth pre pass中的depth数据:
typedef struct
{
half4 lighting [[color(0)]];
float depth [[color(1)]];
} ColorData;
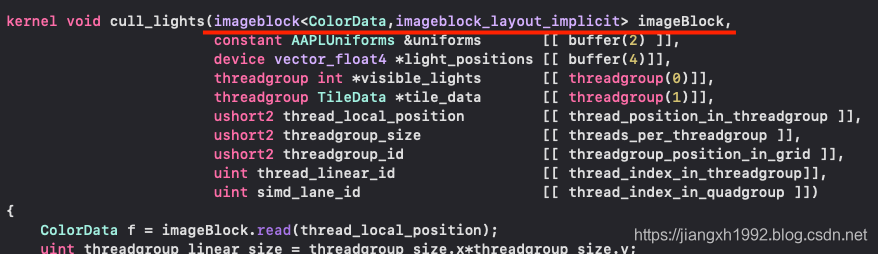
官方Demo中的OrderIndependentTransparencyWithImageblocks源码中则充分利用了kernel函数中的explicit imageblock:
template <int NUM_LAYERS>
struct OITData
{
static constexpr constant short s_numLayers = NUM_LAYERS;
rgba8storage colors [[raster_order_group(0)]] [NUM_LAYERS];
half depths [[raster_order_group(0)]] [NUM_LAYERS];
r8storage transmittances [[raster_order_group(0)]] [NUM_LAYERS];
};
// The imageblock structure
template <int NUM_LAYERS>
struct OITImageblock
{
OITData<NUM_LAYERS> oitData;
};

PLUS:官方单Pass延迟渲染的Demo是利用programmable blending在FS中直接访问GBuffer实现的,实际上也同样可以通过ImageBlocks来在FS中访问GBuffer。
五、Xcode基本抓帧调试
Xcode编辑器自身提供了强大的抓帧工具和可视化的渲染流程展示,详细数据分析,开发者可以很方便的分析数据和控制渲染流程。
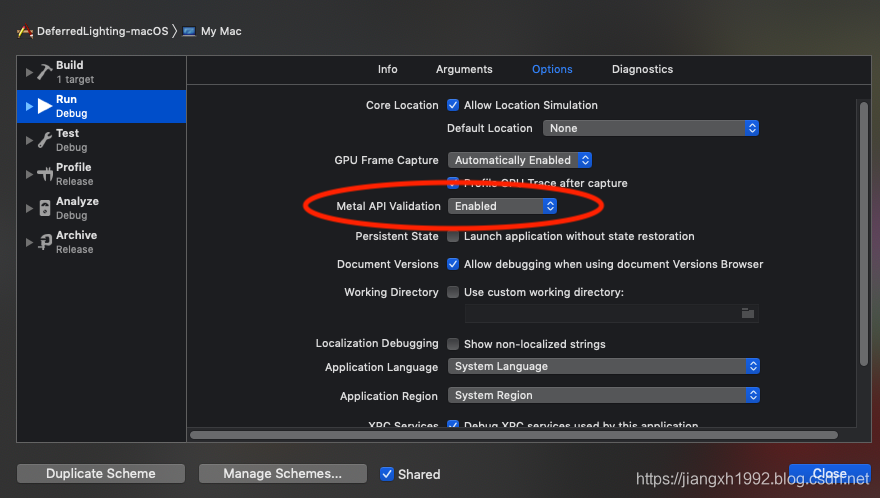
程序运行起来前需要先在编辑器:Product -> Scheme -> Edit Scheme -> Run -> Options 下,设置Metal API Validation为Enabled获取详细的调试数据:
左侧导航栏展示了一帧中所有的渲染指令执行顺序和层次关系,点击对应指令右侧会展示可视化的渲染步骤:
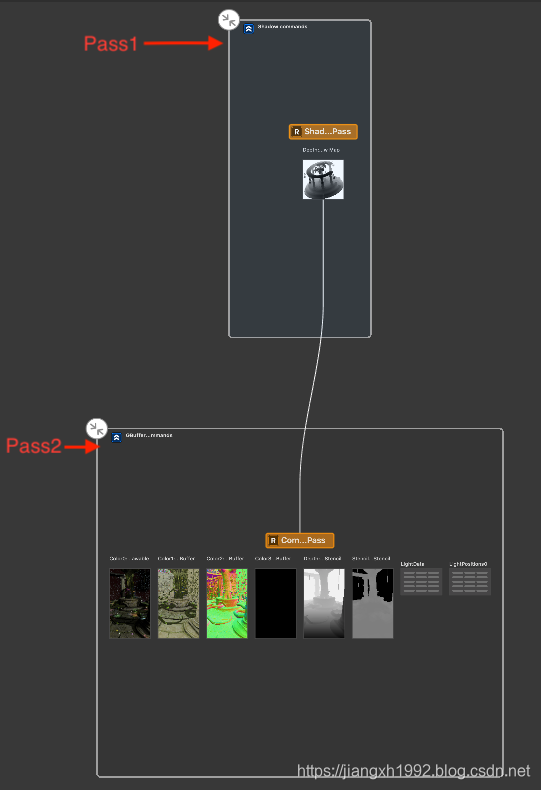
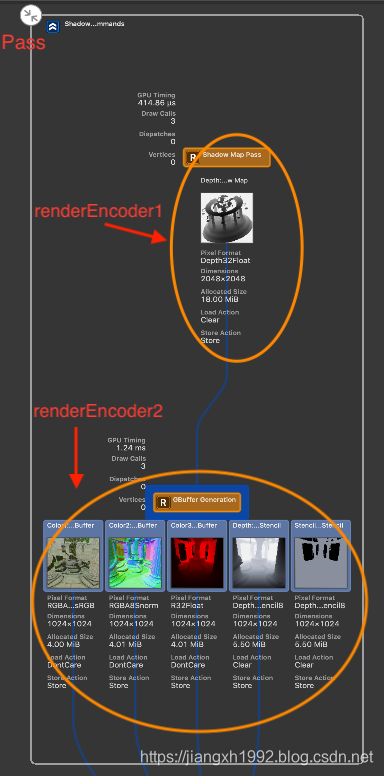
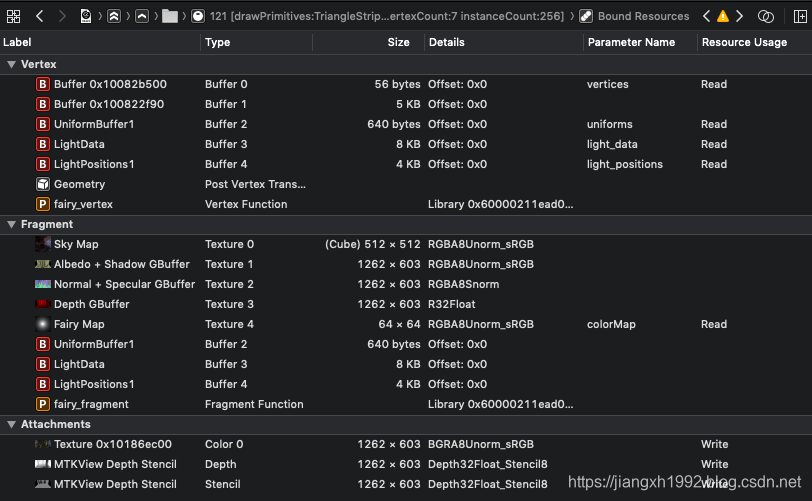
右边窗口主要展示可视化的渲染流程和渲染过程中的各种资源数据等,其中渲染流程图中每个封闭的框表示一个Pass,每次[commandBuffer commit];表示封闭框结束。封闭框内部每一组数据对应一个renderEncoder,每次[renderEncoder endEncoding];对应框内一行的资源结束。每一组资源之间的连线表示数据的后续使用关系。
六、延迟渲染Demo源码分析
有了以上的知识储备现在再来分析官方的延迟渲染Demo就没有理论障碍了。
Demo中实现了两种延迟渲染,即单Pass和传统双Pass延迟渲染:
6.1 延迟渲染的一帧
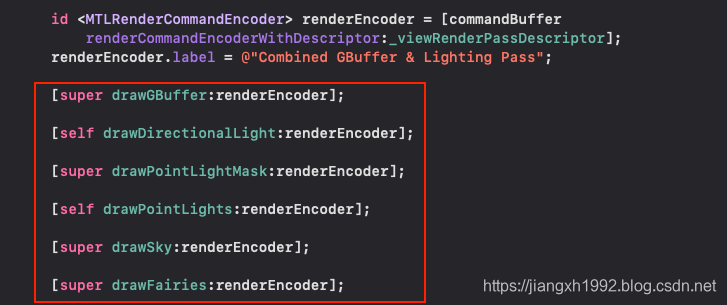
Demo中基于延迟渲染场景实现了下面的步骤和效果:
- 阴影贴图(Shadow map);
- 渲染G-buffer;
- 平行光计算(Directional light);
- 光照掩盖(Light mask);
- 点光源计算(Point lights);
- 天空盒渲染(Skybox);
- 粒子绘制(Fairy lights);
在iOS和tvOS上由于TBDR架构的支持得以在一个Pass中完成延迟渲染,因此可以依次连续完成上面的步骤:
而macOS的IMR GPU架构只能实现双Pass延迟渲染,因此要先在一个Pass中渲染G-buffer:
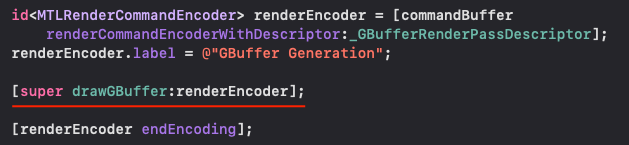
等commandBuffer commit之后,然后再进行后面的延迟光照计算等步骤:
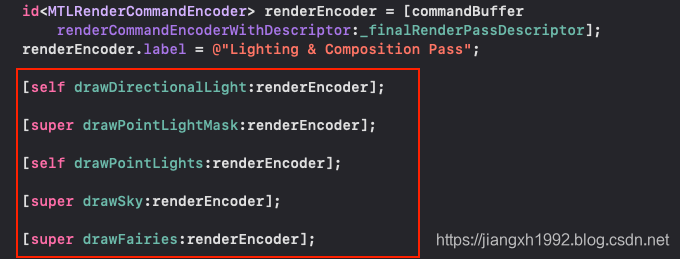
6.2 抓帧看延迟渲染的流程
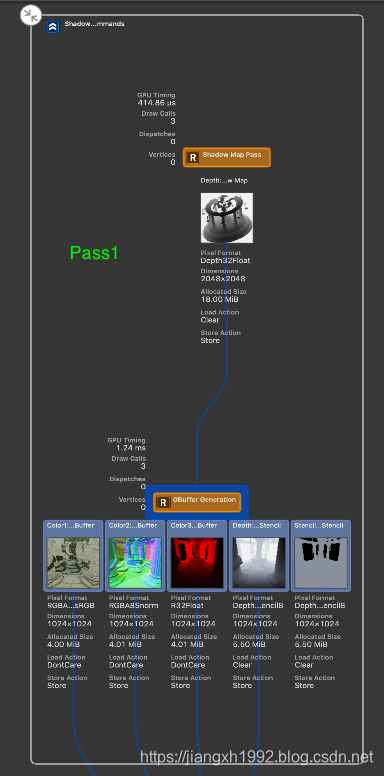
首先在macOS上运行Demo抓帧,分析传统的两个Pass的延迟渲染。通过指令列表和可视化流程图可以看到第一个Pass(Shadow & GBuffer)绘制了ShadowMap,然后渲染了G-buffer;第二个Pass(Lighting)中则进行了光照计算,以及绘制天空盒和粒子等。
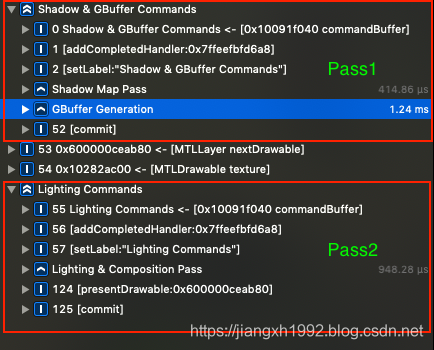

然后在iPhone真机上运行Demo,抓帧后可以看到整个过程也是有两个Pass,只不过第一个Pass(Shadow)只是用来绘制ShadowMap,G-buffer的渲染和光照计算都集中在了第二个Pass(G-buffer & Lighting)中:
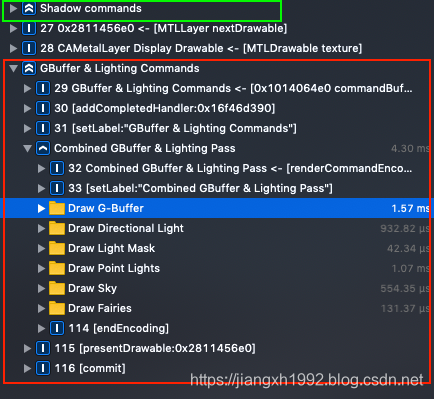

6.3 G-buffer
Demo将G-buffer放在了三张RT上:
- albedo_specular_GBuffer:这张用来保存albedo颜色数据和specular高光数据,albedo占用xyz三个分量,specular占用w分量;
normal_shadow_GBuffer:这张保存normal发现数据和shadow阴影数据,normal占用xyz分量,shadow占用w分量;
depth_GBuffer:深度缓冲只保存深度数据,保存的事eye space的深度值。

6.4 平行光和阴影计算
6.5 Cull the Light Volumes
6.6 绘制天空盒和粒子
七、总结
这篇文章以延迟渲染为背景,主要总结以下几个重要话题:
- 延迟渲染的原理,以及基于Metal新特性和移动平台TBDR的GPU架构实现单Pass延迟渲染的原理,背后降低数据带宽的原理等;
- 光栅顺序组的原理,以及新特性下优化TBDR性能的方法和原理;
- ImageBlock原理简介,应用场景和意义,Implicit ImageBlock和Explicit Block的区别;
- Xcode中Metal引擎渲染的基本调试方法;
- 官方延迟渲染Demo源码的结构的分析,知识点的应用。
参考文章
- https://developer.apple.com/documentation/metal/deferred_lighting?language=objc
- https://developer.apple.com/documentation/metal/gpu_features/understanding_gpu_family_4/about_raster_order_groups?language=objc
- https://developer.apple.com/documentation/metal/gpu_features/understanding_gpu_family_4/about_imageblocks?language=objc
