承接超分辨率重构之SRCNN整理总结(三)的超分重建结果指标之后,本篇解读了基于神经网络的超分重建最简单的网络结构SRCNN,并随后follow了一些dalao的tensorflow版本的网络结构经代码改些许动用GPU训练模型且测试成功。
SRCNN(Super-Resolution Convolutional Neural Network)
论文下载:(Learning a Deep Convolutional Network for Image Super-Resolution, ECCV2014)
code: http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html(matlab)
- 【1】介绍
传统的SR方法都是学习compact dictionary or manifold space to relate low/high-resolution patches。
SRCNN是深度学习在图像超分辨率重建上的开山之作,通过采用卷积神经网络来实现低分辨率到高分辨率图像之间端到端的映射。
- 【2】网络的结构如图

- 【3】基本原理:
对于一个低分辨率的图像,首先采用双三次插值(bicubic)将低分辨率图像放大成目标尺寸,接着通过三层卷积网络拟合非线性映射,最后输出高分辨率图像结果。在论文中,作者将三层卷积的结构解释成三个步骤:
- 图像块的提取和特征表示
- 特征非线性映射
- 图像最终的重建
三个卷积层使用的卷积核的大小分为为9x9,,1x1和5x5,前两个的输出特征个数分别为64和32。用Timofte数据集(包含91幅图像)和ImageNet大数据集进行训练。使用均方误差(Mean Squared Error, MSE)作为损失函数,以便获得较高的PSNR。
- 【4】SRCNN的流程
1.图像块提取(Patch extraction and representation)
先将低分辨率图像使用双三次(实际上,bicubic也是一个卷积的操作,可以通过卷积神经网络实现)插值放大至目标尺寸(如放大至2倍、3倍、4倍,属于预处理阶段),此时仍然称放大至目标尺寸后的图像为低分辨率图像(Low-resolution image),即图中的输入(input)。从低分辨率输入图像中提取图像块,组成高维的特征图。
其中,和
为超参。激活函数采样ReLu
2.非线性映射(Non-linear mapping)
第一层卷积:卷积核尺寸9×9(f1×f1),卷积核数目64(n1),输出64张特征图;
第二层卷积:卷积核尺寸1×1(f2×f2),卷积核数目32(n2),输出32张特征图;
这个过程实现两个高维特征向量的非线性映射;
W2为n1*1*1*n2。采用了1*1卷积,目的应该是压缩feature map的深度,同时也起到非线性映射的作用。
3.重建(Reconstruction)
第三层卷积:卷积核尺寸5×5(f3×f3),卷积核数目1(n3),输出1张特征图即为最终重建高分辨率图像;
- 【5】模型参数结构图如图

- 【6】损失函数Loss Function(Mean Squared Error (MSE))
即n张重构的结果与真实图像的均方误差MSE,估计超参。
为重构的结果,
为ground truth。Using MSE as the loss function favors a high PSNR.
- 【7】原论文结果比较图

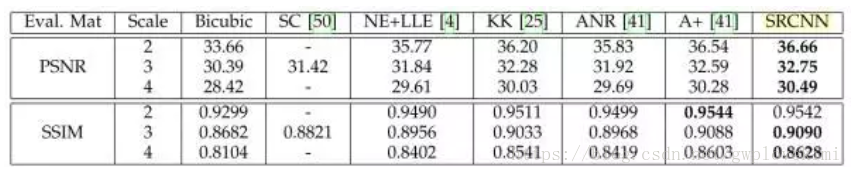
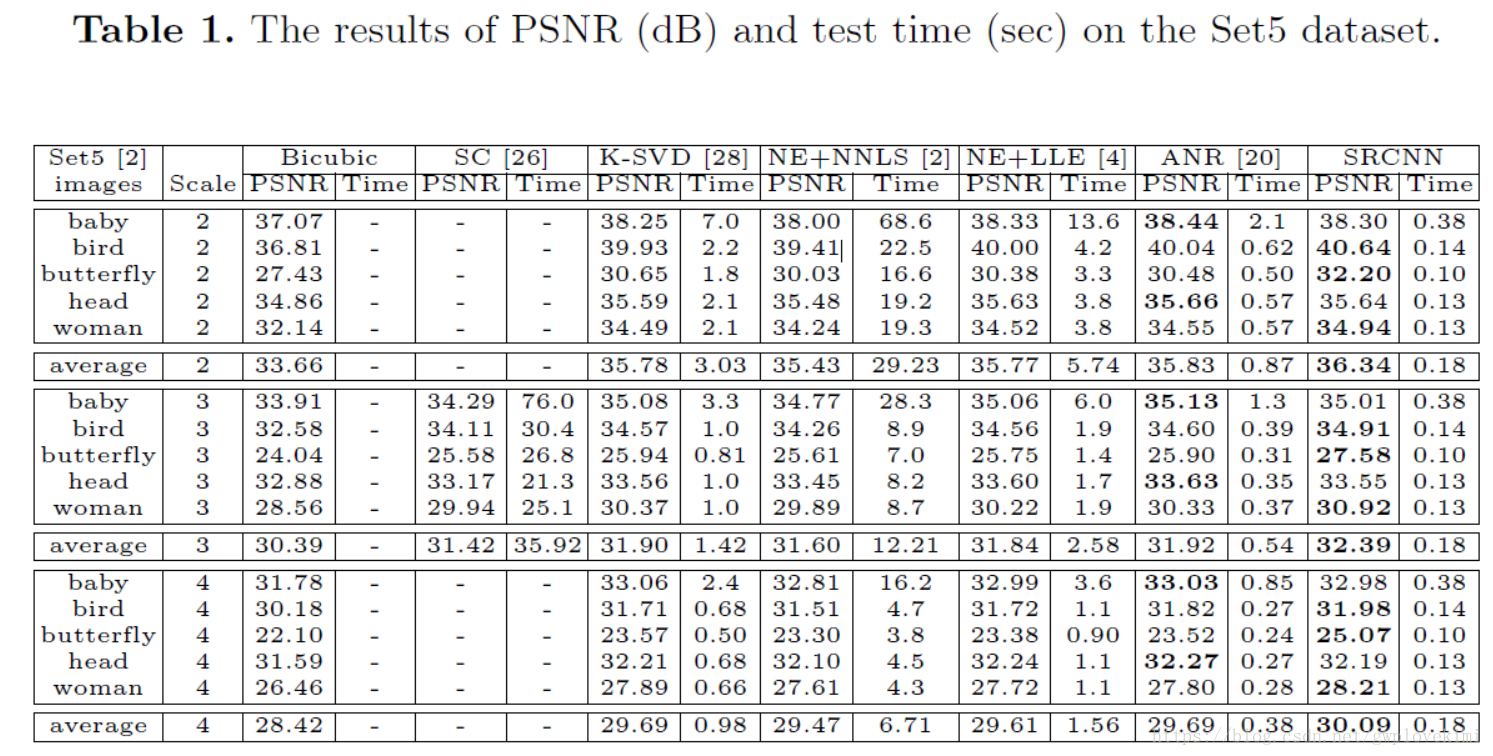
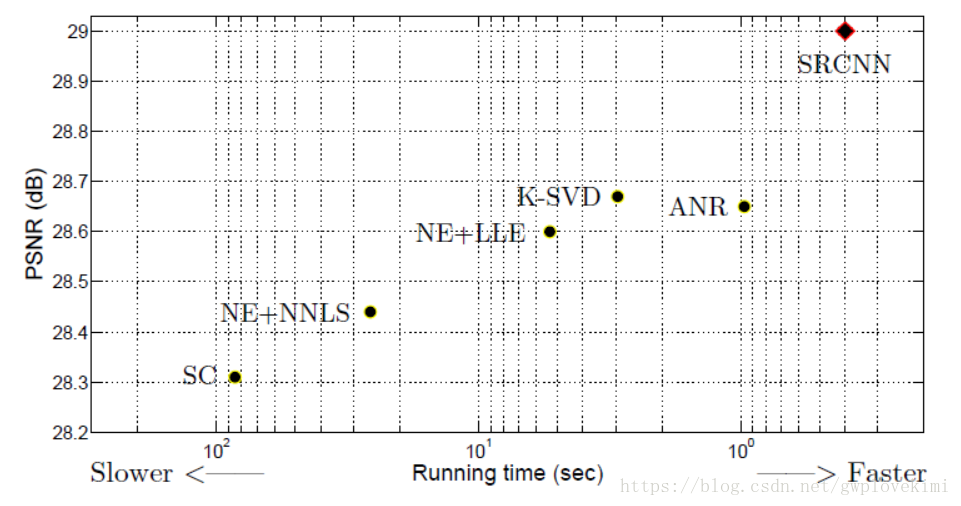
- 【8】总结
SRCNN的本质就是用了深度卷积网络实现了稀疏编码的方法。只不过稀疏编码的参数需要人工优化,而且能优化的参数有限。但是SRCNN能根据输入的训练集自动优化学习所有参数。因此效果比以前的方法要好。
