并发:一个人吃,一口菜一口包子,但由于切换速度快,感觉像在同时吃菜和包子
并行:两个人同时吃,一个人吃包子,一个吃菜,所有吃包子和吃菜是同时的。
同步:并发或并行的各个任务不是独自运行的任务之间有一定的交替顺序,
可能在运行完成一个任务结果后,另一个任务才会开始运行。
(接力赛跑,要拿到接力棒之后下个选手才会开始运行)
异步:并发或并行的各个任务可以独立运行,一个任务的运行不受另一个
任务影响。
(各个选手在不同的赛道比赛一样,跑步速度不受其他赛道选手的影响)
多进程爬虫是并发的方式执行,通过进程的快速切换加快网络爬虫的速度。
为了数据安全所做的决定设置有GIL(GLobal Interpreter Lock)全局解锁器。
在Python中,一个线程的执行过程包括获取GIL,执行代码直到挂起和释放GIL。
import requests
import time
link_list = []
with open ("C:/Users/Administrator/Desktop/alexa.txt") as file:
file_list = file.readlines()
for eachone in file_list:
link = eachone.split('\t')[1]
link = link.replace('\n','')
link_list.append(link)
start = time.time()
for eachone in link_list:
try:
r = requests.get(eachone)
print(r.status_code, eachone)
except Exception as e:
print('Error: ', e)
end = time.time()
print('串行的总时间: ', end-start)
'''python多线程的两种方法
'1、函数式:调用_thread模块中的start_new_thread()函数产生新线程
'2、类包装式:调用Thread库创建线程,从threading.Thread继承'''
import _thread
import time
#为线程定义一个函数
def print_time(threadName, delay):
count = 0
while count<3:
time.sleep(delay)
count+=1
print(threadName, time.ctime())
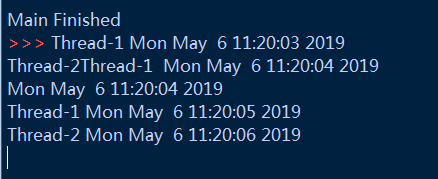
_thread.start_new_thread(print_time,("Thread-1",1)) #新线程
_thread.start_new_thread(print_time,("Thread-2",2)) #新线程
print("Main Finished") #主线程
'''
_thread中使用start_new_thread()函数产生新线程
语法:_thread.start_new_thread(function, args[, kwargs])
其中,function表示线程函数, 在上例中为print_time; args为传递给线程函数
的参数,必须是tuple(元祖)类型,在上例中为("Thread-1",1);最后的kwargs
是可选参数。
_thread提供了低级别,原始的线程,它相比于threading模块,功能比较单一有限
threading模块则提供了Thread类来处理线程。'''
import threading
import time
class myThread(threading.Thread):
def __init__(self, name, delay):
threading.Thread.__init__(self)
self.name = name
self.delay = delay
def run(self):
print("Starting "+self.name)
print_time(self.name, self.delay)
print("Exiting" +self.name)
def print_time(threadName, delay):
counter = 0
while counter <3:
time.sleep(delay)
print(threadName, time.ctime())
counter +=1
'''
过程解说:
1、将任务手动地分到两个线程中,即thread1 = myThread("Thread-1",1)
2、然后在myThread这个类中对线程进行设置,使用run()表示线程运行的方法,
当counter小于3时,打印该线程的名称和时间
3、使用thread.start()开启线程,使用threads.append()将线程加入线程列表
用t.join()等待所有子线程完成才会继续执行主线程。
总结:threading能够有效地控制线程。
'''
threads = []
#创建新线程
thread1 = myThread("Thread-1",1)
thread2 = myThread("Thread-2",2)
#开启新线程
thread1.start()
thread2.start()
#添加线程到线程列表
threads.append(thread1)
threads.append(thread2)
#等待所有线程完成
for t in threads:
t.join()
print("Exiting Main Thread")
#将Pyhon多线程的代码应用在获取1000个网页上,并开启5个线程
import threading
import requests
import time
link_list = []
with open("D:/大四上/毕业论文/alexa.txt","r") as file:
file_list = file.readlines()
for eachone in file_list:
link = eachone.split('\t')[1]
link = link.replace('\n', '')
link_list.append(link)
print(link_list) #1000个urls组成的列表
start = time.time()
class myThread (threading.Thread):
def __init__(self, name, link_range):
threading.Thread.__init__(self)
self.name = name
self.link_range = link_range
def run(self):
print("Starting " +self.name)
crawler(self.name, self.link_range)
print("Exiting " + self.name)
def crawler(threadName, link_range):
for i in range(link_range[0], link_range[1]+1):
try:
r =requests.get(link_list[i] , timeout =10)
print(threadName, r.status_code, link_list[i])
except Exception as e:
print(threadName, 'Error: ',e)
thread_list =[]
link_range_list =[(0,200), (201,400),(401,600),(601,800),(801,1000)]
#创建新线程
for i in range(1,6):
thread = myThread("Thread-" + str(i), link_range_list[i-1])
#thread = myThread("Thread-1",(0,200))
thread.start()
thread_list.append(thread)
#等待所有线程完成
for thread in thread_list:
thread.join()
#join():等待至线程中止,阻塞调用线程至线程的join()方法被调用为止。
end = time.time()
print("简单多线程爬虫的总时间为:", end - start)
使用Queue的多线程爬虫
'''Python中的Queue模块提供了同步的,线程安全的队列类,包括先进先出队列(FIFO)
LIFO(后进先出)队列,和优先队列 PriorityQueue.
将1000个网页放入Queue队列中,各个线程都是从这个队列中获取链接,直到完成
所有的网页抓取为止
'''
import threading
import requests
import time
import queue as Queue
link_list = []
with open("D:/大四上/毕业论文/alexa.txt","r") as file:
file_list = file.readlines()
for eachone in file_list:
link = eachone.split('\t')[1]
link = link.replace('\n', '')
link_list.append(link)
start = time.time()
class myThread(threading.Thread):
def __init__(self, name, q):
threading.Thread.__init__(self)
self.name = name
self.q = q
def run(self):
print("Starting "+self.name)
while True:
try:
crawler(self.name, self.q)
except:
break
print("Exiting "+self.name)
def crawler(threadName,q):
url =q.get(timeout=2) #3、q.get(url) 读队列
try:
r=requests.get(url, timeout=20)
print(q.qsize(), threadName, r.status_code, url)
except Exception as e:
print(q.qsize(), threadName, url, "Error: ",e)
workQueue =Queue.Queue(1000)
#1、定义workQueue是一个队列且队长为1000
for url in link_list:
workQueue.put(url)
#2、workQueque.put(url) 把1000urls写入队列中
threadList = ["Thread-1","Thread-2","Thread-3","Thread-4","Thread-5"]
threads=[]
#创建新线程
for tName in threadList:
thread = myThread(tName, workQueue) #定义一个线程,线程要做什么——run()
thread.start() #线程开启
threads.append(thread) #线程加入到thread
#等待所有线程完成
for t in threads:
t.join() #等待至线程终止
end =time.time()
print("Queue多线程爬虫的总时间为: ",end-start)
print("Exiting Main Thread")
Queue多线程爬虫的总时间为: 404.31512546539307
关于queue队列
python中的队列分类可分为两种:
1.线程Queue,也就是普通的Queue
2.进程Queue,在多线程与多进程会介绍。
Queue的种类:
FIFO:
Queue.Queue(maxsize=0)
FIFO即First in First Out,先进先出。Queue提供了一个基本的FIFO容器,使用方法很简单,maxsize是个整数,指明了队列中能存放的数据个数的上限。一旦达到上限,插入会导致阻塞,直到队列中的数据被消费掉。如果maxsize小于或者等于0,队列大小没有限制。
LIFO
Queue.LifoQueue(maxsize=0)
LIFO即Last in First Out,后进先出。与栈的类似,使用也很简单,maxsize用法同上
priority
class Queue.PriorityQueue(maxsize=0)

构造一个优先队列。maxsize用法同上。
基本方法:
Queue.Queue(maxsize=0) FIFO, 如果maxsize小于1就表示队列长度无限
Queue.LifoQueue(maxsize=0) LIFO, 如果maxsize小于1就表示队列长度无限
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空,返回True,反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.get([block[, timeout]]) 读队列,timeout等待时间
Queue.put(item, [block[, timeout]]) 写队列,timeout等待时间
Queue.queue.clear() 清空队列
其他:
task_done()
意味着之前入队的一个任务已经完成。由队列的消费者线程调用。每一个get()调用得到一个任务,接下来的task_done()调用告诉队列该任务已经处理完毕。
如果当前一个join()正在阻塞,它将在队列中的所有任务都处理完时恢复执行(即每一个由put()调用入队的任务都有一个对应的task_done()调用)。
join()
阻塞调用线程,直到队列中的所有任务被处理掉。
只要有数据被加入队列,未完成的任务数就会增加。当消费者线程调用task_done()(意味着有消费者取得任务并完成任务),未完成的任务数就会减少。当未完成的任务数降到0,join()解除阻塞。
'''
1、python的多线程爬虫只能运行在单核上,各个线程以并发的方法异步运行。
2、由于全局解锁器GIL的存在,多线程爬虫并不能充分地发挥多核CPU的资源。
作为提升Python网络爬虫速度的另一种办法, 多线程爬虫则可以利用CPU的多核,
进程数取决于计算机CPU的处理器个数。由于运行在不同的核上,各个进程的运行
是并行的。要用到多进程,就需要用到multiprocessing这个库
使用mulprocessing库两种方法:
1、Process+Queue
2、Pool+Queue
'''
Multiprocess库Queue+Process类的方法实现多线程爬虫
#Multiprocess库Queue+Process类的方法实现多线程爬虫
from multiprocessing import cpu_count
print(cpu_count()) #输出CPU的核心数量
from multiprocessing import Process,Queue
import time
import requests
link_list = []
with open("D:/大四上/毕业论文/alexa.txt", 'r') as file:
file_list =file.readlines()
for eachone in file_list:
link = eachone.split('\t')[1]
link = link.replace('\n','')
link_list.append(link)
start = time.time()
class MyProcess(Process):
def __init__(self, q):
Process.__init__(self)
self.q = q
def run(self):
print("Starting ",self.pid)
while not self.q.empty():
crawler(self.q)
print("Exiting ", self.pid)
def crawler(q):
url = q.get(timeout = 2)
try:
r = requests.get(url, timeout=20)
print(q.qsize(), r.status_code, url)
except Exception as e:
print(q.qsize(), url, "Error: ",e)
if __name__=="__main__":
ProcessName = ["Process-1","Process-2","Process-3"]
workQueue = Queue(1000)
#填充队列
for url in link_list:
workQueue.put(url)
for i in range(0, 3):
p = MyProcess(workQueue)
p.daemon = True
#在多进程中,每个进程都可以单独设置它的daemon属性
#将daemon设置为True时,当父进程结束后,子进程就会自动被终止。
p.start()
p.join()
end = time.time()
print("Process + Queue 多进程爬虫的时间为 : ", end-start)
print("Main process Ended!")
什么时候适合使用Process+Queue,什么时候适合使用Pool+Queue的多进程爬虫?
当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态生成多个
进程,十几个还好,但是上百个,上千个目标,手动地限制进程数量就太过烦琐,此时
可以使用Pool发挥程池的功效。
使用Pool+Queue的多进程爬虫
Pool可以提供指定数量的进程供用户调用。当有新的请求提交到pool时,
如果池还没有满,就会创建一个新的进程用来执行该请求;但如果池中的进程数
已经达到规定的最大值,该请求就会继续等待,直到池中有进程结束才能够创建
新的进程。
阻塞与非阻塞
程序在等待调用结果(消息,返回值)时的状态。阻塞要等到回调结果出来,在
有结果之前,进程会被挂起。非阻塞为添加进程后,不一定非要等到结果出来就
可以添加其他进程运行。
#使用Pool+Queue的多进程爬虫
from multiprocessing import Pool, Manager
import time
import requests
link_list = []
with open('D:/大四上/毕业论文/alexa.txt','r') as file:
file_list = file.readlines()
for eachone in file_list:
link = eachone.split("\t")[1]
link = link.replace("\n",'')
link_list.append(link)
print(link_list)
start = time.time()
def crawler(q, index):
Process_id = 'Process-' + str(index)
while not q.empty():
url= q.get(timeout=2)
try:
r = requests.get(url, timeout =20)
print(Process_id, q.qsize(), r.status_code, url)
except Exeption as e:
print(Process_id, q.qsize(), url, 'Error: ', e)
if __name__ == '__main__':
#创建队列
manager = Manager()
workQueue = manager.Queue(1000)
#workQueue这个队列的对象可以在父进程和子进程间通信
#填充队列
for url in link_list:
workQueue.put(url)
#创建线程池和线程,使用Pool(processes =3)创建线程池的最大值为3
pool = Pool(processes =3)
for i in range(4):
pool.apply_async(crawler, args = (workQueue, i)) #!!!!!!!
#使用pool创建子进程
#使用pool.apply_async(crawler, args = (workQueue, i))创建非阻塞进程,async(异步)
#pool.apply(crawler, args = (workQueue, i ))创建阻塞进程
print("Started processes")
pool.close()
pool.join()
end =time.time()
print('Pool + Queue 多进程爬虫的总时间为 :', end-start)
print("Main process ended!")
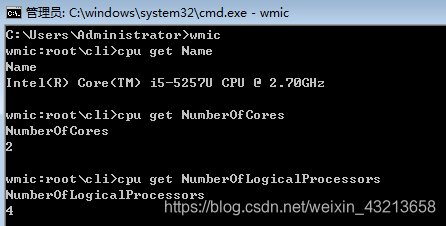
Name:表示物理CPU数 ——1个CPU
NumberOfCores:表示CPU核心数 ——2个CPU核心
NumberOfLogicalProcessors:表示CPU线程数——4个线程
多线程,多进程,多协程(Coroutine)
协程是一种用户态的轻量级线程。
优点:
1、协程像一种在程序级别模拟系统级别的进程,由于是单线程,并且少了上下文切换,
因此相对来说对系统消耗很少,并且网上的各种测试也表明协程确实有惊人的速度。
2、协程方便切换控制流,简化了编程模型。协程能保留上一次调用时的状态(所有局部
状态的一个特定组合),每次过程重入时,就相当于进入了上一次调用的状态。
3、协程的高扩展性和高并发性,一个CPU支持上万协程都不是问题,所以很适合高并发
处理。
缺点:
1、协程的本质是一个单线程,不能同时使用单个CPU的多核,需要和进程配合才能运行在
多CPU上
2、有长时间阻塞的IO操作时,不需要协程,因为可能会阻塞整个程序。

1、t1 = threading.Thread(target = “”) #创建对象
t1.start() #创建线程并执行
2、主线程一定从头活到尾
3、当有多个线程时,可以通过下面方法来确保先执行某个线程。
t1.start()
time.sleep(1)
t2.start()
time.sleep(1)
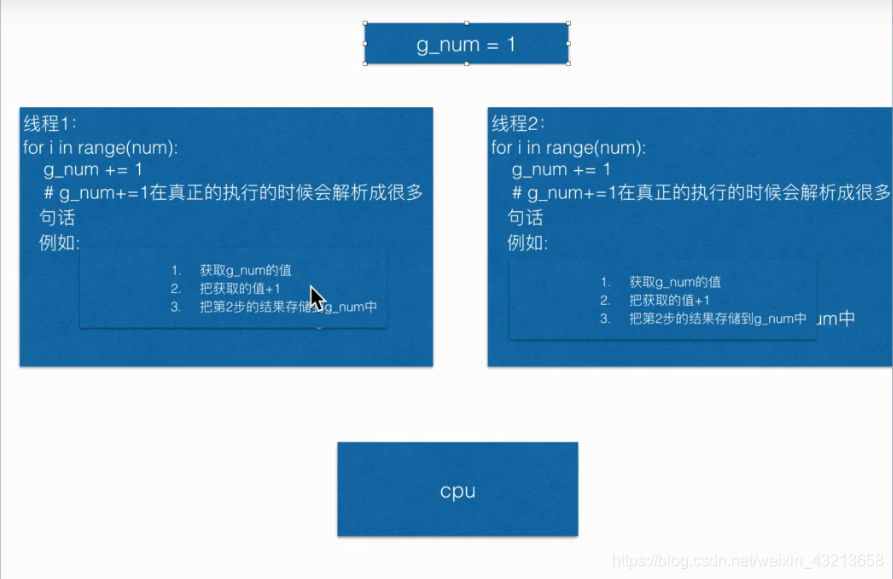
4、全局变量:
优点:不同线程之间可以共享
缺点:在共享时,由于CPU的快速切换线程,导致在执行时,编程语句交替执行,结果会有误。
尤其是计算量很大的时候。
改进:采用互斥锁
弊端:导致死锁
改进:1、添加超时时间
2、在程序设计时要避免,例:银行家算法。
