Redis 单线程还是多线程
前段时间无意间看到一篇博客,讲述了Redis6即将在年底发布的事情,好奇心驱动下搜索了官网,想看看新版Redis带来了什么新的功能,果然得到证实Redis在年底将发布新的版本:6.0,并且Redis创始人兼核心开发者 antirez 在博客也介绍了将在6.0所提供的新功能
ACL用户权限控制功能
RESP3:新的 Redis 通信协议
Cluster 管理工具
SSL 支持
IO多线程支持
新的Module API
新的 Expire 算法等
具体可以参考相关资料(http://antirez.com/latest/0)
这里只是大致说一下自身比较感兴趣的功能
IO多线程
刚开始看到Redis支持多线程的时候,其实自身心里挺疑惑的,Redis难道是单线程?为什么单线程响应能够那么快?带着这些疑问翻阅了相关资料。官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案。
那既然是单线程那为什么会那么快呢?原来Redis使用了单线程架构和I/O多路复用模型来实现高性能的内存数据库服务,只所以快可归结一下几点:
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求
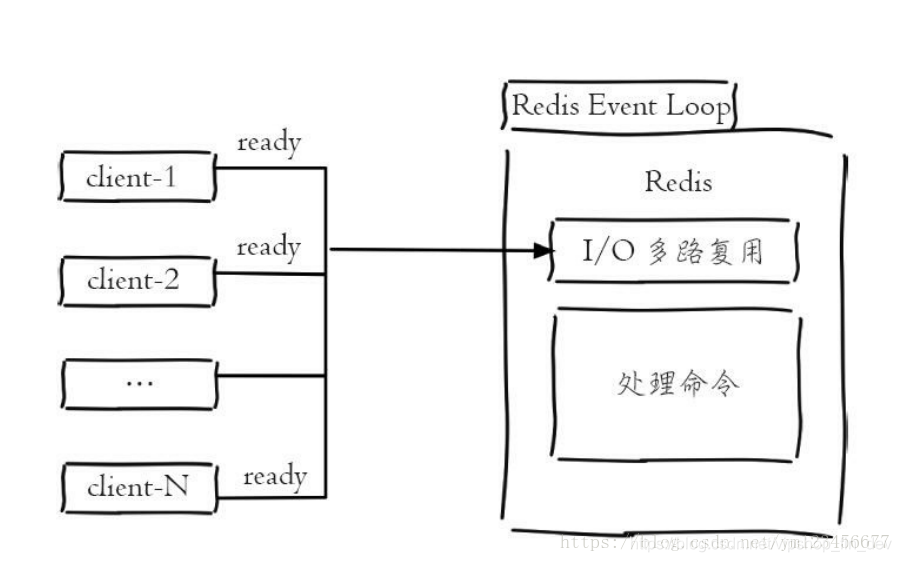
以上几点都比较好理解,下边我们针对多路 I/O 复用模型进行简单的探讨:
首先,Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现的.
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,主要由以上几点造就了 Redis 具有很高的吞吐量
注意:上面说的都是单线程的优点,但单线程也有其缺点,对于每个命令的执行时间有要求,如果某个命令执行时间过长,会造成其他命令阻塞,对于Redis这种高性能的服务来说是致命的。
既然单线程Redis这么优越,Redis 6.0引入的IO多线程岂不是多余?
答案肯定是非也,目前对于单线程 Redis 来说,性能瓶颈主要在于网络的 IO 消耗,优化主要有两个方向:
1、提高网络 IO 性能,典型的实现像使用 DPDK 来替代内核网络栈的方式
2、使用多线程充分利用多核,典型的实现像 Memcached
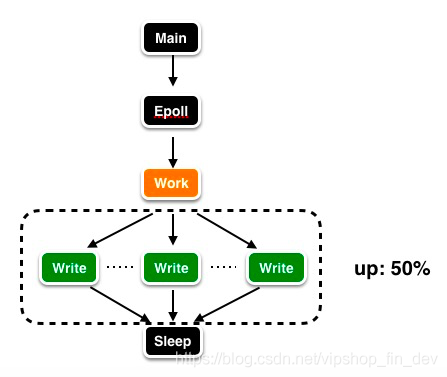
协议栈优化的这种方式跟 Redis 关系不大,多线程特性在社区也被反复提了很久后, Redis作者antirez终于在 Redis 6 加入多线程(据说多线程 IO 特性的引入对性能提升至少是一倍以上,http://antirez.com/news/126)。因为读写网络的read/write系统调用在Redis执行期间占用了大部分CPU时间,如果把网络读写做成多线程的方式对性能会有很大提升,这里所说的多线程,是通过系统调用写操作,将客户端的输入输出缓冲中的数据通过多线程IO与客户端交互。现在已经实现了第一版,write side即回复客户端这部分已经完成了,并且去掉了主线程和IO线程之间的互斥锁,采用busy loop的形式来等待io线程工作结束,这部分能够有50%的性能提升,架构图如下
但跟 Memcached 这种从 IO 处理到数据访问多线程的实现模式有些差异,Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。之所以这么设计是不想因为多线程而变得复杂,需要去控制 key、lua、事务,LPUSH/LPOP 等等的并发问题。整体的设计大体如下:
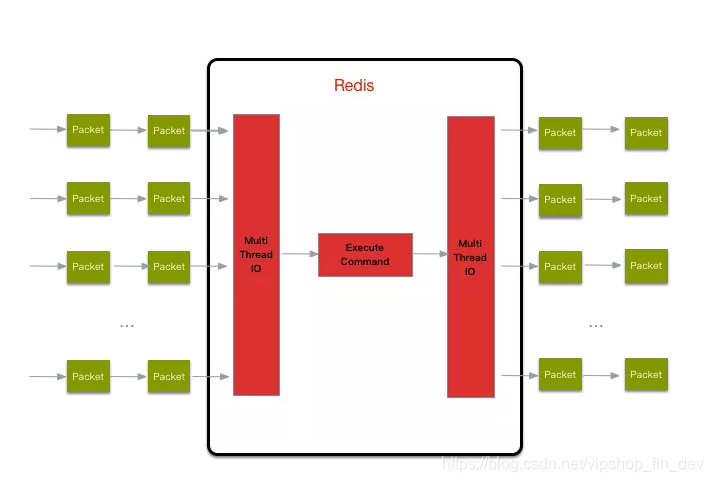
多线程 IO 的读(请求)和写(响应)在实现流程是一样的,只是执行读还是写操作的差异。同时这些 IO 线程在同一时刻全部是读或者写,不会部分读或部分写的情况,所以下面以读流程作为例子。分析过程中只会覆盖核心逻辑而不是全部细节。如果想完全理解细节,建议看完之后再次看一次源码实现。
加入多线程 IO 之后,整体的读流程如下:
1、主线程负责接收建连请求,读事件到来(收到请求)则放到一个全局等待读处理队列
2、主线程处理完读事件之后,通过 RR(Round Robin) 将这些连接分配给这些 IO 线程,然后主线程忙等待(spinlock 的效果)状态
3、IO 线程将请求数据读取并解析完成(这里只是读数据和解析并不执行)
4、主线程执行所有命令并清空整个请求等待读处理队列(执行部分串行)
上面的这个过程是完全无锁的,因为在 IO 线程处理的时主线程会等待全部的 IO 线程完成,所以不会出现data race的场景。
总结
不管单线程还是多少线程,其实对应Redis不同模块而已。对于Redis 6.0 2019 年底发布,其将在性能、协议以及权限控制都会有很大的改进,还是值得期待的。
最后在说一下,Redis 6.0将采用全新协议 RESP3,进而实现 Client side caching(客户端缓存)功能,可以说是在提升Redis作为缓存的读写能力有了质的飞跃,值得期待。有兴趣的可以看看RESP3 的设计稿:
https://github.com/antirez/RESP3/blob/master/spec.md
