tensorflow笔记01:激活函数与损失函数
激活函数概念
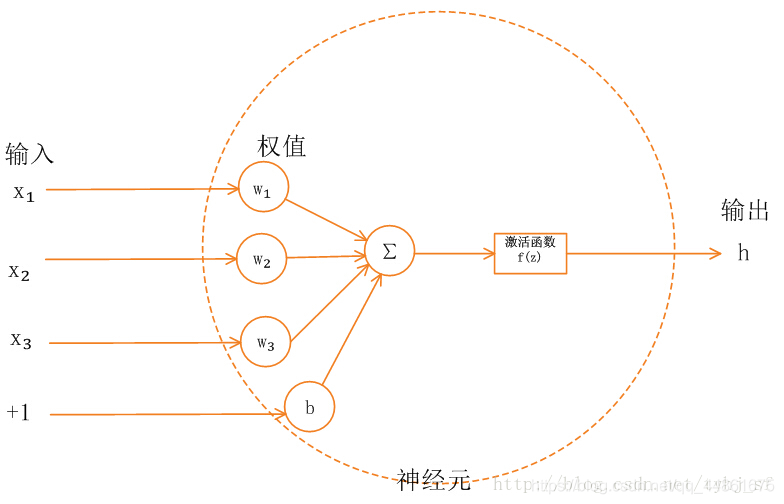
神经网络中的每个神经元节点接受上一层神经元的输出值作为本神经元的输入值,并将输入值传递给下一层,输入层神经元节点会将输入属性值直接传递给下一层(隐层或输出层)。在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数(又称激励函数)。
上图中,x是输入,b是偏置项,w是权重参数
激活函数的用途
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层节点的输入都是上层输出的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了,那么网络的逼近能力就相当有限。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可以逼近任意函数)。
激活函数的种类
常见的损失函数有:relu,sigmoid,tanh
1.relu()----在tensorflow中表示为tf.nn.relu()

2.sigmoid()–在tensorflow中表达tf.nn.sigmoid()

3.tanh()–在tensorflow中表达为tf.nn.tanh()

损失函数概念
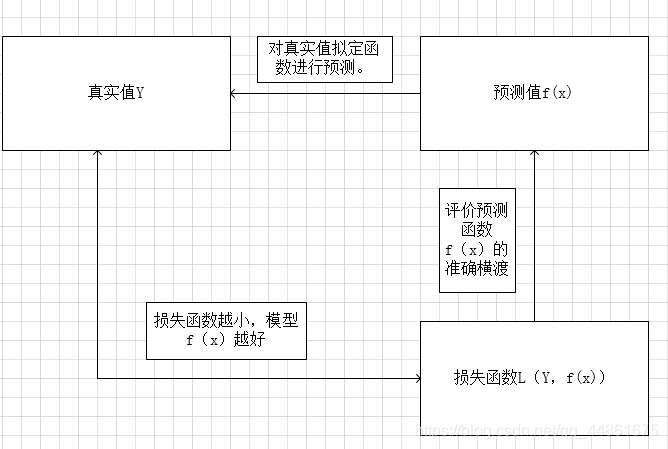
简单表述:机器学习模型关于单个样本的预测值与真实值的差称为损失。损失越小,模型越好,如果预测值与真实值相等,就是没有损失。用于计算损失的函数称为损失函数。模型每一次预测的好坏用损失函数来度量。
损失函数作用
衡量模型模型预测的好坏。它可以很好的反映模型与实际数据差距的工具,理解损失函数能够更好得对后续优化工具(梯度下降等)进行分析与理解
tensorflow常用损失函数类型及表达
1.均方误差mse -----tensorflow中表达为tf.reduce_mean(tf.square(y_,y))

2.自定义损失函数:根据问题的实际,定制合理的损失函数
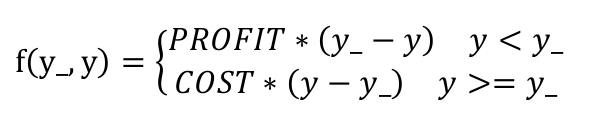
如图上的自定义损失函数在tensorflow中表达为:
loss = tf.reduce_sum(tf.where(tf.greater(y_,y),COST*(y-y_),PROFIT*(y-y_) ) )
3.交叉熵(CrossEntropy)-- ce = -tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-12,1.0) ) )
交叉熵表示两个概率分布之间的距离,交叉熵越大,表示两个概率分布越远,差别越大,反之,两个概率分布距离越近,越相似
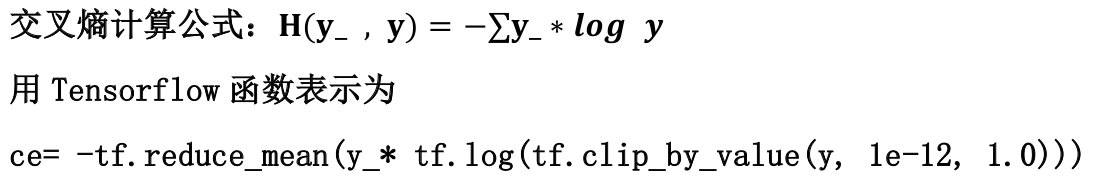
意思是当y>1.0,y=1.0;y<10-12,y=10-12,避免无效的输入(概率不可能大于1,也不应该太小,太小算距离就没意思了。在 Tensorflow 中,一般让模型的输出经过 sofemax 函数,以获得输出分类的概率分布,再与标准答案对比,求出交叉熵,得到损失函数,用如下函数实现:
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cem = tf.reduce_mean(ce)
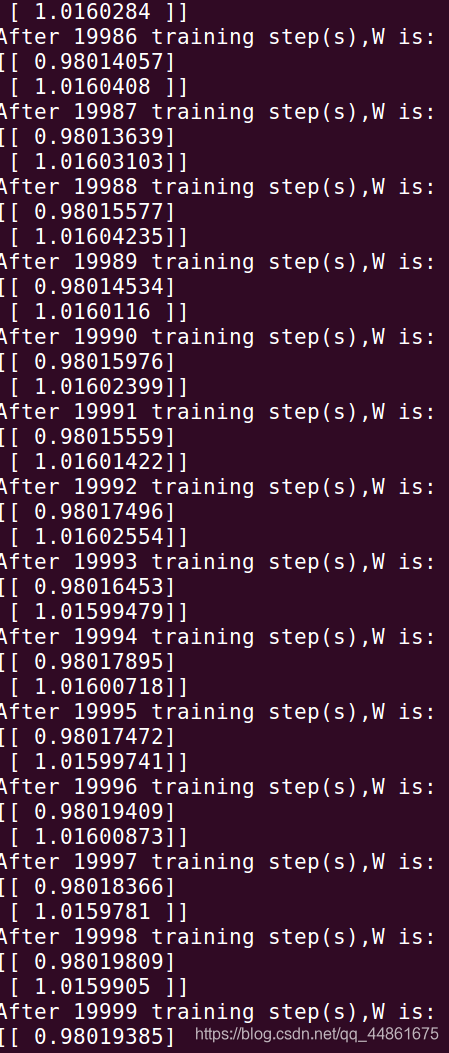
使用均方误差代码
#coding=utf-8
2 #导入包与模块
3 import numpy as np
4 import tensorflow as tf
5
6 #第一个文件是写激活函数《rule,sigmoid,tanh》
7 #例子是卖商品,Cost与Profit
8 #酸奶问题,x1,x2是影响因素,y是日售量,现在分别用三种损失函数模拟出三者关系
9
10
11 #创建数据集合x1,x2,y,注意加入 -0.05~+0.05的噪声
12 BATCH_SIZE = 8
13 SEED = 23455
14
15 #产生32×2的x的数据集,每行两个数据代表x1,x2
16 rng = np.random.RandomState(SEED)
17 X = rng.rand(32,2)
18 #产生实际加载了噪声的Y数据集
19 Y_ = [[x1+x2+(rng.rand()/10.0-0.05)] for (x1,x2) in X]
20
21 #定义神经网络的输入x,参数w,输出y(这里只有一层隐藏层
22 x = tf.placeholder(tf.float32,shape=(None,2))
23 #标准输出值
24 y_ =tf.placeholder(tf.float32,shape=(None,1))
25 w = tf.Variable(tf.random_normal([2,1],stddev=1,mean=0,seed=1))
26 y = tf.matmul(x,w)
27
28 #定义损失函数,激活函数及反向传播方法(均方误差方法)
29 loss = tf.reduce_mean(tf.square(y_-y))
30 train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss)
31
32 #生成会话,初始化会话,开始训练
33 with tf.Session() as sess:
34 init_opt = tf.global_variables_initializer()
35 sess.run(init_opt)
36 #定义训练轮数,+1
37 steps = 20000
38 for i in range(steps):
39 start = (i*BATCH_SIZE)%32
40 end = (i*BATCH_SIZE)%32+BATCH_SIZE
41 #开始训练
42 sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]})
43 #每500轮打印当前权重
44 print "After %d training step(s),W is:\n"%(i),sess.run(w)
45 #打印最后的权重
46 print "final W is:\n",sess.run(w)
47