三个表进行比较(同样的数据)
每表存4000w条数据
导入千万条数据方法:
https://blog.csdn.net/weixin_45736927/article/details/104492684
注意:本章查询多次用*是为了比较数据查询的时间更准确,也是比较方便
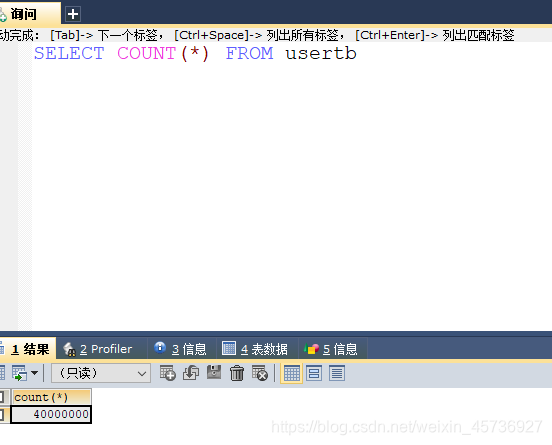
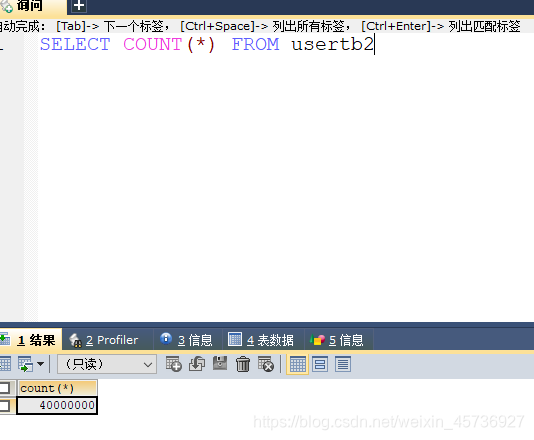
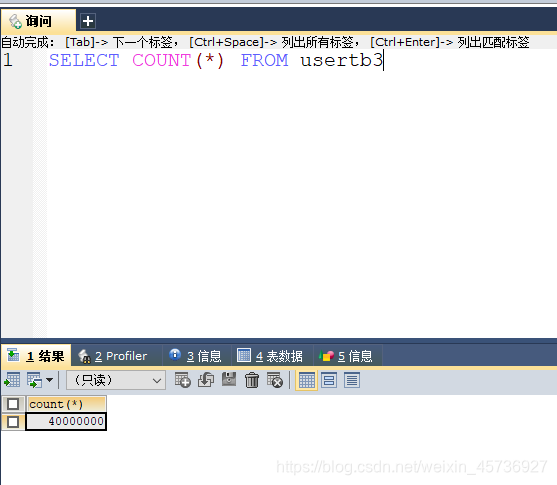
不创建索引和联合索引和单个索引进行比较:
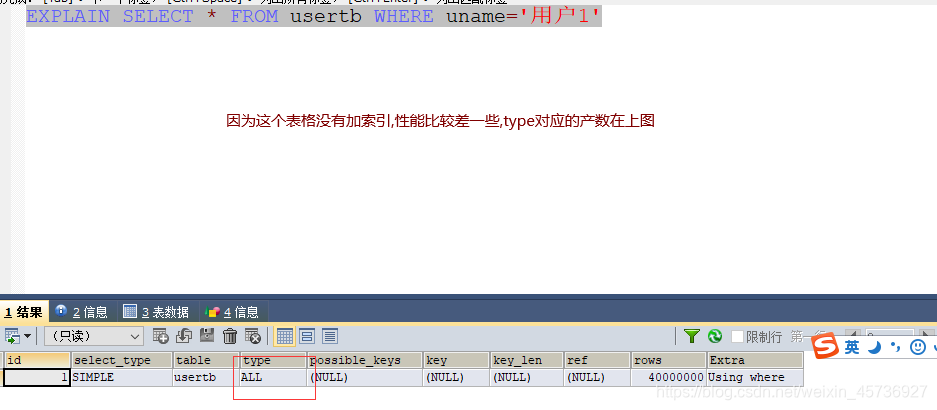
usertb表:不创建索引
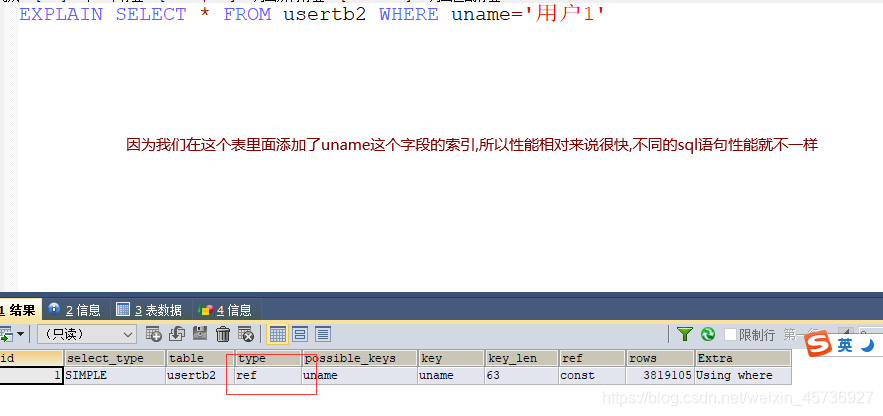
usertb2表:联合索引
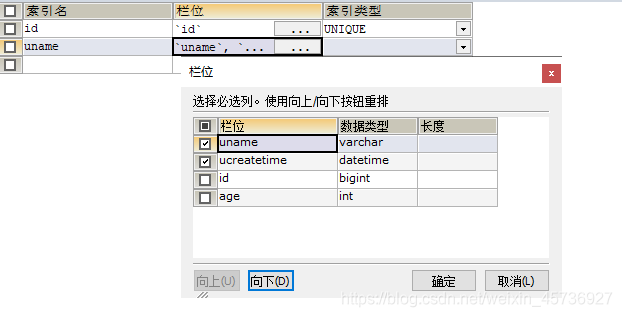
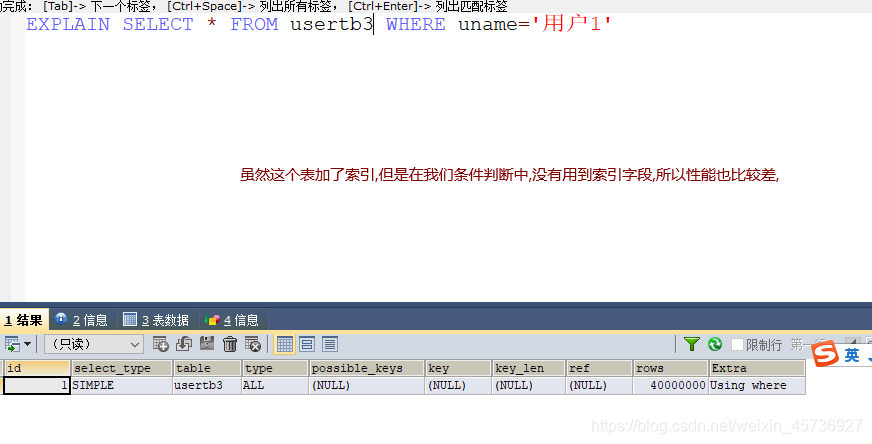
usertb3:单个索引
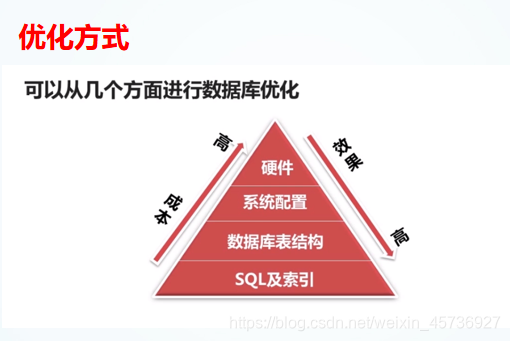
数据库优化的目的:

优化的方式
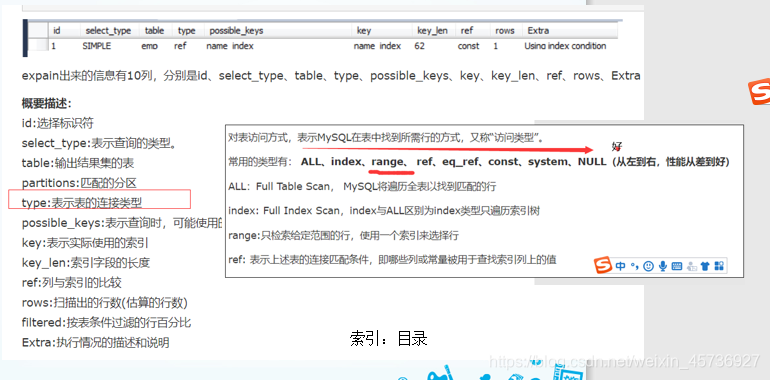
如何查看sql的查询效率
在日常工作中,我们会有时会开慢查询去记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,些时我们常常用到explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。所以我们深入了解MySQL的基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行SQL语句时哪种策略预计会被优化器采用。
– 实际SQL,查找用户名为Jefabc的员工
select * from usertb where uname= ‘用户1’;
– 查看SQL是否使用索引,前面加上explain即可
explain select * from usertb where uname= ‘用户1’;
索引创建原则
a. ORDER BY + LIMIT组合的索引优化
如果一个SQL语句形如:
SELECT [column1],[column2],…. FROM [TABLE] ORDER BY [sort] LIMIT [offset],[LIMIT];
这个SQL语句优化比较简单,在[sort]这个栏位上建立索引即可。
通过这个sql语句
条件:同等数据量
SELECT * FROM usertb ORDER BY ucreatetime DESC
//表名需要改
usertb:用时=======

usertb2:用时=======

usertb3:用时=======

b. WHERE + ORDER BY + LIMIT组合的索引优化
如果一个SQL语句形如:
SELECT [column1],[column2],…. FROM [TABLE] WHERE [columnX] = [VALUE] ORDER BY [sort] LIMIT [offset],[LIMIT];
这个语句,如果你仍然采用第一个例子中建立索引的方法,虽然可以用到索引,但是效率不高。更高效的方法是建立一个联合索引(columnX,sort)
通过这个sql语句
条件:同等数据量
SELECT * FROM usertb WHERE uname='用户1' ORDER BY ucreatetime DESC
//注意表格需要改变
usertb:用时=======

usertb2:用时=======

usertb3:用时=======

并不是加了索引查询就快,可根据上面2个sql语句进行对比,添加索引的时候要根据索引创建原则添加,不同sql语句添加的索引字段不同
总结
建立索引不是建的越多越好,原则是:
第一:
一个表的索引不是越多越好,也没有一个具体的数字,根据以往的经验,一个表的索引最多不能超过6个,因为索引越多,对update和insert操作也会有性能的影响,涉及到索引的新建和重建操作
第二:
建立索引的方法论为:
多数查询经常使用的列;
很少进行修改操作的列;
索引需要建立在数据差异化大的列上
四种索引应用场景:

SQL语句查询注意部分:
- 任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
- 应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
- 应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2 - 应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
应改为:
select id from t where num=10 union all select id from t where num=20
表结构方面优化
- 选择最合适的字段属性,使用可以存在数据的最小的数据类型,例如邮政编码,手机号码这类定长的数字可以用char(6),char(11);性别或者是否这种判断性文字可以用tinyint;字段属性尽量为not null这样不用判断是否为空,减少一个步骤(用其他方式表达你想表达的NULL,比如 -1);如果一定要用text这种类型,最好是采用分表存储;
2.将常用信息和不常用信息分表存储,比如一个商城网站的用户表,用户的昵称,头像,密码,账号这类字段用户登录就会用到,而用户的兴趣爱好了,喜欢的颜色了这种字段就分表存储,相信大家京东账号中的个人信息可能也就在注册的时候打开过,以后就再没注意过了吧。
例子

