string的对象编码
string数据类型的对象编码有两种,分别是embstr和raw。两种编码的区别并不大,embstr相对于raw,内存空间连续。两者的数据格式见下图:
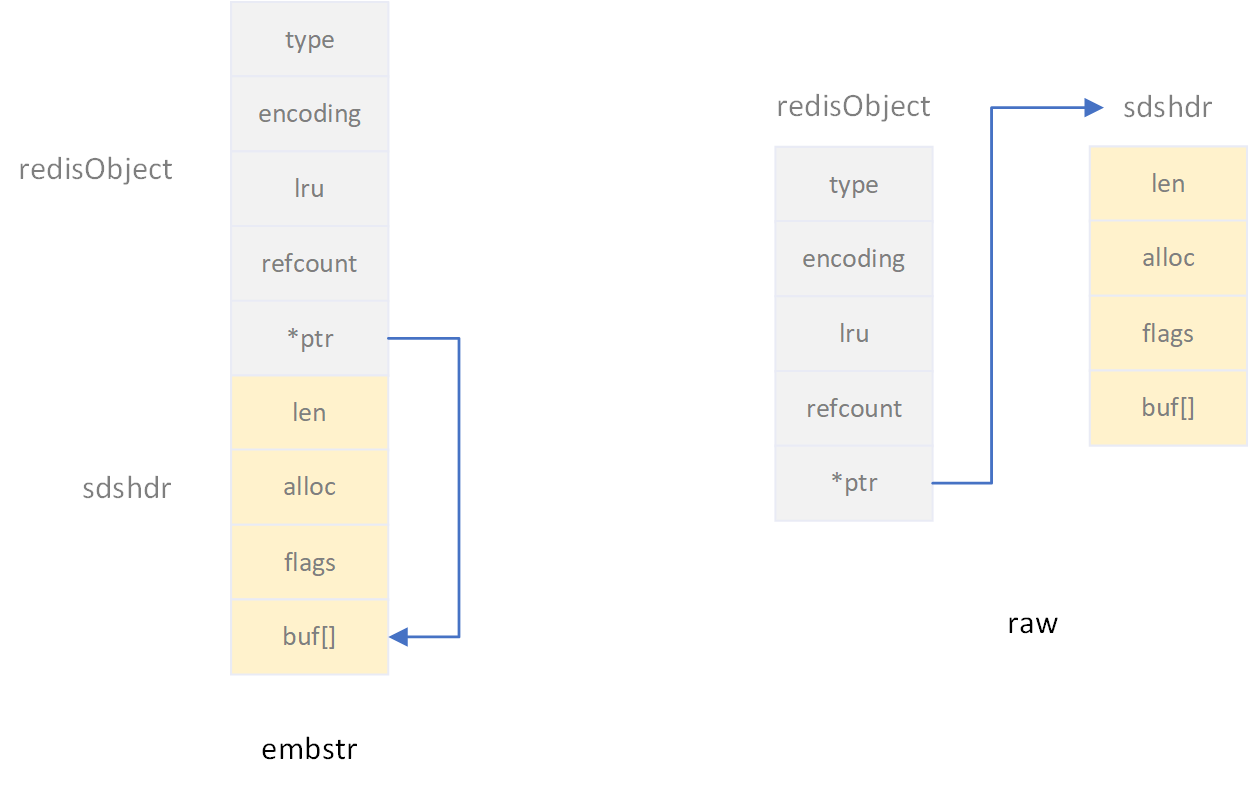
redis的string数据之所以使用embstr和raw两种编码格式,是为了当一个string对象的值比较小时,使用一个连续的内存分区存放redisObject对象和sdshdr对象,减少内存分配和回收的消耗。
embstr编码的string数据只需要创建分配一个内存空间,用于同时存放redisObject对象和sdshdr对象;而raw编码的string数据需要创建两个内存空间分别存放redisObject对象与sdshdr对象,相对于embstr编码多了一次内存分配和一次内存回收的消耗。
编码转换
当一个string对象的长度达到临界值时,就会触发编码转换,该临界值是string值长度:44。
如下测试,当string值的长度不大于44时,通过debug命令输出该string对象的编码格式为encoding:embstr;当string值的长度大于44时,编码格式则为encoding:raw。
127.0.0.1:6379> set key1 12345678901234567890123456789012345678901234
OK
127.0.0.1:6379> debug object key1
Value at:0x7f8428e22080 refcount:1 encoding:embstr serializedlength:21 lru:2200798 lru_seconds_idle:6
127.0.0.1:6379> set key2 123456789012345678901234567890123456789012345
OK
127.0.0.1:6379> debug object key2
Value at:0x7f8428eb3490 refcount:1 encoding:raw serializedlength:21 lru:2200816 lru_seconds_idle:3
关键源码如下:
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
// 当string值长度不大于44,使用embstr编码
// 否则使用raw编码
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
robj *tryObjectEncoding(robj *o) {
...
// 当string值长度不大于44,使用embstr编码
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {
robj *emb;
if (o->encoding == OBJ_ENCODING_EMBSTR) return o;
emb = createEmbeddedStringObject(s,sdslen(s));
decrRefCount(o);
return emb;
}
...
}
embstr
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
// redisObject对象和sdshdr对象使用一个内存空间
// 只需要一次内存分配以及一次内存回收
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
struct sdshdr8 *sh = (void*)(o+1);
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR;
o->ptr = sh+1;
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
else if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
raw
robj *createRawStringObject(const char *ptr, size_t len) {
// 先对sdshdr对象分配内存空间
return createObject(OBJ_STRING, sdsnewlen(ptr,len));
}
robj *createObject(int type, void *ptr) {
// 再对redisObject对象分配内存空间
// raw编码格式需要两次内存分配和两次内存回收
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
return o;
}
临界值44
之所以embstr和raw两种编码格式的临界值是44,是因为redis控制一个string对象的内存大小不大于64字节时为一个小字符串,使用一个连续空间能够提高性能。当string对象的内存大小大于64字节时,则认为是一个大字符串,不再适用embstr编码格式,而使用raw编码。
#define LRU_BITS 24
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len;
uint8_t alloc;
unsigned char flags;
char buf[];
};
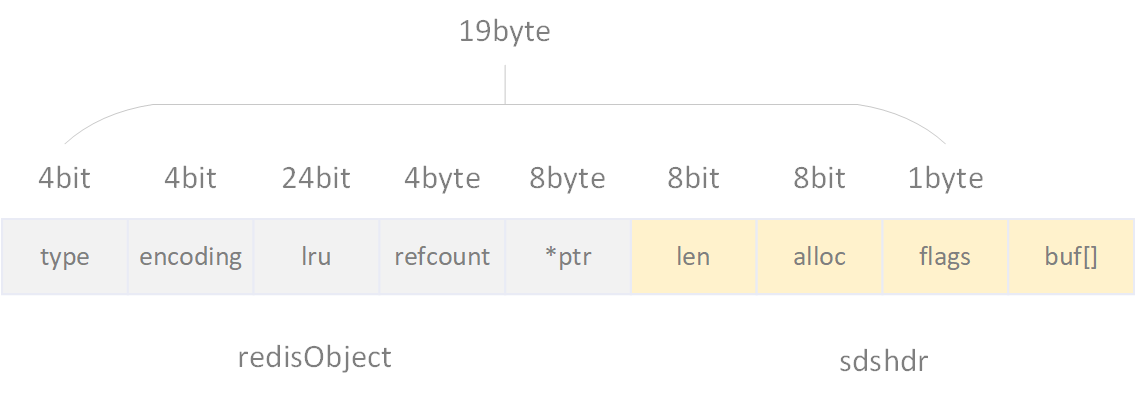
由图可见,redisObject对象和sdshdr对象至少需要占19字节,64个字节空间最后留给string值的只有45个字节。而string末尾需要额外一个\0表示字符串结束,所以实际上留给string值最多只有44个字节。
扩容
redis的string对象直接通过set等方法创建时,不会创建冗余空间,因为大多数情况下创建的string类型不需要进行追加截取等操作。
但是进行SETRANGE、APPEND等对string数据追加截取操作时,redis会对该string数据进行扩容,且扩容后的空间会相对新字符串实际大小多一些冗余空间,用于减少对string数据追加截取操作时的扩容操作从而减少内存空间分配回收的消耗。
扩容规则
- 新字符串大小小于1M时,扩容空间为新字符串大小的2倍即冗余空间等于新字符串大小
- 新字符串大小大于1M时,扩容空间比新字符串大小多1M即冗余空间固定为1M大小
通过预先创建冗余空间,可以减少string数据追加截取时的内存空间分配消耗。
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
// 修改string数据时尝试扩容
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}
#define SDS_MAX_PREALLOC (1024*1024)
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
// 冗余空间足够,不需要扩容
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
// 如果新字符串长度小于1M,扩容空间直接*2
// 如果新字符串长度大于1M,每次多扩容1M
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}
