kafka分布式集群的操作
3.1客户端命令行
3.1.1 kafka-topic.sh
1,shell脚本的作用:
Create:新建主题
delete:删除主题
describe:查看主题的详情
change a topic:更新主题
2,关键参数:
--alter 修改主题
--create Create a new topic(创建主题).
--delete Delete a topic(删除主题)
--describe List details for the given topics(显示出给定主题的详情).
--list List all available topics(罗列出kafka分布式集群中所有有效的主题名).
--partitions 创建或是修改主题时通过该参数指定分区数。
--replication-factor 创建修改主题时通过该参数指定分区的副本数。
--topic 指定主题名
--zookeeper:用来指定zookeeper分布式集群
新建主题
需求1:新建名为hadoop的主题,要求分区数1,副本数1
需求2:新建名为spark的主题,要求分区数2,副本数3
需求3:新建名为flink的主题,要求分区数3,副本数3
实操效果:
[root@NODE02 ~]# kafka-topics.sh --create --topic hadoop --zookeeper node01:2181 --partitions 1 --replication-factor 1
Created topic "hadoop".
[root@NODE02 ~]# kafka-topics.sh --create --topic spark --zookeeper node01:2181,node02:2181,node03:2181 --partitions 2 --replication-factor 3
Created topic "spark".
[root@NODE02 ~]# kafka-topics.sh --create --topic flink --zookeeper node01:2181,node02:2181,node03:2181 --partitions 3 --replication-factor 3
Created topic "flink".
注意点:
[root@NODE02 ~]# kafka-topics.sh --create --topic storm --zookeeper node01:2181,node02:2181,node03:2181 --partitions 3 --replication-factor 4
Error while executing topic command : Replication factor: 4 larger than available brokers: 3.
原因:副本一般是跨节点存储的。从安全性的角度考虑,不允许在一台节点上存在相同的副本(若是可以的话,硬盘要是破坏了,多个相同副本中的数据都会丢失,不安全!!)。
查询主题
方式1:--list参数,查看当前kafka分布式集群中存在的有效的主题名
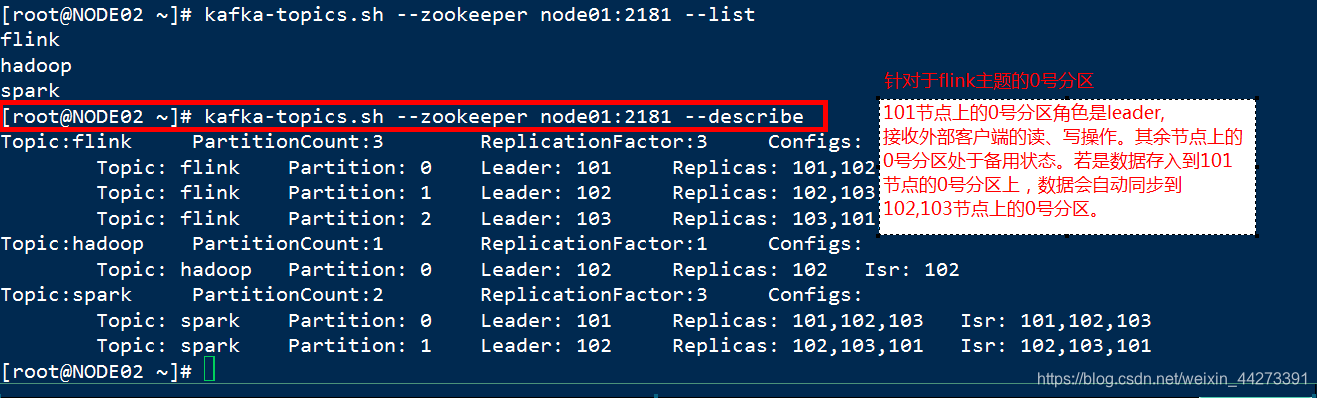
方式2:--describe参数,查看当前kafka分布式集群中存在的有效的主题的详情(主题名,分区数,副本的分布,分区的角色→leader,follower,同一时刻,只有leader角色的分区才能接收读写操作)
实操效果:
[root@NODE02 ~]# kafka-topics.sh --zookeeper node01:2181 --list
flink
hadoop
spark
[root@NODE02 ~]# kafka-topics.sh --zookeeper node01:2181 --describe
Topic:flink PartitionCount:3 ReplicationFactor:3 Configs:
Topic: flink Partition: 0 Leader: 101 Replicas: 101,102,103 Isr: 101,102,103
Topic: flink Partition: 1 Leader: 102 Replicas: 102,103,101 Isr: 102,103,101
Topic: flink Partition: 2 Leader: 103 Replicas: 103,101,102 Isr: 103,101,102
Topic:hadoop PartitionCount:1 ReplicationFactor:1 Configs:
Topic: hadoop Partition: 0 Leader: 102 Replicas: 102 Isr: 102
Topic:spark PartitionCount:2 ReplicationFactor:3 Configs:
Topic: spark Partition: 0 Leader: 101 Replicas: 101,102,103 Isr: 101,102,103
Topic: spark Partition: 1 Leader: 102 Replicas: 102,103,101 Isr: 102,103,101
PartitionCount:topic对应的partition的个数
ReplicationFactor:topic对应的副本因子,说白就是副本个数(包含自己,与hdfs上的副本数相同)
Partition:partition编号,从0开始递增
Leader:当前partition起作用的breaker.id
Replicas: 当前副本数据所在的breaker.id,是一个列表
Isr:当前kakfa集群中可用的breaker.id列表
修改主题
1,不能修改副本因子,否则报错,实操效果如下:
[root@NODE02 ~]# kafka-topics.sh --alter --zookeeper node02:2181 --topic hadoop --replication-factor 2
Option "[replication-factor]" can't be used with option"[alter]"
2,可以修改分区数,实操效果如下:
[root@NODE02 ~]# kafka-topics.sh --alter --zookeeper node02:2181 --topic hadoop --partitions 2
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded!
[root@NODE02 ~]# kafka-topics.sh --zookeeper node02:2181 --topic hadoop --describe
Topic:hadoop PartitionCount:2 ReplicationFactor:1 Configs:
Topic: hadoop Partition: 0 Leader: 102 Replicas: 102 Isr: 102
Topic: hadoop Partition: 1 Leader: 103 Replicas: 103 Isr: 103
注意:
①只能增加分区数,不能减少分区数。实操效果如下:
[root@NODE02 ~]# kafka-topics.sh --alter --zookeeper node02:2181 --topic hadoop --partitions 1
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Error while executing topic command : The number of partitions for a topic can only be increased. Topic hadoop currently has 2 partitions, 1 would not be an increase.
[2019-11-12 11:29:04,668] ERROR org.apache.kafka.common.errors.InvalidPartitionsException: The number of partitions for a topic can only be increased. Topic hadoop currently has 2 partitions, 1 would not be an increase.
(kafka.admin.TopicCommand$)
②主题名不能修改,修改主题时,主题名是作为修改的条件存在的。
删除主题
删除名为hadoop的主题,实操效果如下:
[root@NODE02 flink-0]# kafka-topics.sh --list --zookeeper node01:2181
flink
hadoop
spark
[root@NODE02 flink-0]# kafka-topics.sh --delete --topic hadoop --zookeeper node03:2181
Topic hadoop is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
[root@NODE02 flink-0]# cd ..
[root@NODE02 kafka-logs]# kafka-topics.sh --list --zookeeper node01:2181
flink
spark
[root@NODE02 kafka-logs]# ll
total 20
-rw-r--r-- 1 root root 4 Nov 12 11:34 cleaner-offset-checkpoint
drwxr-xr-x 2 root root 141 Nov 12 10:51 flink-0
drwxr-xr-x 2 root root 141 Nov 12 10:51 flink-1
drwxr-xr-x 2 root root 141 Nov 12 10:51 flink-2
-rw-r--r-- 1 root root 4 Nov 12 11:34 log-start-offset-checkpoint
-rw-r--r-- 1 root root 56 Nov 12 10:29 meta.properties
-rw-r--r-- 1 root root 54 Nov 12 11:34 recovery-point-offset-checkpoint
-rw-r--r-- 1 root root 54 Nov 12 11:35 replication-offset-checkpoint
drwxr-xr-x 2 root root 141 Nov 12 10:51 spark-0
drwxr-xr-x 2 root root 141 Nov 12 10:51 spark-1
注意:
①针对于kafka的版本kafka-1.0.2,在server.properties资源文件中,参数delete.topic.enable默认值是true。就是物理删除。(低版本的kafka,如:0.10.0.1,确实是逻辑删除)
②通过zookeeper进行确认,并且删除了元数据信息。
[zk: node03(CONNECTED) 11] ls /brokers/topics
[flink, spark]
3.1.2、关于消息的发布和订阅
kafka-console-producer.sh消息的生产
参数说明
kafka-console-producer.sh --broker-list MyDis:9092 --topic hadoop
参数说明如下:
--broker-list <String: broker-list> REQUIRED: The broker list string in
the form HOST1:PORT1,HOST2:PORT2. 用来标识kafka分布式集群中的kafka服务器列表
--topic <String: topic> REQUIRED: The topic id to produce
messages to. 指定主题名(消息属于哪个主题的)
其余的参数使用默认值即可。
说明:
①上述的shell脚本后,会进入到阻塞状态,启动一个名为ConsoleProducer的进程
②在控制台录入消息,一行就是一条消息,回车后,送往kafka分布式集群中的MQ(message queue)存储起来。
kafka-console-consumer->消息的订阅
kafka-console-consumer.sh --bootstrap-server MyDis:9092 --topic hadoop --from-beginning
参数名:
--blacklist <String: blacklist> Blacklist of topics to exclude from
consumption. 用来指定黑名单。使用该参数的时机:
对绝大多数的主题感兴趣,对极少数主题不感兴趣。此时,可以将这些不感兴趣的主题名置于黑名单列表中。
--whitelist <String: whitelist> Whitelist of topics to include for
consumption. 用来指定白名单列表。 使用该参数的时机:
对极少数主题感兴趣,对绝大多数的主题不感兴趣。可以将感兴趣的主题置于到白名单列表中。
--zookeeper <String: urls> REQUIRED (only when using old
consumer): The connection string for
the zookeeper connection in the form
host:port.针对于旧的kafka版本,消费的偏移量通过zookeeper来进行维护的。偏移量:记录的是订阅消息的进度,就是消息数。
--bootstrap-server <String: server to REQUIRED (unless old consumer is
connect to> used): The server to connect to.针对于新版本的kafka,消费的偏移量的维护是通过kafka分布式集群自身的一个名为__consumer_offsets主题来维护来维护的。
--from-beginning If the consumer does not already have
an established offset to consume
from, start with the earliest
message present in the log rather
than the latest message. 从头开始消费。否则,不带该参数,只会订阅新产生的消息(前提:订阅方要提前启动。)。
说明:
①上述的shell脚本后,会进入到阻塞状态,启动一个名为ConsoleConsumer的进程
②会读取特定主题相应分区中存储的消息。
a)若是带了参数--from-beginning ,读取该主题所有分区中的数据
b)若是不带参数--from-beginning,当前的订阅方接收不到历史的消息,只能接收到该进程启动后,新产生的消息。
③若是带--zookeeper参数,消费的offset(偏移量),该偏移量通过zookeeer进行维护。如:
[zk: node03(CONNECTED) 44] get /consumers/console-consumer-37260/offsets/spark/1
2
cZxid = 0x10b0000020e
ctime = Tue Nov 12 14:16:03 CST 2019
mZxid = 0x10b0000020e
mtime = Tue Nov 12 14:16:03 CST 2019
pZxid = 0x10b0000020e
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 1
numChildren = 0
④针对于消费offset的维护,高版本的kafka中,若是使用zookeeper来维护,有警告:
[root@NODE03 kafka-logs]# kafka-console-consumer.sh --topic spark --zookeeper node01:2181
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
how do you do?
⑤针对于消费offset的维护,高版本的kafka中,建议kafka分布式集群来维护,会自动创建一个名为__consumer_offsets的主题,该主题默认有50个分区,每个分区默认有一个副本(可以在server.properties文件中手动进行定制):
[root@NODE03 ~]# kafka-topics.sh --describe --topic __consumer_offsets --zookeeper node01:2181
Topic:__consumer_offsets PartitionCount:50 ReplicationFactor:1 Configs:segment.bytes=104857600,cleanup.policy=compact,compression.type=producer
Topic: __consumer_offsets Partition: 0 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 1 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 2 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 3 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 4 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 5 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 6 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 7 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 8 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 9 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 10 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 11 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 12 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 13 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 14 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 15 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 16 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 17 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 18 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 19 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 20 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 21 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 22 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 23 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 24 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 25 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 26 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 27 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 28 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 29 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 30 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 31 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 32 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 33 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 34 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 35 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 36 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 37 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 38 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 39 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 40 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 41 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 42 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 43 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 44 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 45 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 46 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 47 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 48 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 49 Leader: 103 Replicas: 103 Isr: 103
⑥关于偏移量的维护:
a)真实项目中一般需要手动进行维护,达到的效果是:偏移量被某个同类型的进程所独享。
b)偏移量的维护,可选的方案很多:
zookeeper
redis →使用得较多
hbase
rdbms(mysql,oracle等等)
⑦白名单:
情形1:通过kafka维护偏移量:
[root@NODE02 bin]# kafka-console-consumer.sh --whitelist 'storm|spark' --bootstrap-server node02:9092,node01:9092,node03:9092 --from-beginning
呵呵 大大
storm storm
ok ok ok
最近可好?
how do you do?
hehe da da
今天参加了天猫双十一晚会,很happy!
are you ok?
storm 哦
hehe
are you ok?
好不好啊?
yes, I do.
和 呵呵哒
新的一天哦
hehe da da
情形2:通过zookeeper维护偏移量 (高版本不推荐了)
[root@NODE02 bin]# kafka-console-consumer.sh --whitelist storm,spark --zookeeper node01:2181 --from-beginningUsing the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
are you ok?
好不好啊?
yes, I do.
和 呵呵哒
新的一天哦
hehe da da
ok ok ok
呵呵 大大
storm storm
最近可好?
how do you do?
hehe da da
今天参加了天猫双十一晚会,很happy!
are you ok?
storm 哦
hehe
⑧黑名单:
情形1:通过kafka维护偏移量:
[root@NODE02 bin]# kafka-console-consumer.sh --blacklist storm --bootstrap-
server node02:9092,node01:9092,node03:9092 --from-beginning
Exactly one of whitelist/topic is required.
注意:上述的方式,参数“--blacklist”不能单独使用,需要与--whitelist参数或者是--topic参数结合在一起使用。若是一起使用,显得累赘。一般不要带--blacklist。
情形2:通过zookeeper维护偏移量 (不推荐使用)
[root@NODE02 bin]# kafka-console-consumer.sh --blacklist storm,spark --zookeeper node01:2181 --from-beginning
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
flink 哦
关于偏移量的维护:
此时还没涉及到kafka组的概念,即所有的消费者属于一个默认的组,如果在实际使用中,有多个消费者对一个主题进行消费,测试时,可以看到,如果消费者同步存在,那么数据会同时被多个消费组收到,但是消费者不同时消费,就可能存在 数据(1-20) 消费者(1)拉取 3-5,此时偏移量已经到了5,其他消费者只能从头或者从5开始,那么就少拉去一部分数据。解决方案 ,自己维护自己的偏移量
项目中需要手动进行维护,达到效果是:偏移量被某个同类型的进程所独享
偏移量的维护,可选的方案很多
redis:使用的较多
zookeeper
hbase
mysql
白名单黑名单问题
白名单正常使用,黑名单必须和白名单或者topic一起使用(虽然zookeeper可以单独使用黑名单。但是高版本不推荐,只考虑集群维护的情况)
(问题:黑名单是不是没用?,实验topic可不可以和多个topic一起使用)
1 kafka-console-producer.sh --broker-list MyDis:9092 --topic 'hadoop|spark'
WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 15 : {hadoop|spark=INVALID_TOPIC_EXCEPTION} (org.apache.kafka.clients.NetworkClient)
2 kafka-console-producer.sh --broker-list MyDis:9092 --topic hadoop,spark
WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 22 : {hadoop,spark=INVALID_TOPIC_EXCEPTION} (org.apache.kafka.clients.NetworkClient)
3 kafka-console-consumer.sh --bootstrap-server MyDis:9092 --topic 'spark|hadoop' --from-beginning
WARN [Consumer clientId=consumer-1, groupId=console-consumer-81455] The following subscribed topics are not assigned to any members: [spark|hadoop] (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator)
4 kafka-console-consumer.sh --bootstrap-server MyDis:9092 --topic spark,hadoop --from-beginning
WARN [Consumer clientId=consumer-1, groupId=console-consumer-60372] The following subscribed topics are not assigned to any members: [spark,hadoop] (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator)
5 kafka-console-consumer.sh --bootstrap-server MyDis:9092 --topic spark --topic hadoop --blacklist spark --from-beginning
Exception in thread "main" joptsimple.MultipleArgumentsForOptionException: Found multiple arguments for option topic, but you asked for only one
at joptsimple.OptionSet.valueOf(OptionSet.java:179)
at kafka.tools.ConsoleConsumer$ConsumerConfig.<init>(ConsoleConsumer.scala:404)
at kafka.tools.ConsoleConsumer$.main(ConsoleConsumer.scala:52)
at kafka.tools.ConsoleConsumer.main(ConsoleConsumer.scala)
首先,明显在--topic 后面,是将hadoop|spark 或者 hadoop,spark当成一个整体主题,所以报警。
白名单和黑名单一起使用时,黑名单是否对白名单过滤?(结果白名单比黑名单的范围大)
1 kafka-console-consumer.sh --bootstrap-server MyDis:9092 --whitelist '.*' --blacklist spark --from-beginning
res:spark spark
未过滤:(结果白名单比黑名单的范围大)
官网解释:
Sometimes it is easier to say what it is that you don't want. Instead of using --whitelist to say what you want to mirror you can use --blacklist to say what to exclude. This also takes a regular expression argument. However, --blacklist is not supported when the new consumer has been enabled (i.e. when bootstrap.servers has been defined in the consumer configuration).
