函数调用的压栈模型对于我们学习C语言非常重要,最直观的体现在我们后面要学的函数的递归,函数的递归就充分利用的函数的压栈模型
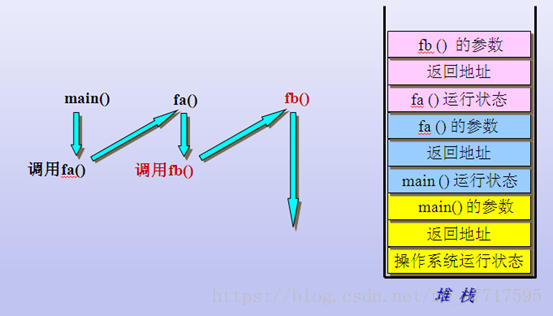
当函数从入口函数main函数开始执行时,编译器会将我们操作系统的运行状态,main函数的返回地址、main的参数、mian函数中的变量、进行依次压栈;当main函数开始调用fa()函数时,编译器此时会将main函数的运行状态进行压栈,再将fa()含糊的返回地址、fa函数的参数、fa定义变量依次压栈;当fa调用fb的时候,编译器此时会将fa函数的运行状态进行压栈,再将fb含糊的返回地址、fb函数的参数、fb定义变量依次压栈。
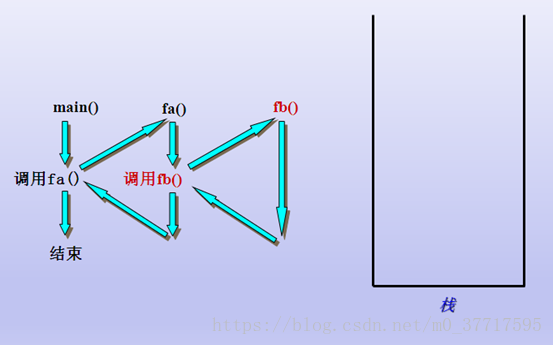
当函数fb运行完成后,fb所有的压栈都会被编译器释放掉,编译器再从栈中接收到fa函数的运行状态后,衔接调用fb函数之前的操作,继续执行,同理,fa执行完后,编译器对mian函数的处理也相同。
一个函数可以在栈上分配内存,也可以在堆上分配内存,更可以在全局区域分配内存,因此理解内存从哪里来,对于我们函数参数的传递,变量的调用异常重要。
fb函数在栈上分配的内存,不能被fa和mian函数所调用,因为它会在fb函数执行完后被编译器释放掉;而 fb函数使用new或者malloc在堆上分配的内存或者在全局区分配的内存,只要不被程序员自己释放掉,是可以可以被fa和main函数所调用的。