一 、open()
open()函数用于打开一个文件,创建一个file对象,相关的方法才可以调用它的读写
open(name,[,mode[,buffering]])
name - 一个包含了你要访问的文件名称的字符串
mode - mode决定了打开文件的模式,只读,写入,追加等等具体值如下列表,这个参数时默认参数,r
buffering - 如果buffering的值被设置为0,就不会有寄存。如果取值为1 访问文件时会寄存行。如果将buffering的值设置
为大于1的整数,表明了这就是寄存取的缓冲大小,如果取值为负值,寄存器的换中去大小则为系统默认。
mode 的取值参数列表
| 模式 | 描述 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头,这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读,文件的指针将会放在文件的开头。 |
| r+ | 打开一个文件用于读写,文件的指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入,如果该文件已经存在则将该文件覆盖(源文件内容清空),如果文件不存在,创建新的文件。 |
| wb | 以二进制格式打开一个文件只用于写入,如果该文件已经存在,则将文件覆盖,如果文件不存在,则创建文件。 |
| wb+ | 以二进制代开一个文件用于读写,如果该文件存在,则覆盖该文件,如果不村子,则创建新的文件 |
| a | 打开一个文件用于追加,如果该文件存在,文件指针将会放到文件的结尾,也就是说,新的内容将会被写入到已有的 文件内容之后。如果该文件不存在,创建新文件进行写入 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾 也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文 件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创 建新文件用于读写 |
二 、file对象方法
file 对象方法
file.read([size]) #size未指定则返回整个文件,如果文件大小>2倍内存则有问题.f.read()读到文件尾时返回""(空字串)
file.readline() #返回一行
file.readlines([size]) #返回包含size行的列表,size 未指定则返回全部行
for line in f: print line #通过迭代器访问
f.write("hello\n") #如果要写入字符串以外的数据,先将他转换为字符串.
f.tell() #返回一个整数,表示当前文件指针的位置(就是到文件头的比特数).
f.seek(偏移量,[起始位置]) #用来移动文件指针.
#偏移量:单位:比特,可正可负
#起始位置:0-文件头,默认值;1-当前位置;2-文件尾
f.close() 关闭文件
| 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
在python中file对象是一个可迭代的对象,在python2中file对象不是一个生成器,而在python3中file对象是一个生成器,每一次进行.__next___方法会返回一行的内容。因此我们在对大文件的读取时直接使用file对象,而不是用file.readlines()直接将所有的内容读取,暂时保存到内存中,大文件这样做会让我们的内存崩溃。
练习1:
有一个小文和大文件,需要我们进行读取,并显示读取的时间,并分别显示文件的读取时间。
import time
import functools
def add_log(fun):
@functools.wraps(fun) # 不会改变原函数的属性;
def wrapper(*args,**kwargs):
start_time = time.time()
res = fun(*args,**kwargs)
end_time = time.time()
#time.ctime() 获取系统字符串时间
print("[%s] 函数名: %s 运行时间:%s 运行返回值结果: %s" % (time.ctime(),fun.__name__, end_time - start_time,res))
return wrapper
@add_log
def Open_file_way1(filename):
with open(filename) as file_it:
#file_it 是一个生成器,节省内存适用于大文件的读写
for line in file_it:
print(line)
@add_log
def Open_file_way2(filename):
with open(filename) as file_it:
#file_it.readlines()的返回值是一个列表,解释器会将文件的所有的
#内容以行为单位存储到列表里面,这样读取文件时间快,大文件这样做会引起内存崩溃.
for line in file_it.readlines():
print(line)
Open_file_way1('/mnt/passwd')
Open_file_way2('/mnt/passwd')
练习2、:
1. 生成一个大文件ips.txt,要求1200行, 每行随机为172.25.254.0/24段的ip
2. 读取ips.txt文件统计这个文件中ip出现频率排前10的ip;import random
def Creat_ips_file(filename):
ips = ['172.25.254.' + str(i) for i in range(1, 255)]
with open(filename, 'w') as file_ip:
for count in range(12000):
file_ip.write(random.sample(ips,1)[0]+'\n')
def Sorted_count_ip(filename, count=10):
ips_dict = dict()
with open(filename) as file_ip:
for IP in file_ip:
if IP in ips_dict:
ips_dict[IP] +=1
else :
ips_dict[IP] = 1
#ips_dict.items() 可以字典变为列表嵌套元组的数据结构,
#其中列表的每一个元素都是一个有key和其对应的value值组成的元组,
#我们使用每个元组的[1]个元素为依据进行排序return sorted_ip
sorted_ip = sorted(ips_dict.items(),key=lambda x : x[1] , reverse=True)[:count]
return sorted_ip
Creat_ips_file('IP_FILE.txt')
for IP in Sorted_count_ip('IP_FILE.txt',10):
print(IP[0]) 练习3、:
使用from collections import Counter 模块对练习而得代码进行改进
def Use_module_Sorted(filename):
with open(filename) as file_it:
sorted_ip = Counter(file_it)
return sorted_ip.most_common(10)
Creat_ips_file('IP_FILE.txt')
for IP in Use_module_Sorted('IP_FILE.txt'):
print(IP[0])
练习4、:
写一个函数,实现文件的复制功能(文件复制的本质就是对文件的读写操作)
def copy1(sourcefile, destfile):
# 要点: python2.7及以后,with支持对多个文件的上下文管理;
with open(sourcefile) as file_it1, open(destfile,'w+') as file_it2:
for line in file_it1:
file_it2.write(line)
print("拷贝 %s 为 %s 成功" %(sourcefile,destfile))
三、os模块操作文件
在python中我们使用os模块可以对文件进行非常丰富的操作,
os.getcwd() # 方法用于返回当前工作目录。 类似于pwd命令
os.listdir('/mnt/') #列出指定文件夹下的所有文件,并将所有的文件(或目录)的名字以列表形式返回 类似于指令ls
os.mknod(filename]) #创建一个空文件 类似于touch filename 指令
os.remove(path) #用于移除指定路径的指定文件 #path -- 要移除的文件路径
os.mkdir(path[,mode]) #创建目录 path -- 要创建的目录 , mode 目录的权限 类似于mkdir
os.makedirs(path[,mode]) #创建目录 path -- 要创建的目录 mode 目录的权限 类似于 mkdir -p
os.removedirs(path) #方法用于递归删除目录
os.path.isfile(filename) #判断目标是不是一个文件 filename -- 文件名 如果是文件 返回True 若果不是文件 返回False
os.path.isabs(path) #判断路径是否是绝对经 是返回True 不是返回False
os.path.exists(path) #判断文件或目录是否存在
os.path.split(path) #以元组形式返回文件的路径和文件名
os.path.splitext(path) #以元组形式返回文件的文件名和文件扩展名
os.path.basename(path) #获取文件名
os.path.dirname(path) #获取文件的目录名
os.rename(filename1, filename2) #将文件的名字由filename1改为filename2
os.path.sep #当前系统环境的路径分割符
练习1、:
将制定文件夹下的任意文件的后缀修改为指定的后缀
例:
创建文件/mnt/hello{1..8}.jpg /mnt/westos{a..f}.py
修改所有的.jpg结尾的文件为/mnt/hello{1..8}.png;
import os
def Creat_file(dirname):
filename_jpg = ['hello'+str(num)+'.jpg' for num in range(1,9)]
filename_py = ['westos'+chr(num)+ '.py' for num in range(ord('a'),ord('g')+1)]
for filename in filename_jpg+filename_py:
#判断文件是否存在,创建一个新的文件,使用绝对路径
if not os.path.exists(os.path.abspath(dirname)+os.path.sep+filename):
os.mknod(os.path.abspath(dirname)+os.path.sep+filename)
print("%s文件创建成功!" % (os.path.abspath(dirname)+os.path.sep+filename))
else :
print("%s文件已经存在!" % (os.path.abspath(dirname)+os.path.sep+filename))
def change_suffix(dirname,old_suffix,new_suffix):
if '.' not in old_suffix:
old_suffix = "." + old_suffix
if '.' not in new_suffix:
new_suffix = '.' + new_suffix
if os.path.exists(dirname): #判断指定的目录是否存在
#将所有后缀名符合要求的文件名仿造一个列表中
old_filename_list = [filename for filename in os.listdir(dirname) if filename.endswith(old_suffix)]
if old_filename_list: #判断需要修改的文件存不存在
#os.path.splitext()将文件的文件名和后缀名分开存储在一个元组中
new_filename_list = [os.path.splitext(filename)[0]+new_suffix for filename in old_filename_list ]
for num in range(len(new_filename_list)):
os.rename(os.path.abspath(dirname)+os.path.sep+old_filename_list[num],os.path.abspath(dirname)+os.path.sep+new_filename_list[num])
print("%s重命名为%s成功!" % (old_filename_list[num], new_filename_list[num]))
else :
print('不存在后缀为%s的文件'%(old_suffix))
else:
print("%s目录不存在" % (dirname))
Creat_file('/mnt')
change_suffix('/mnt','.jpg','.png')
练习2、:使用sys模块将上面的change_suffix函数变成可以在命令行执行的命令。
1、代码:
import os
import sys
def chage_suffix(dirname,old_suffix,new_suffix):
if '.' not in old_suffix:
old_suffix = "." + old_suffix
if '.' not in new_suffix:
new_suffix = '.' + new_suffix
if os.path.exists(dirname): #判断指定的目录是否存在
#将所有后缀名符合要求的文件名仿造一个列表中
old_filename_list = [filename for filename in os.listdir(dirname) if filename.endswith(old_suffix)]
if old_filename_list: #判断需要修改的文件存不存在
#os.path.splitext()将文件的文件名和后缀名分开存储在一个元组中
new_filename_list = [os.path.splitext(filename)[0]+new_suffix for filename in old_filename_list ]
for num in range(len(new_filename_list)):
os.rename(os.path.abspath(dirname)+os.path.sep+old_filename_list[num],os.path.abspath(dirname)+os.path.sep+new_filename_list[num])
print("%s重命名为%s成功!" % (old_filename_list[num], new_filename_list[num]))
else :
print('不存在后缀为%s的文件'%(old_suffix))
else:
print("%s目录不存在" % (dirname))
def main():
#sys.argv
#是用来获取命令行输入的参数的(参数和参数之间空格区分), sys.argv[0]
#表示代码本身文件路径, 所以从参数1开始, 表示获取的参数了
if len(sys.argv) == 4:
chage_suffix(sys.argv[1],sys.argv[2],sys.argv[3])
else:
print('Usage:chage_suffix dirname old_suffix,new_suffix')
main()
2、在终端中修改文件的权限。
在终端中找到上面代码的.py文件,对所有者,用户组,以及其他人 增加执行权限。

3、对该文件生成软连接到/usr/bin/ 目录下:


练习3、:使用optparse模块将上面的change_suffix生成标准的、符合Linux规范的命令行说明
def main():
parser = optparse.OptionParser()
parser.add_option('-d', '--dirname', dest='dirname',type='str')
parser.add_option('-o', '--oldsuffix', dest='oldsuffix',type='str')
parser.add_option('-n', '--newsuffix', dest='newsuffix',type='str')
(options, args) = parser.parse_args()
print(options.dirname,options.oldsuffix,options.newsuffix)
# options是一个字典, key=dirname, oldsuffix, newsuffix
chage_suffix(options.dirname,options.oldsuffix,options.newsuffix)
main()
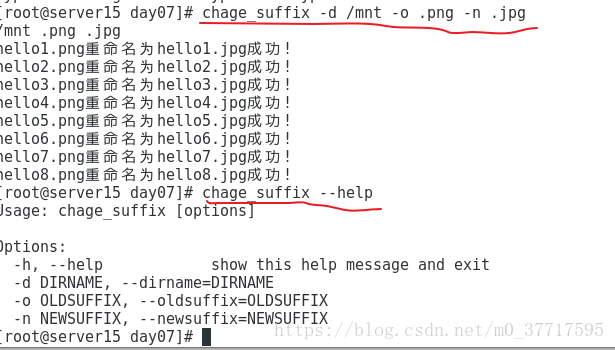
这样我们可以使用标准的参数输入方式和--help 命令