HA (High Available)高可用集群—通过fence设备解决集群节点之间争抢资源的现象
一、 HA简介
HA(High Available)高可用集群,是减少服务中断时间为目的的服务器集群技术。是保证业务连续性的有效解决方案。集群,简单的来说就是一组计算机。一般有两个或者两个以上的计算机组成,这些组成集群的计算机被称为节点。
其中由两个节点组成的集群被称为双机热备,即使用两台服务器互相备份,当其中一台服务器出现问题时,另一台服务器马上接管服务,来保护用户的业务程序对外不间断提供的服务,当然集群系统更可以支持两个以上的节点,提供比双机热备更多、更高级的功能,把因软件/硬件/人为造成的故障对业务的影响降低到最小程度。
二、集群脑裂
1、什么是脑裂
脑裂(split-brain)就是“大脑分裂”,也就是本来一个“大脑”被拆分了两个或多个“大脑”,我们都知道,如果一个人有多个大脑,并且相互独立的话,那么会导致人体“手舞足蹈”,“不听使唤”。
脑裂通常会出现在集群环境中,集群环境有一个统一的特点,就是它们有一个大脑,即集群中的Master/Leader节点。
2、集群中的脑裂场景
对于一个集群,想要提高这个集群的可用性,通常会采用多机房部署,比如现在有一个由6台Server所组成的一个集群,部署在了两个机房:
正常情况下,此集群只会有一个Leader,那么如果机房之间的网络断了之后,两个机房内的Server还是可以相互通信的,如果不考虑过半机制,那么就会出现每个机房内部都将选出一个Leader。
这就相当于原本一个集群,被分成了两个集群,出现了两个“大脑”,这就是脑裂。
对于这种情况,我们也可以看出来,原本应该是统一的一个集群对外提供服务的,现在变成了两个集群同时对外提供服务,争抢资源。还会出现一种问题:如果过了一会,断了的网络突然联通了,出现俩master怎么办?那么此时就会出现问题了,两个集群刚刚都对外提供服务了,数据该怎么合并,数据冲突怎么解决等等问题。
3、解决方法
在集群中为了防止服务器出现“脑裂”的现象,集群中一般会添加Fence设备,有的是使用服务器本身的的硬件接口称为内部Fence,有的则是外部电源设备称为外部Fence,当一台服务出现问题响应超时的时候,Fence设备会对服务器直接发出硬件管理指令,将服务器重启或关机,并向其他节点发出信号接管服务。
在红帽系统中我们通过luci和ricci来配置管理集群,其中luci安装在一台独立的计算机上或者节点上,luci只是用来通过web访问来快速的配置管理集群的,它的存在与否并不影响集群。ricci是安装在每个节点上,它是luci与集群中节点通信的桥梁。
集群中luci的作用:
luci是用来配置和管理集群,监听在8084上
集群中ricci的作用:
ricci是安装在每个后端的每个节点上的,luci管理集群上的各个节点就是通过和节点上的ricci进行通信,ricci监听在11111上
集群中fence的原理和作用:
当意外原因导致主机异常或者宕机时,备机会首先调用FENCE设备,然后通过FENCE设备将异常主机重启或者从网络隔离,当FENCE操作成功执行后,返回信息给备机,备机在接到FENCE成功的信息后,开始接管主机的服务和资源。这样通过FENCE设备,将异常节点占据的资源进行了释放,保证了资源和服务始终运行在一个节点上。并且有效的阻止了“脑裂"的发生。
二、基本环境的搭建
下面的实验使用的是rhel6系列(rhel6.5)的虚拟机
1、基本环境搭建说明
(1)使用的操作系统:均是rhel6.5
(2)准备3台主机:
主机 :172.25.58.250 作为fence设备,前面暂时不用
server1: 172.25.58.1 下载ricci,luci(为了提供Conga配置用户界面),作主节点
server2:172.25.58.2 下载ricci,作备节点
(3)关闭server1和server2虚拟机的firewalld 和selinux
[root@server1 ~]# service iptables stop
[root@server1 ~]# chkconfig iptables off
[root@server1 ~]# service iptables status
iptables: Firewall is not running.
[root@server1 ~]# getenforce
Disabled
2、FENCE搭建过程详解
为设备配置yum源
(1)给server1和server2均配置一个高可用的yum源rhel6.5版本。
先挂载镜像到rhel6.5的共享目录下,然后在server1 和server2上进行配置
真机:
[root@foundation58 ~]# mount /home/kiosk/rhel-server-6.5-x86_64-dvd.iso /var/www/html/rhel6.5/
mount: /dev/loop2 is write-protected, mounting read-only
[root@foundation58 ~]# cd /var/www/html/rhel6.5/
[root@foundation58 rhel6.5]# ls
EFI Packages RELEASE-NOTES-pa-IN.html
EULA README RELEASE-NOTES-pt-BR.html
EULA_de RELEASE-NOTES-as-IN.html RELEASE-NOTES-ru-RU.html
EULA_en RELEASE-NOTES-bn-IN.html RELEASE-NOTES-si-LK.html
EULA_es RELEASE-NOTES-de-DE.html RELEASE-NOTES-ta-IN.html
EULA_fr RELEASE-NOTES-en-US.html RELEASE-NOTES-te-IN.html
EULA_it RELEASE-NOTES-es-ES.html RELEASE-NOTES-zh-CN.html
EULA_ja RELEASE-NOTES-fr-FR.html RELEASE-NOTES-zh-TW.html
EULA_ko RELEASE-NOTES-gu-IN.html repodata
EULA_pt RELEASE-NOTES-hi-IN.html ResilientStorage
EULA_zh RELEASE-NOTES-it-IT.html RPM-GPG-KEY-redhat-beta
GPL RELEASE-NOTES-ja-JP.html RPM-GPG-KEY-redhat-release
HighAvailability RELEASE-NOTES-kn-IN.html ScalableFileSystem
images RELEASE-NOTES-ko-KR.html Server
isolinux RELEASE-NOTES-ml-IN.html TRANS.TBL
LoadBalancer RELEASE-NOTES-mr-IN.html
media.repo RELEASE-NOTES-or-IN.html
这里使用到了 : HighAvailability LoadBalancer ResilientStorage ScalableFileSystem
server1:
[root@server1 yum.repos.d]# ls
rhel-source.repo
[root@server1 yum.repos.d]# cat rhel-source.repo
[HighAvailability]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=http://172.25.58.250/rhel6.5/HighAvailability
enabled=1
gpgcheck=0
[LoadBalancer]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=http://172.25.58.250/rhel6.5/LoadBalancer
enabled=1
gpgcheck=0
[ResilientStorage]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=http://172.25.58.250/rhel6.5/ResilientStorage
enabled=1
gpgcheck=0
[ScalableFileSystem]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=http://172.25.58.250/rhel6.5/ScalableFileSystem
enabled=1
gpgcheck=0
[rhel6.5]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=http://172.25.58.250/rhel6.5
enabled=1
gpgcheck=0然后将该文件复制server2,即可。
(2)、安装软件
server1安装集群管理结点服务ricci,集群图形化管理工具服务luci
server1安装ricci和luci图形管理器,启动服务,设置开机自启
yum install -y ricci luci
passwd ricci ##为ricci用户用户设置密码
/etc/init.d/ricci start
/etc/init.d/luci start
chkconfig ricci on 开机自启
chkconfig luci on
从红帽企业版 Linux 6.1 开始,在任意节点中使用 ricci 推广更新的集群配置时要求输入密码
所以在安装完成ricci后需要修改ricci用户的密码,这个是后面节点设置的密码
安装完之后可以看到/etc/passwd文件中自动生成了一个ricci用户查看两个服务的端口:
[root@server1 yum.repos.d]# netstat -antlp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:8084 0.0.0.0:* LISTEN 1384/python
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 894/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 970/master
tcp 0 0 172.25.58.1:22 172.25.58.250:54438 ESTABLISHED 1071/sshd
tcp 0 0 :::22 :::* LISTEN 894/sshd
tcp 0 0 ::1:25 :::* LISTEN 970/master
tcp 0 0 :::11111 :::* LISTEN 1303/ricci给server2安装集群管理结点服务
server2上安装ricci,启动服务,设置开机自启,修改ricci用户密码
yum install ricci -y
passwd ricci
/etc/init.d/ricci start
chkconfig ricci on
(3)、此时在浏览器进行测试:


(4)、此时进行创建集群:
点击集群管理(manage cluster),选择create,创建集群

设置集群的基本信息,添加节点:


创建时两台虚拟机都会重启,如果之前没有设置服务开机启动这个时候就会报错,重启后要在虚拟机中手动打开服务创建的过程才会继续:


可以看到集群创建完成,节点添加成功:

(5)、在server1上面和server2上面查看
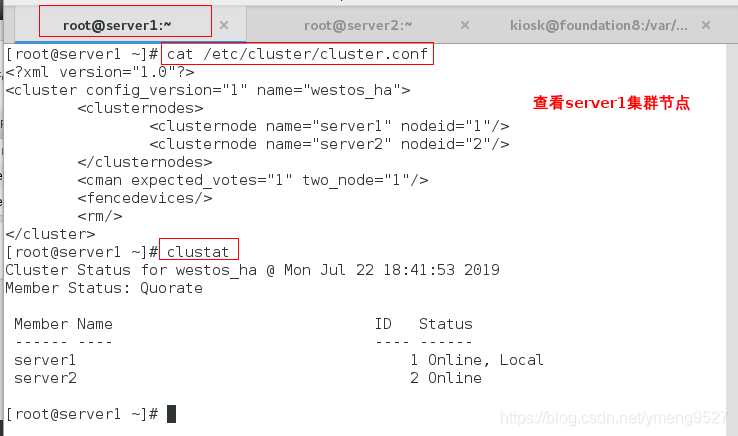
到此为止,基本的实验环境搭建完毕,接下来说明RHCS的高可用体现在哪里
可以看到ricci运行的端口是11111
注意:删除集群时要先删除节点,节点删除后集群会自动消失

如何通过fence设备解决集群节点之间争抢资源的现象?
目前的RHCS高可用集群比之前学的lvs调度器性能更好,功能也会更多,前端后端均有
在这里我们可以把每个集群节点当作一个调度器,实际上功能不止调度器一个
一般情况下集群节点中有主有备,正常情况下会有一个正常工作(调度器正常),但是当调度器坏了就完蛋了
因此要做到:
一台调度器坏了,调度器1就去通知调度器2接管它的工作,正常情况下调度器1和调度器2会一直通信
当2收不到1的消息的时候,就说明1坏了,2马上接替1的工作
但是当1和2之间的心跳检测出现问题的时候,也就是有一个卡死了,其实两个都能正常工作,这个时候两个集群都能工作
因此1和2都会去为客户端服务,会去争抢资源,因此需要fence这样一个物理设备抑制争抢资源
当争抢资源的时候,1会去通过fence设备强制重启2(或者2重启1)
两个集群可以互相强制重启,但是实际当中集群也是有主有备的
现在server1是一个集群,server2是一个集群,真机是一个fence设备(保安)
通过fence这个物理设备将集群连接在一起,保证时刻只有一个集群正常工作
一旦出现争抢资源的现象,主的集群就会通过fence强制重启备的集群,从而使主集群正常工作
2、配置fence设备:
(1)、在集群1上面:
/etc/init.d/ricci status查看集群节点管理工具
/etc/init.d/luci status查看集群图形化管理工具(开启这个浏览器里面才能管理集群)
(一般情况下这两个服务是分开做的)
clustat查看集群状态
cat /etc/cluster/cluster.conf查看集群的配置文件
(2)在集群2上面:
/etc/init.d/ricci status查看集群节点的服务是否开启
clustat
cat /etc/cluster/cluster.conf查看集群是否建立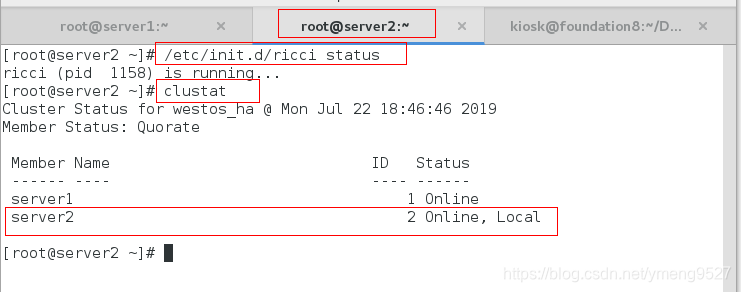
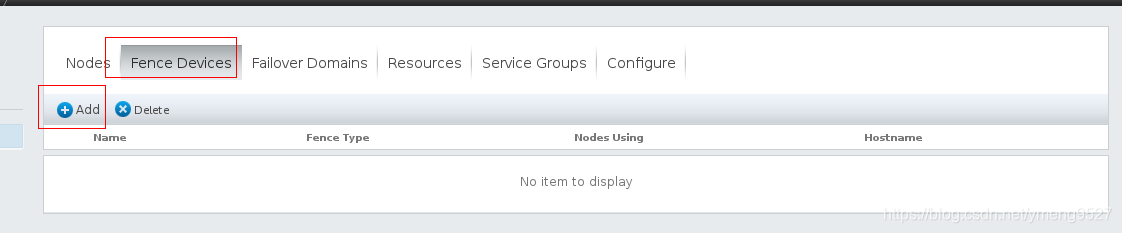
(3)、在浏览器中添加:fence设备
登录集群管理系统,查看创建的两个集群server1和server2
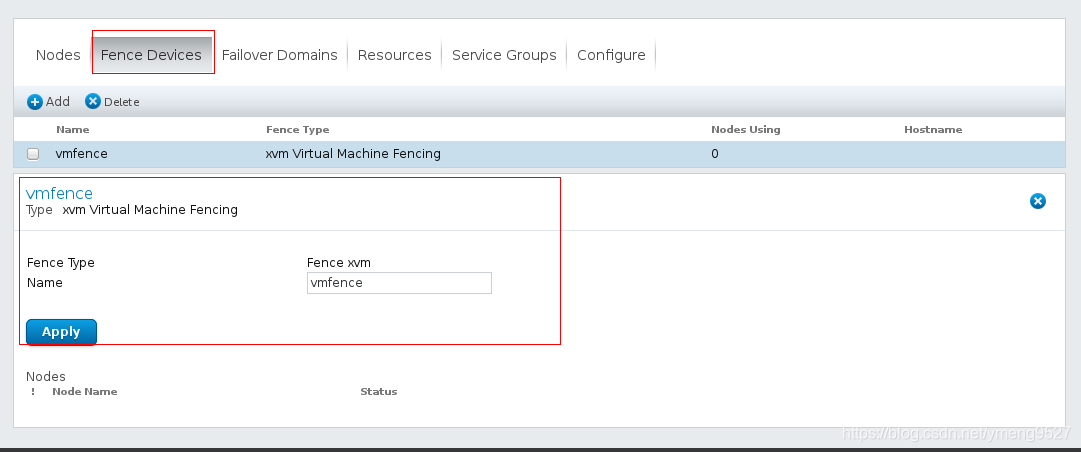
添加fence设备(fence virt)--->vmfence(名字随便起)
fence只是中间一个通道,server1和server2都是连接在fence这个物理设备上,通过一个集群去拔另外一个集群的电,防止争抢资源
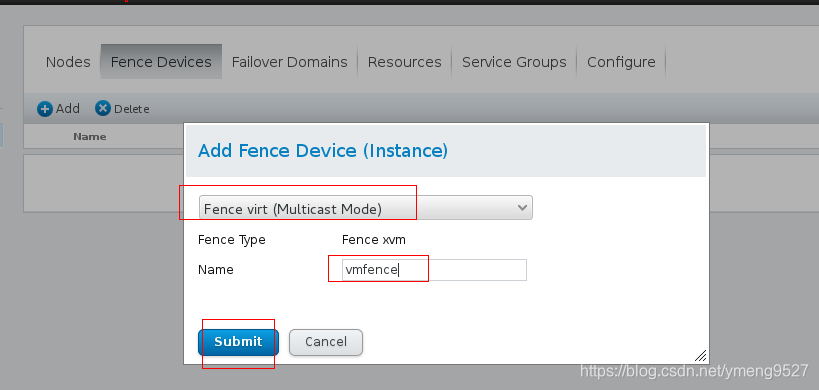
选择fence的类型,起名字,见名知意及可
选择多播模式,设置fence设备的名字为vmfence
3、在物理机配置fence服务:
- yum search fence
- yum install 三个东西 -y
- fence_virtd -c初始化fence设备管理 -全回车,注意网卡是br0(因为两个集群是在虚拟机上面做的,虚拟网卡是通过真实的网卡br0来工作)
- mkdir /etc/cluster 在这个目录下生成fence管理的key,然后传给集群
- 生成fence管理的key:cd /etc/cluster
- dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128(密码太小不安全) count=1(只生成一个key)
- 注意先不要开启fence设备,将key给两个集群各传一个key,保证两个集群得到的key一样,这样fence才能同时管理两个集群
- scp /etc/cluster/fence_xvm.key [email protected]:/etc/cluster
- scp /etc/cluster/fence_xvm.key [email protected]:/etc/cluster

在指定目录下面生成fence的key,并且给两个集群各发送过去一个
注意发送key的时候fence不能开启,否则server1和server2接收到的key不一样
创建一个目录/etc/cluster,生成的key将会保存在这个目录中
编辑完之后如果没有生成密钥文件,可以手动生成一个

4、在server1和2上进行查看是否传输过来:
cd /etc/cluster
ls查看key文件是否过来
cat cluster.conf可以看到集群的配置文件当中添加了fence

在集群2上面查看
cd /etc/cluster
cat cluster.conf 可以看到集群的配置文件当中添加了fence

5、绑定节点——在浏览器的控制台里面设置
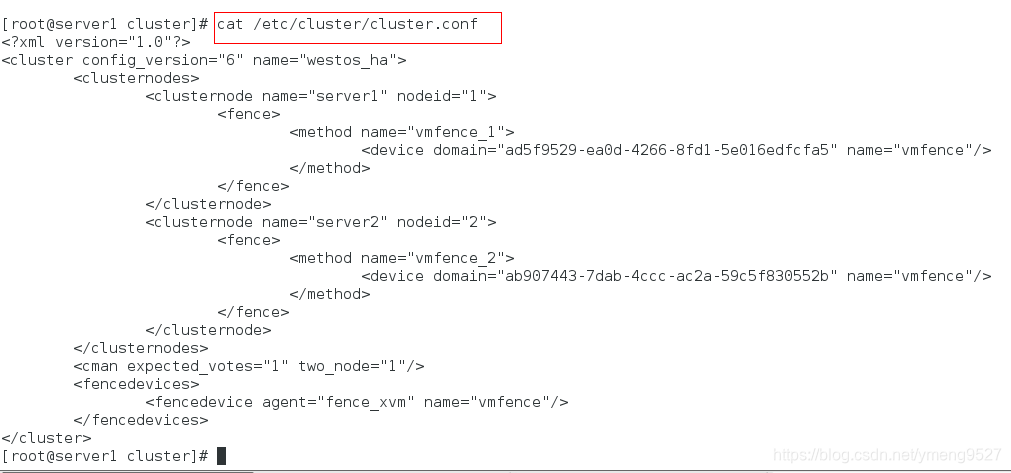
给server1和server2集群添加fence,vmfence_1(名字) uuid(server1主机的),vmfence_2(名字) uuid(server2主机的)
因为两个集群的ip可能会一样,有可能会一次关闭两个集群,不安全
应该把每个集群唯一的uuid写在fence设备上面
在真机里面virt-manager把两个uuid查看出来




在真机里面查看server1虚拟机的uuid:


server2进行同样的操作~~
绑定完成后,可以看到fence配置文件内容如下(查看两个集群节点是否关联在fence设备上,在两个集群节点的集群配置文件里面看):
6、测试:
在server1和server2上添加解析后
然后在物理机上打开fence设备:
systemctl status fence_virtd.service查看fence服务是否开启
systemctl start fence_virtd.servcie开启fence服务
netstat -antlupe | grep 1229(fence服务使用的端口)
此时假若两个机房中的通信出现问题,要将:fence干掉server2,可以看到server2重启:
例:打开server2集群 在server1上面输入:fence_node server2
可以看到集群1把集群2强制重启了
![]()
此时server的状态是:offline挂掉的,此时server就开始接手master的工作
[root@server1 ~]# clustat
Cluster Status for cluster @ Sat Feb 15 19:58:47 2020
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
server1 1 Online, Local
server2 2 Offline
